
Harness Engineering: Why the Frame Matters More Than the Model
It took me three iterations to implement a straightforward feature across two repositories. Not because the model was inadequate — same model, same task. The

It took me three iterations to implement a straightforward feature across two repositories. Not because the model was inadequate — same model, same task. The problem was that I had no harness. I was the human clipboard between two codebases that knew nothing about each other, the manual coordinator for two agents without shared structure, and eventually the planner who explicitly decomposed the work after two failed attempts — at which point it worked on the first try.
That was not intuitive. But it was reproducible. And it maps to a data pattern I keep finding in the research.
Before getting into what a harness actually is, the measurement results are worth a careful look — because they are more contradictory than most coverage suggests.
The METR study1 observed 16 experienced open-source developers over 246 real-world tasks in their own projects. With AI assistance, they took 19% longer on average. What makes this remarkable is not just the slowdown but the misperception: developers expected a 24% speedup beforehand; even after the experiment, they believed AI had accelerated them by 20%.1
The study covered typical AI-assisted workflows — primarily Cursor Pro with Claude 3.5/3.7 Sonnet, then-current top models — but not purpose-built agentic harnesses.1
DORA 20242 shows a similar pattern in organization-wide survey data: +25 percentage points of AI adoption correlates with -1.5% throughput and -7.2% stability. At the same time, individual metrics show positive effects — +2.1% productivity, +3.4% code quality.2 The paradox is real: individual gains, organizational losses.
Faros AI observed over 10,000 developers:3 +21% completed tasks, +98% merged PRs, but +91% review time. At the organizational level, the connection to delivery metrics remained weak.3 More activity in the development system, but little clear gain in delivery outcomes.
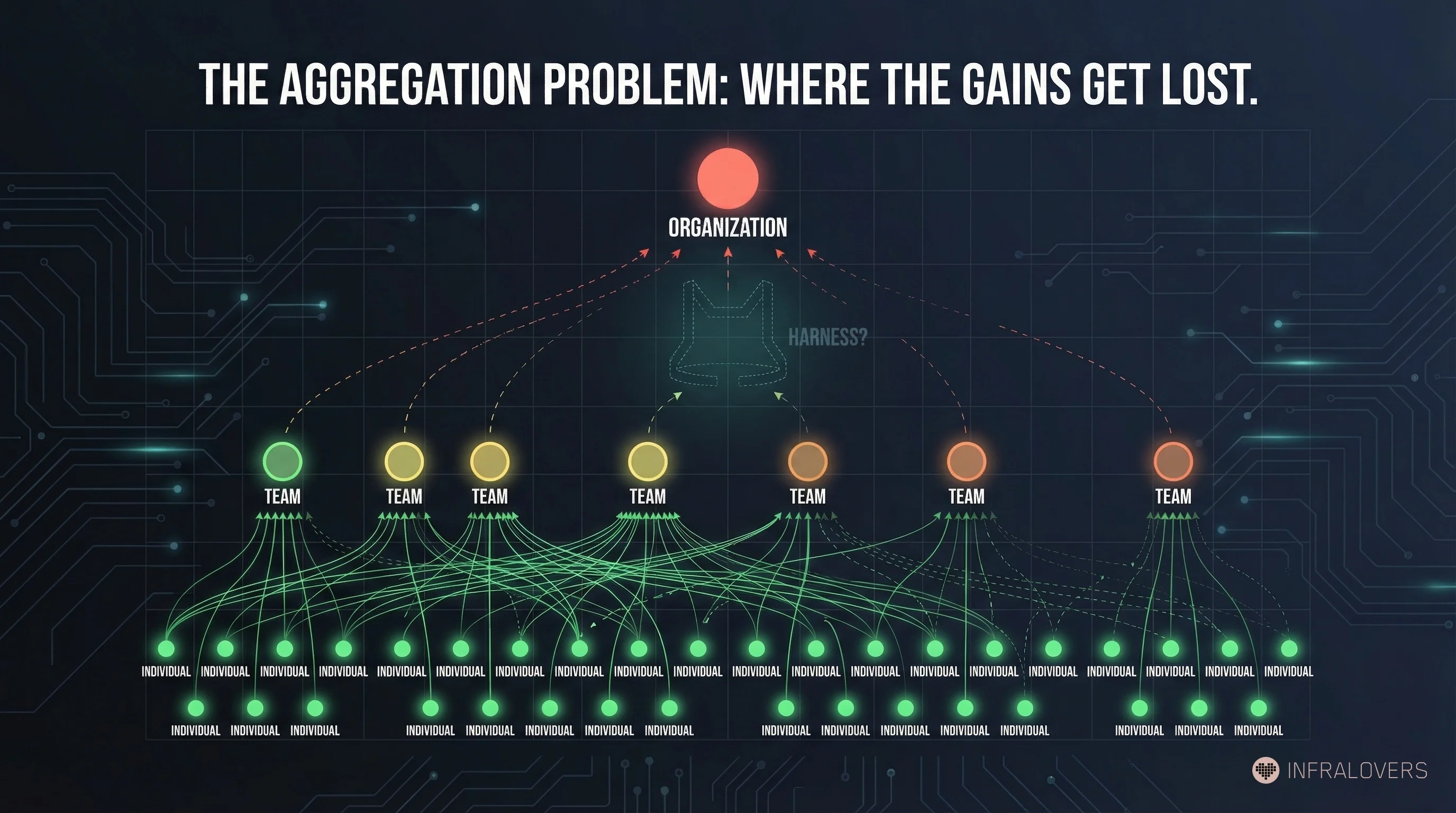
These studies form a baseline: what happens when AI tools are deployed, but the surrounding organizational structure is not thought through. METR examines typical AI-assisted developer workflows without isolating the harness factor. DORA and Faros AI measure AI usage at individual and organizational levels without controlling for it either. Together, they show what the floor looks like.
