
Harness Engineering: Warum der Rahmen wichtiger ist als das Modell
Ich habe drei Iterationen gebraucht, um ein einfaches Feature in zwei Repos zu implementieren. Nicht weil das Modell schlecht war — dasselbe Modell, dieselbe

Ich habe drei Iterationen gebraucht, um ein einfaches Feature in zwei Repos zu implementieren. Nicht weil das Modell schlecht war — dasselbe Modell, dieselbe Aufgabe. Das Problem war, dass ich keinen Harness hatte: Ich war das menschliche Clipboard zwischen zwei Welten, die nichts voneinander wussten, der manuelle Koordinator für zwei Agenten ohne gemeinsame Struktur, und schließlich der Planner, der nach zwei gescheiterten Versuchen die Arbeit explizit zerlegt hat — woraufhin es beim ersten Mal funktionierte.
Das war nicht intuitiv. Aber es war reproduzierbar. Und es passt zu einem Datenmuster, das ich seitdem in der Forschung wiederfinde.
Bevor ich erkläre, was ein Harness ist, lohnt sich ein Blick auf die Messergebnisse — denn sie sind widersprüchlicher als die meisten Berichte suggerieren.
Die METR-Studie1 beobachtete 16 erfahrene Open-Source-Entwickler über 246 reale Aufgaben in ihren eigenen Projekten. Ergebnis: Mit AI-Unterstützung brauchten sie im Mittel 19% länger. Bemerkenswert ist nicht nur der Slowdown, sondern die Fehlwahrnehmung: Vorab erwarteten die Entwickler einen Speedup von 24%; selbst nach dem Experiment glaubten sie noch, AI habe sie um 20% beschleunigt.1
Untersucht wurden dabei typische AI-Workflows — vor allem Cursor Pro mit Claude 3.5/3.7 Sonnet, damals aktuelle Topmodelle — nicht aber eigens konstruierte Agentic Harnesses.1
DORA 20242 zeigt ein ähnliches Muster in organisationsweiten Survey-Daten: +25 Prozentpunkte AI-Adoption korrelieren mit -1,5% Durchsatz und -7,2% Stabilität. Gleichzeitig messen individuelle Metriken positive Effekte — +2,1% Produktivität, +3,4% Code-Qualität.2 Das Paradox ist real: Individuelle Gewinne, organisatorische Verluste.
