

HashiCorp Nomad und Vault mit .NET: ASP.NET Core in einem sicheren Workload
Als wir unseren Beitrag HashiCorp Nomad and Vault: Dynamic Secrets veroeffentlichten, lief die Demo ausschliesslich als Python Flask-Anwendung. Seitdem ist das

Im vorigen Artikel, Tool-Surface-Kompression, ging es um die Frage, wie man externe Funktionalität, ganze APIs und Systeme, möglichst token-effizient in den Agenten holt. MCP-Server oder CLI ist dabei genau die Wahl, wie man diese Oberfläche zuschneidet: Cloudflare komprimiert tausende Endpoints auf zwei MCP-Tools, Zechners pi kommt mit vier Shell-Primitiven ganz ohne MCP aus, und beide Pole laufen auf dieselbe schmale Naht zu. Das war ein Hebel an der Token-Last, nicht der einzige.
Diesmal nehme ich mir den nächsten vor, der unabhängig daneben liegt: Egal wie die Funktionalität in den Agenten kommt, der Output, den die Tools zur Laufzeit zurückgeben, bleibt roh und verbos. Und beim grep, beim Test-Runner, bei jedem fremden Tool, dessen Default-Output nicht für Agenten gebaut ist und sich nicht einfach umschreiben lässt, kann man das gar nicht erst an der Quelle reparieren. Genau dort setzt eine ganze Klasse von Werkzeugen an: sie filtert den Output von außen, gerade weil sie den Command selbst nicht ändern kann. Output-Proxies, Boilerplate-Kompressoren, Middleware. Im letzten Artikel war diese Schicht bewusst nicht das Thema.
Neu sind diese Werkzeuge nicht. Ich beobachte sie seit Längerem, nur mit anderem Fokus. Inzwischen sind sie eine ganze Familie: ich habe mal fünf Tools für die Betrachtung ausgewählt, eines davon mit über 60.000 GitHub-Stars (Stand Juni 2026), und seit Oktober 2025 ein erstes Paper, das die Grundannahme systematisch misst statt nur Produktzahlen zu behaupten. Was ich ausgeklammert habe, ist ein eigenes Thema. Dieser Post greift genau diese Schicht auf.
Kurz zurück zum Frame, sonst ergibt der Rest keinen Sinn. Im letzten Artikel habe ich zwei Kostenarten getrennt. Es gibt die fixe Steuer auf die Tool-Definitionen, die mit der Anzahl der Tools wächst (Kardinalität). Und es gibt die variable Steuer auf das, was jeder Aufruf zurückgibt. Die Struktur-Achse adressiert diese variable Steuer am Ursprung: die Antwort entsteht schon an der Quelle schlank und strukturiert, statt als roher Dump.
Die variable Steuer hat aber zwei Angriffspunkte, nicht einen.
Das eine Ende ist Design-Zeit: wenn ich das Tool besitze, gestalte ich die Antwort an der Quelle schmal. Beim MCP-Server heißt das LSP-artige Abfragen statt File-Dumps, "pointers over copies", normalisierte minimale Responses. Bei einem eigenen Command oder CLI heißt das: einen Agent-Output-Mode einbauen, also ein kompaktes Format für den Maschinen-Leser statt des menschen-lesbaren Defaults. Dann entsteht der Noise gar nicht erst. Das repariert das Problem dort, wo es entsteht, kostet aber Buy-in: ich muss das Tool umbauen oder neu bauen.
Das andere Ende ist Laufzeit: das Tool gibt weiter rohen, verbosen Output, und ein Kompressions-Layer dazwischen faltet ihn zusammen, bevor er den Modell-Kontext erreicht. Das repariert nichts am Ursprung, dafür braucht es null Mitarbeit der Tool-Autoren. Es funktioniert auf grep, npm test und jedem Log-Spam, den ich nicht umschreiben kann.
Gleiche Ursache, entgegengesetzte Enden. Und während ich im vorigen Artikel nur das Design-Zeit-Ende beschrieben habe, wirkt in der aktuellen Tool-Landschaft das Laufzeit-Ende aktiver.