The term comes from software testing — and the parallel is not accidental. Inngest argues that a harness describes the same concept across every engineering discipline.4 InSpec, Test Kitchen, every compliance framework has a testing harness: the structure that surrounds the tool and lets it work reliably.5 The tool is capable. Without a harness, it still runs into walls.
Ethan Mollick extended the framework to Models-Apps-Harnesses in February 2026.6 A harness takes the raw capability of the model and turns it into useful work — the way a horse harness translates the animal's strength into traction.6 Apps give the model a surface. Harnesses give it an organizational structure.
The distinction is concrete: Cursor is an app — a surface. The Planner-Worker mechanism — augmented with verification and completion logic — that Cursor uses internally for autonomous coding sessions is a harness.7 Same model, dramatically different results.
The strongest empirical argument comes from LangChain. In its OPENDEV / Deep Agents work,8 LangChain shows what harness changes alone produce, without switching models: Terminal Bench 2.0 performance from 52.8% to 66.5% — 13.7 percentage points through better task structure, better verification, better orchestration.8 No new model. No better prompts. A different frame.
Before going further, the plausible opposing hypothesis deserves a fair hearing.
One could argue that harnesses only help where weak models or poor prompts are the actual bottleneck. Better models might make the coordination overhead unnecessary. GPT-5 or Claude 4 would then be not just more capable — they would be more reliable, and more reliable agents need less external structure.
That is not a bad argument. But it does not hold completely. First, the OPENDEV results8 show harness gains on the same current models that perform worse without structure in the METR studies.1 Second, Google Research9 evaluated 180 configurations, 5 architectures, and 4 benchmarks and found that multi-agent coordination improves performance on parallelizable tasks by up to 80.8% — but degrades it on sequential tasks by up to 70%.9 That is not a model property; that is a structural property. Third, Armin Ronacher frames the counter-risk well: "AI agents are amazing and a huge productivity boost. They are also massive slop machines if you turn off your brain and let go completely."10 More model capacity without a harness produces more slop, not less.