Faros AI beobachtete über 10.000 Entwickler:3 +21% erledigte Aufgaben, +98% gemergte PRs, aber +91% Review-Zeit. Auf Organisationsebene blieb der Zusammenhang zu Delivery-Metriken schwach.3 Mehr Aktivität im Entwicklungssystem, aber wenig klarer Gewinn bei den Delivery-Ergebnissen.
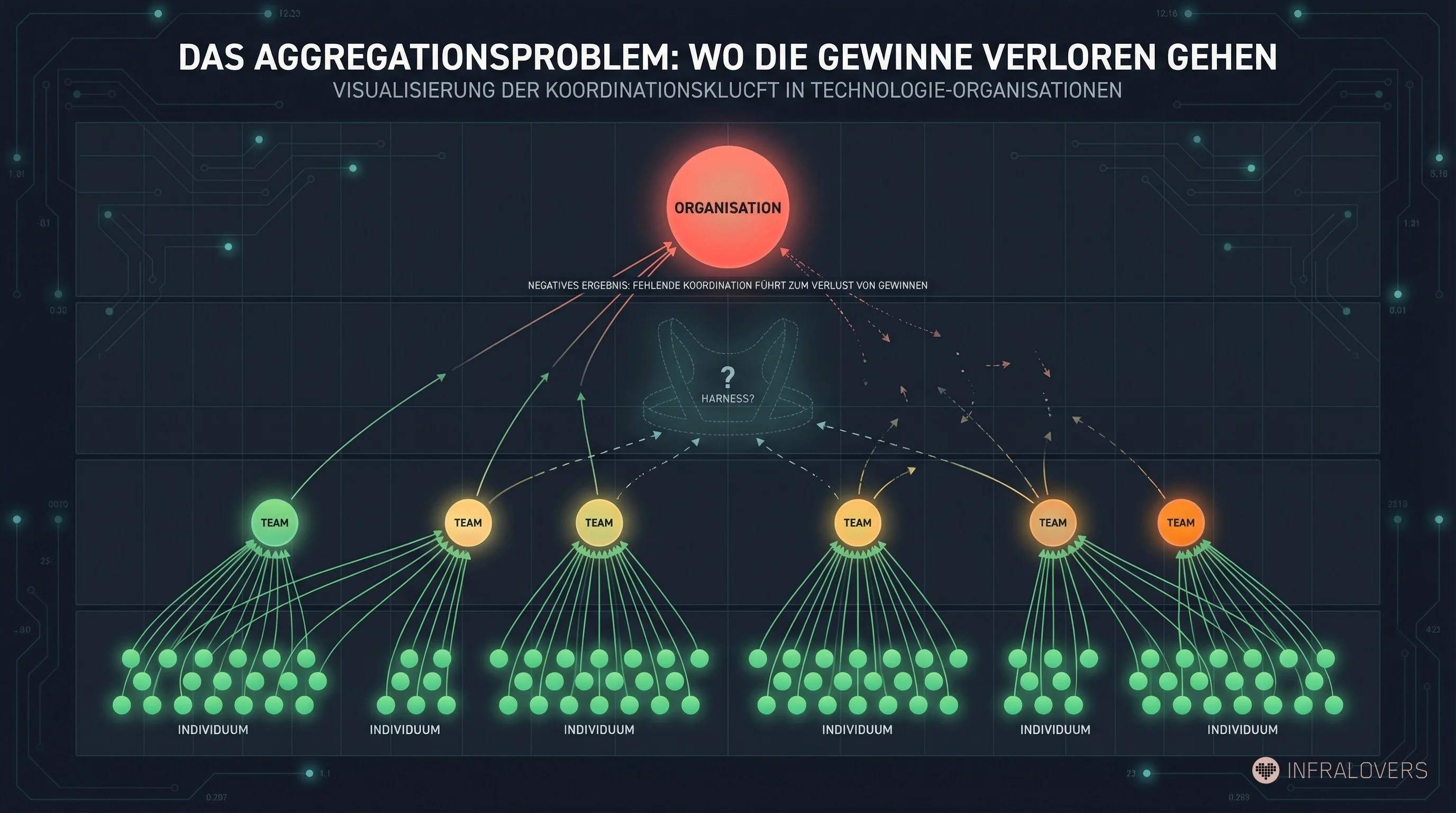
METR untersucht typische AI-unterstützte Entwickler-Workflows — vor allem Cursor Pro mit Claude 3.5/3.7 Sonnet — nicht aber eigens entworfene Harnesses oder experimentelle Multi-Agent-Orchestrierung.1 DORA und Faros AI messen AI-Nutzung auf individueller und organisatorischer Ebene, ohne den Harness-Faktor zu isolieren. Zusammen ergeben sie eine Grundlinie: Was passiert, wenn AI-Tools eingesetzt werden, aber die organisatorische Struktur drum herum nicht mitgedacht wird.
Der Begriff kommt aus dem Software-Testing — und die Parallele ist nicht zufällig. Inngest argumentiert, dass ein Harness in jeder Engineering-Disziplin dasselbe Konzept beschreibt.4 InSpec, Test Kitchen, jedes Compliance-Framework hat einen Testing Harness: die Struktur, die das Werkzeug umgibt und ihm erlaubt, zuverlässig zu arbeiten.5 Das Werkzeug ist fähig. Ohne Harness läuft es trotzdem ins Leere.
Ethan Mollick hat das Framework im Februar 2026 auf Models-Apps-Harnesses ausgedehnt.6 Ein Harness nimmt die rohe Leistung des Modells und macht daraus nutzbare Arbeit — wie ein Pferdegeschirr die Kraft des Pferdes in Zugkraft übersetzt.6 Apps geben dem Modell eine Oberfläche. Harnesses geben ihm eine Organisationsstruktur.
Der Unterschied ist konkret: Eine App wie Cursor ist eine Oberfläche. Der Planner-Worker-Mechanismus — ergänzt um Verifikations- und Abschlusslogik — den Cursor intern für autonome Coding-Sessions einsetzt, ist ein Harness.7 Dasselbe Modell, dramatisch andere Ergebnisse.