Ich nenne diese Klasse Context-Compression-Layer: eine Werkzeug-Klasse, die zwischen Tool-Ausführung, Lese-Pfad und Modell-Kontext sitzt und reduziert, was aus Tool-Outputs, Logs, RAG-Chunks, Files oder Conversation-History tatsächlich in den Modell-Kontext gelangt. Die behauptete Token-Reduktion liegt in dieser Tool-Familie typischerweise bei 60 bis 95 Prozent. Auf die Zahlen komme ich zurück, die sind der wunde Punkt.
Wer in der Klasse spielt, ordnet sich entlang weniger Dimensionen. Headroom, eines der Tools, kategorisiert die angrenzenden Tools offen nach Scope (was wird komprimiert), Deploy (wie integriert), Local (laufen die Daten im Haus) und Reversible (lässt sich die Kompression rückgängig machen). Das ist eine brauchbare Landkarte, also benutze ich sie.
„Kompression" ist dabei nur der Sammelbegriff, unter dem drei verschiedene Mechaniken stecken: filtern, externalisieren, den Lese-Pfad ersetzen. Worauf es bei jedem Mitglied ankommt, ist, welche davon es eigentlich tut.
Der letzte Halbsatz ist die eigentliche Pointe. Diese Tools konkurrieren nicht nur, sie stapeln sich. Man wählt nicht eins, man stapelt sie: ein breiter Layer obendrauf, der einen engen, schnellen Shell-Kompressor unter sich laufen lässt. Das ist ein anderes mentales Modell als "welches Tool ist das beste".

Eine Grenze dieser ganzen Klasse hat mich oben schon bei RTK gestreift: der Shell-Hook greift nur auf Bash-Calls, was der Agent über seine eingebauten Read- und Grep-Tools liest, bleibt unkomprimiert. Auf genau diese Lücke gibt es eine zweite Antwort, die anders ansetzt. Sie komprimiert den Output nicht, sie macht das Grep