The question is not harness versus no harness. The question is which harness for which task.
The productivity data raises an obvious question: if the model alone is not enough — what are the organizations actually delivering results building? A closer look at the architectures reveals significant variation, and precision matters here.
Cursor (Wilson Lin, January 2026)7 built a genuine multi-agent system: Root Planner with no direct code execution, recursive Sub-Planners, Workers on isolated repo copies, a handback mechanism to the Planner.7 The system built a web browser from scratch: over a million lines of code, 1,000 files, one week of runtime.7
Cursor CEO Michael Truell claims the system found a potentially novel solution to Problem 6 of FirstProof.1112 Truell's exact wording: "We believe Cursor discovered a novel solution." No external validation of that claim exists. This is an attributed claim, not a confirmed fact.
Anthropic Agent Teams13 is a productive harness for Claude Code: a Lead agent coordinates, Teammates work in their own context windows, peer-to-peer messaging, file-based task board with dependency logic. Nicolas Carlini14 had 16 agents write a C compiler in Rust: ~100,000 LoC, ~$20,000 cost, 99% GCC Torture Test pass rate.14 This is a multi-agent system, structurally similar to Cursor.
DeepMind Aletheia15 is structurally different: not a multi-agent system, but an iterative Generate-Verify-Revise loop on a single model. Gemini 3 Deep Think generates, verifies, and revises in repeated passes. Aletheia solved 6 of 10 FirstProof problems.15 That is impressive — and shows that the verifier feedback loop itself, even without multi-agent coordination, delivers substantial performance gains.
OpenAI Codex16 describes itself through an agent loop and harness with parallel-running sandboxes. Coordinated multi-agent workflows are possible in the product, but this is not the same explicit Planner-Worker approach that Cursor prominently describes.16
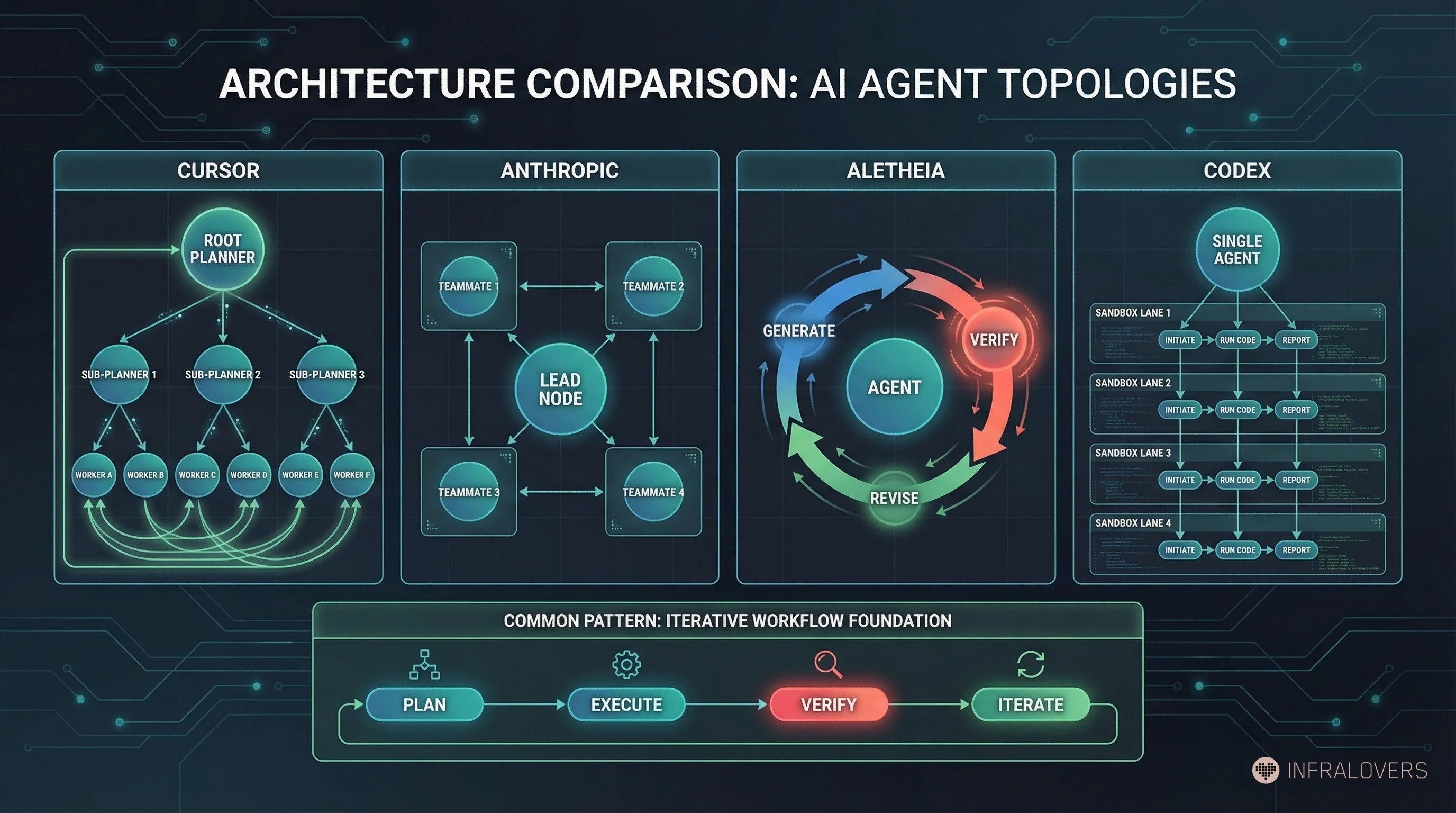
What these systems have in common is not necessarily multi-agent coordination. The shared pattern is more accurately described as: planning, execution, verification, and iteration.
Wang et al.17 showed that multi-agent systems can in many cases be compressed into equivalent single-agent systems with extended skills — with 53.7% token savings at equal accuracy.17 The advantage of multi-agent is not the plurality of agents. It is the organizational principle behind them.
This pattern is also not new. MetaGPT (2023)18 and ChatDev (2024)19 explored formalized role structures for AI agents. Hierarchical Task Networks from the 1990s20 formalized task decomposition and verification. What is happening now is industrialized convergence on an older pattern — with models that make it practically viable for the first time.