Das stärkste empirische Argument dafür kommt von LangChain. LangChain zeigt in seiner OPENDEV-/Deep-Agents-Arbeit8, was allein durch Harness-Veränderungen passiert, ohne Modellwechsel: Terminal Bench 2.0 Leistung von 52,8% auf 66,5% gestiegen — 13,7 Prozentpunkte durch bessere Aufgabenstruktur, bessere Verifikation, bessere Orchestrierung.8 Kein neues Modell. Keine besseren Prompts. Anderer Rahmen.
Bevor ich weitermache: Die plausible Gegenhypothese verdient Raum.
Man könnte argumentieren, dass Harnesses nur dort helfen, wo ohnehin schwache Modelle oder schlechte Prompts das eigentliche Bottleneck sind. Bessere Modelle könnten den Koordinationsaufwand überflüssig machen. GPT-5 oder Claude 4 wären dann nicht nur leistungsfähiger — sie wären auch zuverlässiger, und zuverlässigere Agenten brauchen weniger externe Struktur.
Das ist kein schlechtes Argument. Aber es trägt nicht vollständig: Erstens zeigen die OPENDEV-Ergebnisse8 die Harness-Gewinne auf denselben aktuellen Modellen, die auch in den METR-Studien1 unstrukturiert schlechter abschneiden. Zweitens zeigt Google Research9 in einer Evaluation über 180 Konfigurationen, 5 Architekturen und 4 Benchmarks, dass Multi-Agent-Koordination die Leistung bei parallelisierbaren Aufgaben um bis zu 80,8% verbessert — aber bei sequenziellen Aufgaben um bis zu 70% verschlechtert.9 Das ist keine Modell-Eigenschaft, das ist eine Struktur-Eigenschaft. Drittens: Armin Ronacher formuliert das Gegenrisiko treffend — "AI agents are amazing and a huge productivity boost. They are also massive slop machines if you turn off your brain and let go completely."10 Mehr Modell-Kapazität ohne Harness erzeugt mehr Slop, nicht weniger.
Die Frage ist nicht Harness versus kein Harness. Die Frage ist welcher Harness für welche Aufgabe.
Die Produktivitätsdaten werfen eine naheliegende Frage auf: Wenn das Modell allein nicht reicht — was bauen die Organisationen, die tatsächlich Ergebnisse liefern? Zeit für eine tiefere Recherche. Was dabei sichtbar wird: Die Architekturen unterscheiden sich erheblich, und die Präzision ist wichtig.
Cursor (Wilson Lin, Januar 2026)7 hat ein echtes Multi-Agent-System gebaut: Root Planner ohne eigene Code-Ausführung, rekursive Sub-Planner, Worker auf isolierten Repo-Kopien, ein Übergabemechanismus zurück an den Planner.7 Das System hat einen Web-Browser von Grund auf gebaut: über eine Million Zeilen Code, 1.000 Dateien, eine Woche Laufzeit.7
Cursor-CEO Michael Truell behauptet, das System habe eine mögliche neuartige Lösung für Problem 6 von FirstProof11 gefunden.12 Truells genaue Formulierung: "We believe Cursor discovered a novel solution." Keine externe Validierung dieser Behauptung liegt vor. Das ist eine attributed claim, keine bestätigte Tatsache.
Anthropic Agent Teams13 ist ein produktiver Harness für Claude Code: Lead-Agent koordiniert, Teammates arbeiten in eigenen Kontextfenstern, peer-to-peer Messaging, dateibasiertes Task-Board mit Abhängigkeitslogik. Nicolas Carlini14 hat 16 Agents einen C Compiler in Rust schreiben lassen: ~100.000 LoC, ~20.000 Dollar Kosten, 99% GCC Torture Test Pass Rate.14 Das ist ein Multi-Agent-System, ähnlich wie Cursor.
DeepMind Aletheia15 ist strukturell anders: kein Multi-Agent-System, sondern ein iterativer Generator-Verifier-Reviser-Loop auf einem einzelnen Modell. Gemini 3 Deep Think generiert, verifiziert und revidiert in wiederholten Durchläufen. Aletheia hat 6 von 10 FirstProof-Problemen11 gelöst.15 Das ist beeindruckend — und zeigt, dass die Verifier-Feedback-Schleife selbst, auch ohne Multi-Agent-Koordination, erhebliche Leistungsgewinne liefert.