überflüssig. Ein Werkzeug wie Graphify baut die Codebasis einmal in einen abfragbaren Wissensgraphen um, committet ihn ins Repo und lenkt den Agenten per Hook weg vom Datei-Lesen, hin zu gezielten Graph-Abfragen. Über 69.000 Stars (Stand Juni 2026), MIT; die behauptete Ersparnis von rund Faktor 70 pro Abfrage stammt aus dem README und einem großen Beispiel-Repo, also dieselbe Vorsicht wie bei allen Zahlen hier. Die Stoßrichtung ist eine andere als bei den Kompressoren: nicht den verbosen Output kleiner machen, sondern den teuren Lese-Pfad gar nicht erst nehmen. Gratis ist dieser Pfad aber nicht, er tauscht Genauigkeit gegen Kosten, nur an anderer Stelle als die Kompressoren. Der Lese-Pfad ist die Grundwahrheit, er liest die Datei, wie sie ist. Der Graph ist eine abgeleitete Schicht darüber, und Graphify gibt das selbst zu, indem es seine Kanten als EXTRACTED, INFERRED oder AMBIGUOUS markiert. Eine Graph-Abfrage ist billiger und schneller, kann aber eine inferierte Kante liefern, wo das Datei-Lesen die Tatsache gehabt hätte.6
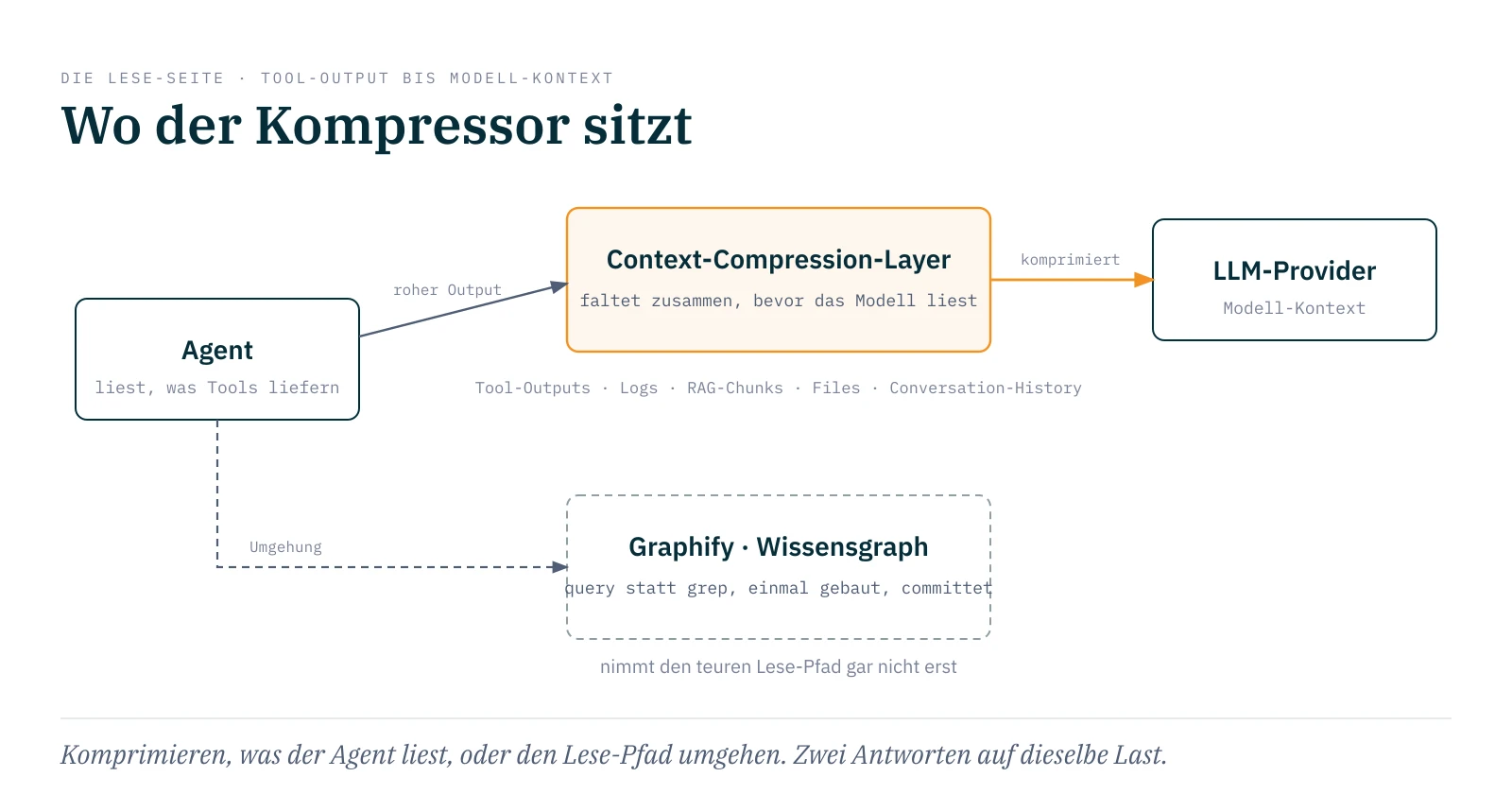
Die drei Mechaniken lassen sich jetzt den Tools zuordnen. RTK und ctx-wire filtern wirklich, sie kürzen und gruppieren den Output. ctx-zip und Headroom externalisieren, sie schreiben das große Ergebnis weg und geben dem Modell nur eine Referenz, das ist eher Retrieval als Kompression. Graphify ersetzt den Lese-Pfad, damit der teure Rohpfad gar nicht erst genommen wird. Gemeinsam ist ihnen nicht der Mechanismus, sondern der Ort im Stack: sie sitzen zwischen dem, was ein Agent lesen könnte, und dem, was tatsächlich in den Modell-Kontext darf.