This is where I need to slow the enthusiasm.
The harness pattern works well where verification is fast, objective, and scalable. It breaks down where feedback is fuzzy, slow, or context-dependent.
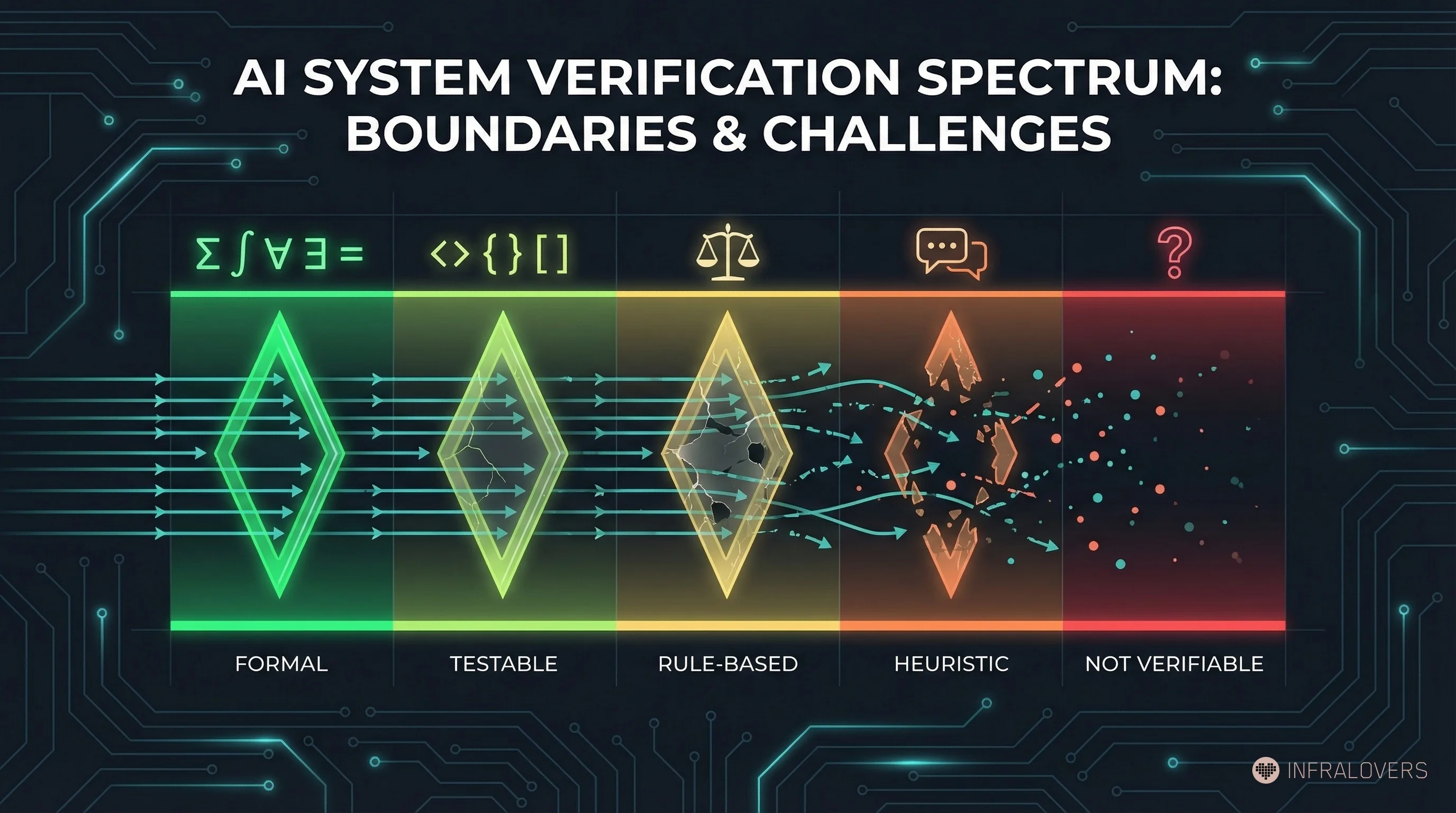
A taxonomy of verifiability levels:
Level 1 — Formal (mathematics, formal proofs): Verification is exact and automatable. AlphaProof, Aletheia, FirstProof tasks fall here. The judge can decide reliably.
Level 2 — Testable (code, CI/CD pipelines, infrastructure tests): Verification through automated tests in seconds to minutes. This is the strength of OPENDEV and Cursor for coding tasks. Most software engineering workflows live here.
Level 3 — Rule-based (legal citations, medical coding, compliance): Verification through defined rules is possible but slower and more context-dependent. Harnesses work here but need human review steps.
Level 4 — Heuristic (customer service, research, content quality): Verification through evaluation models or human feedback. Feedback arrives slowly and is less reliable. The harness pattern delivers less clear gains here.
Level 5 — Non-verifiable (creative strategy, ethical decisions, political judgment): No objective judge is possible. The pattern breaks down fundamentally.
The most impressive results — LangChain OPENDEV,8 Cursor's browser build,7 Aletheia's proofs15 — sit at Levels 1-2. Extrapolating to Levels 4-5 is a hypothesis, not a proven thesis.