OpenAI Codex16 beschreibt sich über einen Agent Loop und Harness mit parallel laufenden Sandboxes. Koordinierte Multi-Agent-Workflows sind im Produkt möglich, aber nicht derselbe explizite Planner-Worker-Ansatz, den Cursor prominent beschreibt.16
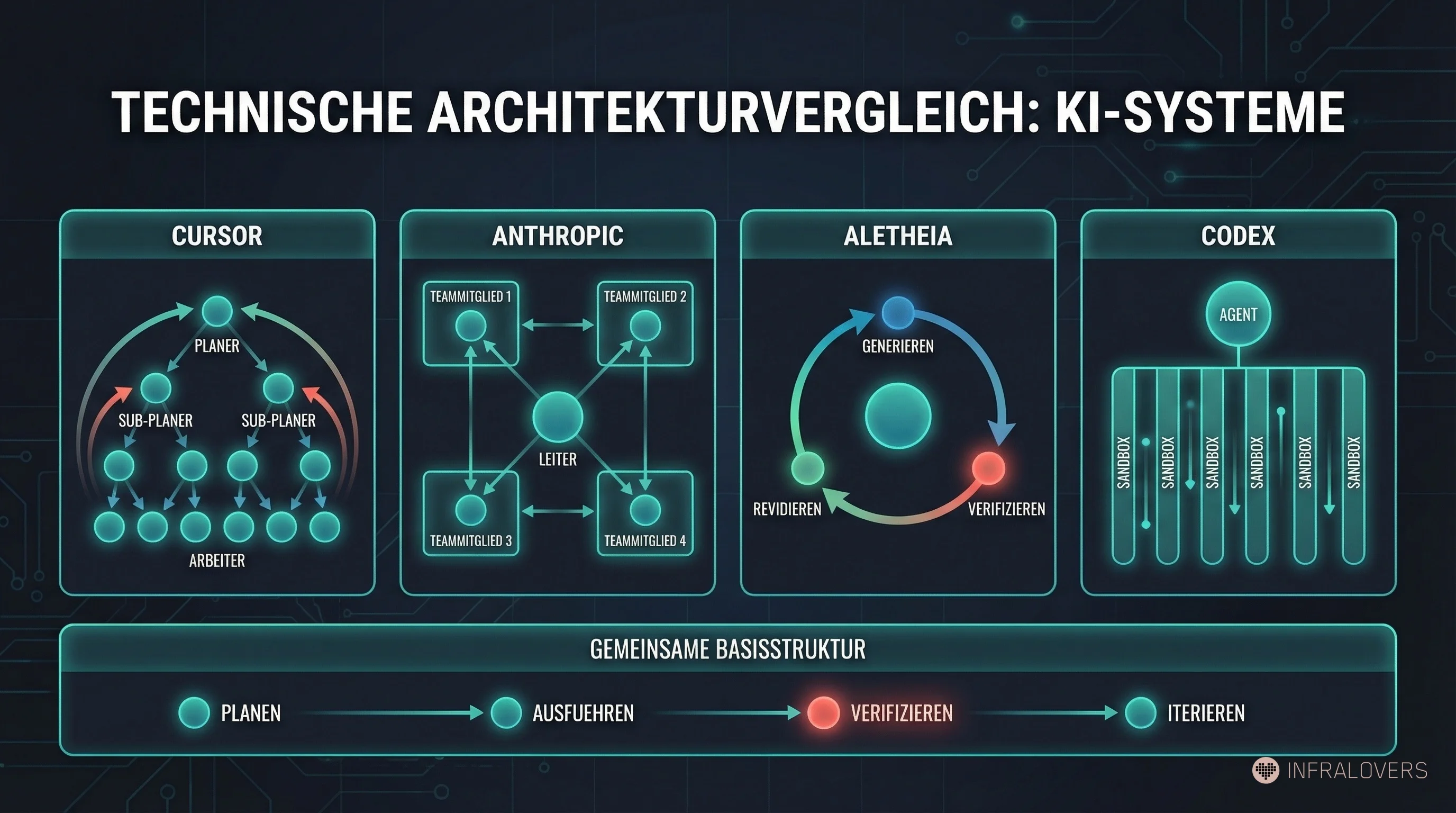
Was diese Systeme gemeinsam haben, ist nicht zwingend Multi-Agent-Koordination. Das gemeinsame Muster ist robuster beschrieben als: Planung, Ausführung, Verifikation und Iteration.