Im vorigen Artikel war die zentrale Beobachtung eine Konvergenz: Cloudflare, AWS und ein minimaler Single-Player-Harness wie pi laufen von entgegengesetzten Enden auf dieselbe Form zu, wenige Primitive plus Code, der komponiert. Design-Zeit, an der Oberfläche.
Hier sehe ich dieselbe Bewegung, nur eine Schicht tiefer. Während die Vendor-Oberflächen design-zeitig auf wenige Primitive zulaufen, entsteht parallel ein Middleware-Markt, der die Output-Last zur Laufzeit drückt. Ein einzelnes Rust-Binary, ein TypeScript-AI-SDK-Plugin, ein lokaler Intelligence-Layer, alle mit derselben Versprechung im README. Derselbe Attraktor, andere Schicht. Ich finde das auffällig genug, um es zu notieren.
Jetzt zu den 60 bis 95 Prozent. Die stammen, bei nüchterner Betrachtung, fast vollständig aus den READMEs der Projekte selbst, von kommerziellen Anbietern ebenso wie von Open-Source-Projekten. Headroom belegt seine Reversibilitäts-Behauptung mit einer Stichprobe in der Größenordnung von hundert Fällen, RTK gar nicht, der Rest bewegt sich dazwischen. "Same answers" ist eine Marketing-Zeile, keine geprüfte Eigenschaft. Wer die Klasse in einen regulierten Kontext bringt, sollte das wissen.
Und es gibt inzwischen die Gegenprobe aus dem Feld, die vor allem eines zeigt: wie viel ein Kompressor bringt, hängt fast vollständig davon ab, wie optimiert die Pipeline davor schon ist. In einem LinkedIn-Thread berichtete Mitko Vasilev, dass Headroom in seinem ohnehin aggressiv optimierten Coding-Stack nicht in die Nähe der Marketing-Zahl kam: erwartet 90 Prozent, gemessen 4,8; mehrere Praktiker im selben Thread meldeten rund 4 bis 10 Prozent auf normalem Claude Code oder Codex statt der 70 bis 90 von der Produktseite. Die mageren Prozente werden fraglich, sobald