A position paper from the Deer Valley workshop (February 2026) puts it directly:21 "Organizations are constrained by human and systems-level problems. We remain skeptical of the promise of any technology to improve organizational performance without first addressing human and systems-level constraints."21 The constraints at Levels 4-5 lie in the nature of the task, not in the harness.
What I find most telling about this pattern: we already know it. Not from AI systems — from ourselves.
When Infrastructure as Code arrived, we did not eliminate server boundaries. We built Terraform, Ansible, Kubernetes — coordination across boundaries. When microservices became too complex, we did not refactor everything back into monoliths. We built service meshes, API gateways, and distributed tracing. The infrastructure stayed distributed. The coordination became explicit.
The harness pattern is the same intuition applied to agents: do not remove the boundaries. Make the coordination explicit.
Whether Conway's Law applies to agents — whether the communication structure of the harness mirrors the structure of the produced code — is an interesting hypothesis. The evidence for it is thin. I see the pattern in my own experiments, but one observer with two repos is not statistical proof. That stays a question, not a thesis.
What I can say with more confidence: the harness is not an optimization trick. It is — at least in the cases observed so far — the baseline condition for agents to work reliably. Without structure, you do not have bad agents. You have random number generators with very good manners.
Three questions for the next team meeting:
1. What verifiability level do your tasks sit at? Coding tasks with tests fall at Level 2. Research tasks with subjective quality assessment sit at Level 4. Building a harness for Level 2 tasks makes sense. Applying that same harness to Level 4 tasks and expecting similar results is an untested extrapolation.
2. Do you have an explicit planner — or are you hoping for emergence? The planner does not have to be a separate model. It can be a prompt, a human, a spec document. But something needs to decompose the work before workers start. Emergent coordination without explicit structure produces the METR pattern: lots of activity, little progress.
3. How long is your feedback loop? OPENDEV wins because Terminal Bench 2.0 delivers feedback in seconds.8 If your feedback loop takes hours or days, the harness pattern breaks under real conditions. The first step then is not building the harness — it is shortening the feedback loop.
The answer to poor agent performance is rarely a better model and almost never fewer repositories. The question is: what is the verifiability of the task — and what organizational structure are you giving your agents?
This post is part of a series on AI and software architecture. Previous parts cover the Five Stages of AI Development, Dark Factory Architecture, the Dark Factory Gap, and Conway's AI Inverse.
This post started as an English adaptation of the German draft, rebuilt from the same research foundation rather than translated. The core argument emerged from a real experiment: three iterations across two repos, one structural insight. That experience was then tested against available empirical data: METR, DORA 2024, Faros AI, LangChain OPENDEV.
The four architecture descriptions (Cursor, Anthropic, DeepMind, OpenAI) were manually verified against primary sources — and deliberately differentiated: Cursor and Anthropic are multi-agent systems; Aletheia and Codex are not. The Cursor math claim is explicitly labeled as an attributed claim because no external validation exists. The verifiability taxonomy is my own categorization, not a cited source.
Produced with Claude Opus 4.6. Research sources verified via arXiv and primary sources. Cursor architecture details cross-checked against Wilson Lin's blog post. I describe the full workflow in AI-Assisted Knowledge Work: How I Am Rebuilding My Research and Writing Process.