Wang et al.17 haben gezeigt, dass Multi-Agent-Systeme in viele Fälle zu äquivalenten Single-Agent-Systemen mit erweiterten Skills komprimiert werden können — mit 53,7% Token-Einsparung bei gleicher Genauigkeit.17 Der Vorteil von Multi-Agent ist nicht die Vielheit der Agenten. Es ist das Organisationsprinzip dahinter.
Das Pattern ist auch nicht neu. MetaGPT (2023)18 und ChatDev (2024)19 haben formalisierte Rollen-Strukturen für AI-Agents erprobt. Hierarchical Task Networks aus den 1990er Jahren20 formalisieren Aufgabenzerlegung und Verifikation. Was jetzt passiert, ist industrialisierte Konvergenz auf einem älteren Muster — mit Modellen, die es erstmals praktisch umsetzbar machen.
Hier ist der Punkt, an dem ich die Begeisterung bremsen muss.
Das Harness-Pattern funktioniert dort gut, wo Verifikation schnell, objektiv und skalierbar ist. Es bricht dort zusammen, wo Feedback schwammig, langsam oder kontextabhängig ist.
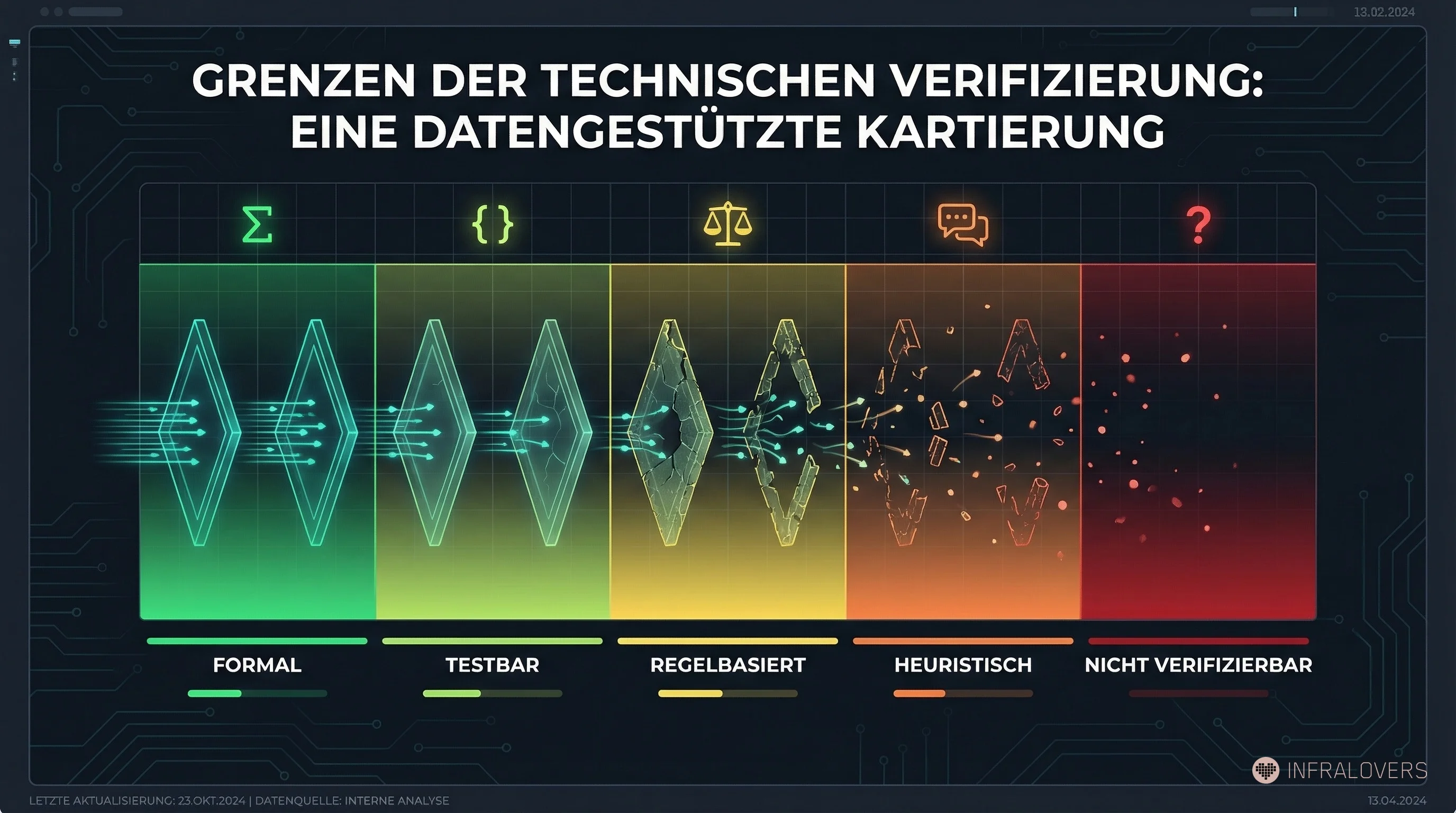
Eine Taxonomie der Verifiability-Stufen:
Stufe 1 — Formal (Mathematik, formale Proofs): Verifikation ist exakt und automatisierbar. AlphaProof, Aletheia, FirstProof-Aufgaben fallen hierhin. Der Judge kann zuverlässig entscheiden.
Stufe 2 — Testbar (Code, CI/CD-Pipelines, Infrastructure Tests): Verifikation durch automatisierte Tests in Sekunden bis Minuten. Das ist die Stärke von OPENDEV und Cursor für Coding-Aufgaben. Die meisten Software-Engineering-Workflows fallen hier.
Stufe 3 — Regelbasiert (Rechtliche Zitate, medizinische Kodierung, Compliance): Verifikation durch definierte Regeln möglich, aber langsamer und kontextabhängiger. Harnesses funktionieren hier, brauchen aber menschliche Prüfschritte.
Stufe 4 — Heuristisch (Customer Service, Recherche, Inhaltsqualität): Verifikation durch Bewertungsmodelle oder menschliches Feedback. Feedback kommt langsam, ist weniger zuverlässig. Das Harness-Pattern liefert hier weniger klare Gewinne.
Stufe 5 — Nicht verifizierbar (Kreative Strategie, ethische Entscheidungen, politisches Urteil): Kein objektiver Judge möglich. Das Pattern bricht hier grundlegend zusammen.
Die meisten beeindruckenden Ergebnisse — LangChain OPENDEV8, Cursor's Browser-Bau7, Aletheia's Proofs15 — liegen bei Stufe 1-2. Die Extrapolation auf Stufe 4-5 ist eine Hypothese, keine bewiesene These.
Eine im Februar 2026 veröffentlichte Deer-Valley-Position bringt es auf den Punkt21: "Organizations are constrained by human and systems-level problems. We remain skeptical of the promise of any technology to improve organizational performance without first addressing human and systems-level constraints."21 Die Constraints bei Stufe 4-5 liegen in der Natur der Aufgabe, nicht im Harness.
Was ich an diesem Pattern am aufschlussreichsten finde: Wir kennen es. Nicht von AI-Systemen — von uns selbst.
Als Infrastructure as Code aufkam, haben wir nicht Server-Grenzen eliminiert. Wir haben Terraform, Ansible, Kubernetes gebaut — Koordination über Grenzen hinweg. Als Microservices zu komplex wurden, haben wir kein Monolith-Refactoring gemacht. Wir haben Service Mesh, API Gateways und Distributed Tracing gebaut. Die Infrastruktur blieb verteilt. Die Koordination wurde explizit.
Das Harness-Pattern ist dieselbe Intuition, angewendet auf Agenten: Nicht die Grenzen beseitigen. Die Koordination explizit machen.
Ob Conway's Law für Agenten gilt — ob also die Kommunikationsstruktur des Harness die Struktur des produzierten Codes spiegelt — ist eine interessante Hypothese. Die Evidenzlage dafür ist dünn. Ich sehe das Muster in meinen eigenen Experimenten, aber ein einzelner Beobachter mit zwei Repos ist kein statistischer Beweis. Das bleibt eine Frage, keine These.