METR (2025). Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity. arXiv:2507.09089. arxiv.org/abs/2507.09089 ↩︎ ↩︎ ↩︎ ↩︎
Google Cloud (2024). DORA 2024 State of DevOps Report. dora.dev/research/2024/ ↩︎ ↩︎
Faros AI (2025). Developer productivity with AI: What 10,000 developers tell us. Faros AI Research. (Cited from secondary reports; primary publication at faros.ai) ↩︎ ↩︎
Inngest (2026). Your Agent Needs a Harness, Not a Framework. inngest.com/blog. inngest.com/blog/your-agent-needs-a-harness-not-a-framework ↩︎
Böckeler, Birgitta (2026). Harness Engineering. martinfowler.com. martinfowler.com/articles/exploring-gen-ai/harness-engineering.html ↩︎
Mollick, Ethan (2026). A Guide to Which AI to Use in the Agentic Era. One Useful Thing, February 17, 2026. oneusefulthing.org/p/a-guide-to-which-ai-to-use-in-the ↩︎ ↩︎
Lin, Wilson (2026). Scaling long-running autonomous coding. Cursor Blog, January 2026. cursor.com/blog/scaling-agents ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
LangChain (2026). Improving Deep Agents with Harness Engineering. LangChain Blog. blog.langchain.com/improving-deep-agents-with-harness-engineering/ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Google Research (2025). Towards a Science of Scaling Agent Systems. arXiv:2512.08296. arxiv.org/abs/2512.08296 ↩︎ ↩︎
Ronacher, Armin (2026). Agent Psychosis. lucumr.pocoo.org, January 18, 2026. lucumr.pocoo.org/2026/1/18/agent-psychosis/ ↩︎
FirstProof Benchmark (2026). Formal mathematical problem set for AI evaluation. arXiv:2602.05192. arxiv.org/abs/2602.05192 ↩︎
Truell, Michael (2026). Attributed statement on X/Twitter. Exact wording: "We believe Cursor discovered a novel solution to Problem Six of the First Proof challenge." No external validation exists. x.com/mntruell/status/2028903020847841336 ↩︎
Anthropic (2026). Orchestrate teams of Claude Code sessions. Claude Code Documentation. code.claude.com/docs/en/agent-teams ↩︎
Carlini, Nicolas (2026). Building a C compiler in Rust with 16 Claude agents. Anthropic Engineering Blog. anthropic.com/engineering/building-c-compiler ↩︎ ↩︎
DeepMind (2026). Aletheia: Iterative reasoning with Generate-Verify-Revise loops. arXiv:2602.21201. arxiv.org/abs/2602.21201 ↩︎ ↩︎ ↩︎
OpenAI (2026). Unrolling the Codex agent loop. OpenAI Research. openai.com/index/unrolling-the-codex-agent-loop/ ↩︎ ↩︎
Wang et al. (2026). Compressing Multi-Agent Systems into Equivalent Single-Agent Systems. arXiv:2601.04748. arxiv.org/abs/2601.04748 ↩︎ ↩︎
Hong, Sirui et al. (2023). MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework. arXiv:2308.00352. arxiv.org/abs/2308.00352 ↩︎
Qian, Chen et al. (2024). ChatDev: Communicative Agents for Software Development. ACL 2024. arxiv.org/abs/2307.07924 ↩︎
Erol, Kutluhan et al. (1994). HTN Planning: Complexity and Expressivity. AAAI-94. (Hierarchical Task Networks as formal precursor to task decomposition patterns) ↩︎
Orosz, Gergely (2026). The Future of Software Engineering with AI: Six Predictions. The Pragmatic Engineer Newsletter, February 24, 2026. newsletter.pragmaticengineer.com/p/the-future-of-software-engineering-with-ai (Deer Valley Workshop, approx. February 10-11, 2026, organized by Martin Fowler / Thoughtworks) ↩︎ ↩︎
It took me three iterations to implement a straightforward feature across two repositories. Not because the model was inadequate — same model, same task. The
Securing Your Self-Hosted Automation: A Deep Dive into n8n and Vault/OpenBao Integration In the rapidly evolving landscape of workflow automation, self-hosting
Workflow automation used to be simple. Trigger fires, steps execute, data moves from A to B. Every branch is predetermined. Every outcome is scripted. The human
Learning & Development is a Satisfaction Driver—and a Competitive Advantage In many organizations, learning and development is still treated as a
In the late 1960s, Melvin Conway submits a paper on computer manufacturers and compiler design to the Harvard Business Review. They reject it -- insufficient
You are interested in our courses or you simply have a question that needs answering? You can contact us at anytime! We will do our best to answer all your questions.
Contact us