Was ich mit mehr Überzeugung sagen kann: Der Harness ist kein Optimierungs-Trick. Er ist — zumindest in den bisher beobachteten Fällen — die Grundbedingung dafür, dass Agenten zuverlässig arbeiten können. Ohne Struktur haben wir nicht schlechte Agenten — wir haben Zufallsgeneratoren mit sehr guten Manieren.
Drei Fragen für das nächste Team-Meeting:
1. Auf welcher Verifiability-Stufe liegen eure Aufgaben? Coding-Tasks mit Tests fallen bei Stufe 2. Research-Tasks mit subjektiver Qualitätsbewertung bei Stufe 4. Ein Harness für Stufe-2-Aufgaben zu bauen ist sinnvoll. Denselben Harness auf Stufe-4-Aufgaben anzuwenden und ähnliche Ergebnisse zu erwarten, ist eine ungeprüfte Extrapolation.
2. Habt ihr einen expliziten Planner — oder hofft ihr auf Emergenz? Der Planner muss nicht ein anderes Modell sein. Er kann ein Prompt, ein Mensch, ein Spec-Dokument sein. Aber irgendetwas muss die Arbeit zerlegen, bevor Worker anfangen. Emergente Koordination ohne explizite Struktur erzeugt das METR-Muster: viel Aktivität, wenig Fortschritt.
3. Wie lang ist euer Feedback-Loop? OPENDEV gewinnt, weil Terminal Bench 2.0 Feedback in Sekunden liefert.8 Wenn euer Feedback-Loop Stunden oder Tage dauert, bricht das Harness-Muster unter realen Bedingungen. Dann ist der erste Schritt nicht das Harness — sondern den Feedback-Loop zu beschleunigen.
Die Antwort auf schlechte Agenten-Performance liegt selten in einem besseren Modell und fast nie in weniger Repos. Die Frage ist: Welche Verifiability hat die Aufgabe — und welche organisatorische Struktur gebt ihr euren Agenten?
Dieser Post ist Teil einer Serie über AI und Software-Architektur. Die vorherigen Teile behandeln die Fünf Stufen der KI-Entwicklung, Dark Factory Architektur, den Dark Factory Gap und Conway's AI-Inverse.
Dieser Post entstand als Neuschrieb eines früheren Drafts — mit systematisch ergänzter Forschung. Ausgangspunkt war mein Marjorie-Experiment (drei Iterationen, zwei Repos, ein Aha-Moment). Die Kernthese wurde dann gegen verfügbare empirische Datenpunkte getestet: METR-Studie, DORA 2024, Faros AI, LangChain OPENDEV.
Die vier Architektur-Beschreibungen (Cursor, Anthropic, DeepMind, OpenAI) wurden manuell gegen primäre Quellen geprüft — und dabei entschieden differenziert: Cursor und Anthropic sind Multi-Agent-Systeme, Aletheia und Codex sind das nicht. Die Cursor-Mathematik-Behauptung ist explizit als attributed claim gelabelt, weil keine externe Validierung vorliegt. Die Verifiability-Taxonomie ist meine eigene Kategorisierung, keine zitierte Quelle.
Erstellt mit Claude Opus 4.6. Forschungsquellen per arXiv und Primärquellen verifiziert. Cursor-Architektur-Details gegen Wilson Lin's Blog-Post abgeglichen. Den vollständigen Workflow beschreibe ich in AI-gestützte Wissensarbeit: Wie ich meinen Recherche- und Schreibprozess neu aufbaue.
METR (2025). Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity. arXiv:2507.09089. arxiv.org/abs/2507.09089 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Google Cloud (2024). DORA 2024 State of DevOps Report. dora.dev/research/2024/ ↩︎ ↩︎
Faros AI (2025). Developer productivity with AI: What 10,000 developers tell us. Faros AI Research. (Zitiert nach Sekundärberichten; primäre Veröffentlichung auf faros.ai) ↩︎ ↩︎
Inngest (2026). Your Agent Needs a Harness, Not a Framework. inngest.com/blog. inngest.com/blog/your-agent-needs-a-harness-not-a-framework ↩︎
Böckeler, Birgitta (2026). Harness Engineering. martinfowler.com. martinfowler.com/articles/exploring-gen-ai/harness-engineering.html ↩︎
Mollick, Ethan (2026). A Guide to Which AI to Use in the Agentic Era. One Useful Thing, February 17, 2026. oneusefulthing.org/p/a-guide-to-which-ai-to-use-in-the ↩︎ ↩︎
Lin, Wilson (2026). Scaling long-running autonomous coding. Cursor Blog, January 2026. cursor.com/blog/scaling-agents ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
LangChain (2026). Improving Deep Agents with Harness Engineering. LangChain Blog. blog.langchain.com/improving-deep-agents-with-harness-engineering/ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Google Research (2025). Towards a Science of Scaling Agent Systems. arXiv:2512.08296. arxiv.org/abs/2512.08296 ↩︎ ↩︎
Ronacher, Armin (2026). Agent Psychosis. lucumr.pocoo.org, January 18, 2026. lucumr.pocoo.org/2026/1/18/agent-psychosis/ ↩︎
FirstProof Benchmark (2026). Formal mathematical problem set for AI evaluation. arXiv:2602.05192. arxiv.org/abs/2602.05192 ↩︎ ↩︎
Truell, Michael (2026). Attributed statement auf X/Twitter. Exact wording: "We believe Cursor discovered a novel solution to Problem Six of the First Proof challenge." Keine externe Validierung liegt vor. x.com/mntruell/status/2028903020847841336 ↩︎
Anthropic (2026). Orchestrate teams of Claude Code sessions. Claude Code Documentation. code.claude.com/docs/en/agent-teams ↩︎
Carlini, Nicolas (2026). Building a C compiler in Rust with 16 Claude agents. Anthropic Engineering Blog. anthropic.com/engineering/building-c-compiler ↩︎ ↩︎
DeepMind (2026). Aletheia: Iterative reasoning with Generate-Verify-Revise loops. arXiv:2602.21201. arxiv.org/abs/2602.21201 ↩︎ ↩︎ ↩︎
OpenAI (2026). Unrolling the Codex agent loop. OpenAI Research. openai.com/index/unrolling-the-codex-agent-loop/ ↩︎ ↩︎
Wang et al. (2026). Compressing Multi-Agent Systems into Equivalent Single-Agent Systems. arXiv:2601.04748. arxiv.org/abs/2601.04748 ↩︎ ↩︎
Hong, Sirui et al. (2023). MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework. arXiv:2308.00352. arxiv.org/abs/2308.00352 ↩︎
Qian, Chen et al. (2024). ChatDev: Communicative Agents for Software Development. ACL 2024. arxiv.org/abs/2307.07924 ↩︎
Erol, Kutluhan et al. (1994). HTN Planning: Complexity and Expressivity. AAAI-94. (Hierarchical Task Networks als formaler Vorläufer der Aufgabenzerlegungs-Patterns) ↩︎
Orosz, Gergely (2026). The Future of Software Engineering with AI: Six Predictions. The Pragmatic Engineer Newsletter, February 24, 2026. newsletter.pragmaticengineer.com/p/the-future-of-software-engineering-with-ai (Deer Valley Workshop, ca. 10.-11. Februar 2026, organisiert von Martin Fowler / Thoughtworks) ↩︎ ↩︎
Lerne, wie man KI in Codeprojekte integriert, um effizienter zu arbeiten und innovative Lösungen zu schaffen.
Ich habe drei Iterationen gebraucht, um ein einfaches Feature in zwei Repos zu implementieren. Nicht weil das Modell schlecht war — dasselbe Modell, dieselbe
Absicherung Ihrer selbstgehosteten Automation: Ein Deep Dive in die n8n und Vault/OpenBao Integration In der sich rasant entwickelnden Landschaft der
Workflow-Automatisierung war lange einfach. Trigger feuert, einzelne Schritte werden ausgeführt, Daten wandern von A nach B. Jede Verzweigung ist vorbestimmt.
Weiterbildung ist ein Zufriedenheitsfaktor und ein Wettbewerbsvorteil Weiterbildung wird in vielen Unternehmen noch immer als „Nice-to-have“ behandelt. Als
Melvin Conway reicht Ende der 1960er ein Paper über Computerhersteller und Compiler-Design bei der Harvard Business Review ein. Die lehnt ab — mangels Beweis.
Sie interessieren sich für unsere Trainings oder haben einfach eine Frage, die beantwortet werden muss? Sie können uns jederzeit kontaktieren! Wir werden unser Bestes tun, um alle Ihre Fragen zu beantworten.
Hier kontaktieren