man die Kehrseite einrechnet: einer berichtete, dass der Kompressor zu aggressiv schnitt und der Harness die fehlenden Daten in zusätzlichen Calls nachholte, Vasilev selbst beziffert den Overhead seines Layers auf etwa drei Prozent, dazu Latenz. Dieselben Stimmen nennen aber genauso klar den Fall, in dem der Layer liefert: ein Pfad, an dem noch niemand gedreht hat, etwa ein GitHub-Copilot-Abo, das man einfach durchproxyt, gibt durchaus die hohen Prozente her. Kein kontrollierter Benchmark, sondern ein Bündel Feld-Berichte, aber das Warnschild ist deutlich: die README-Prozente sind die Obergrenze für den unoptimierten Fall, und je mehr du vorne schon selbst gedreht hast, desto weniger bleibt für den Kompressor übrig.7
Genau an dieser Lücke wird das ACON-Paper interessant. ACON (Agent Context Optimization) optimiert Kompression nicht über fest verdrahtete Filter, sondern über eine gelernte Anweisung im Sprachraum: man nimmt Paare von Verläufen, in denen voller Kontext gelingt und komprimierter scheitert, lässt ein Modell die Ursache analysieren und passt die Kompressions-Guideline an. Die Messungen sind herstellerunabhängig und gehen in die richtige Richtung. 26 bis 54 Prozent weniger Spitzen-Tokens, und zwar bei gleicher oder besserer Trefferquote, nicht trotz schlechterer. Destilliert in kleinere Modelle bleiben über 95 Prozent der Genauigkeit erhalten.8
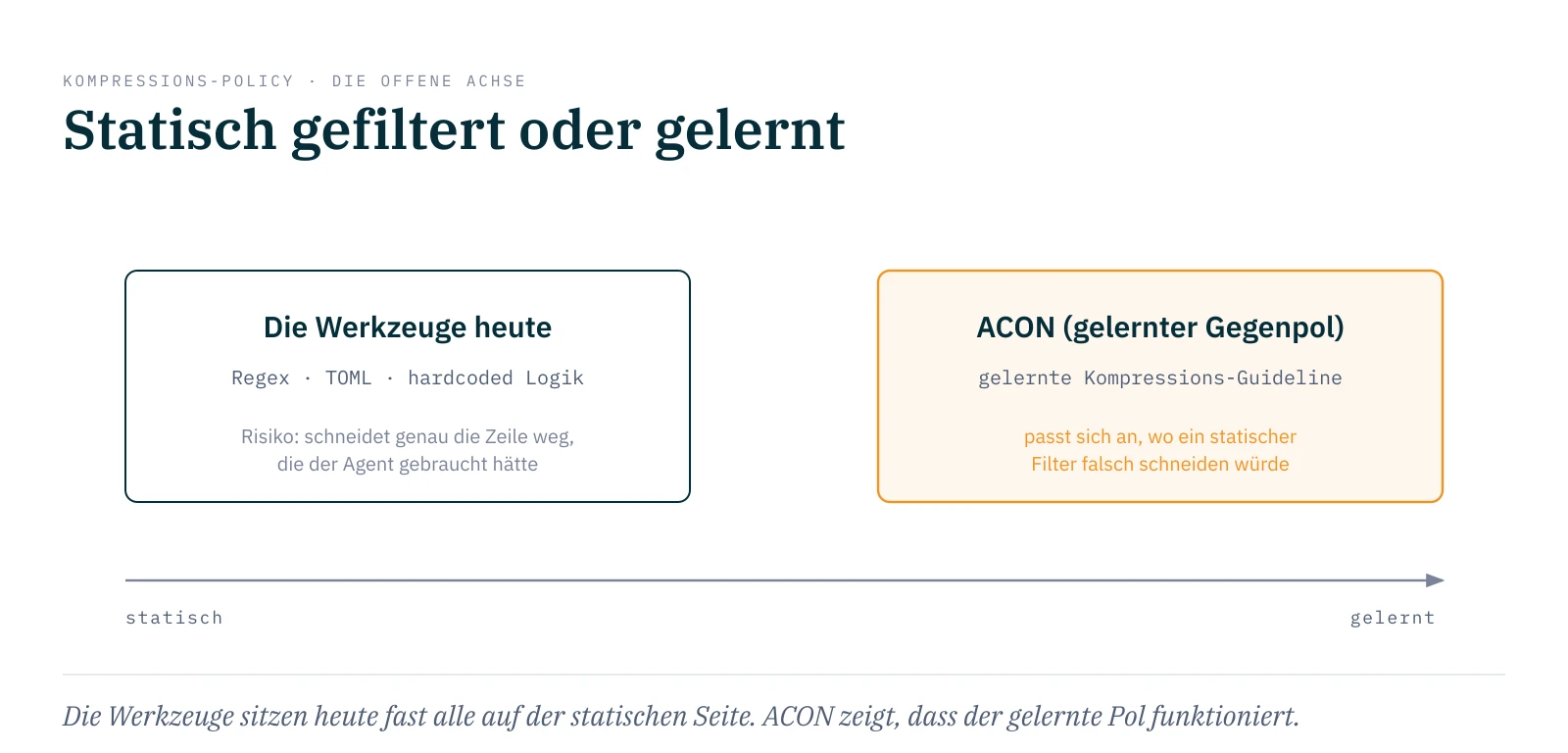
Zwei Dinge nehme ich daraus mit. Erstens: ACON zeigt, dass Kompression die Aufgaben-Genauigkeit halten kann, herstellerunabhängig gemessen statt vom Tool selbst behauptet. Aber das belegt die Prämisse, nicht die Klasse. ACON misst seine eigene gelernte Guideline, nicht die statischen Tools, um die es hier geht. Das ist ein anderer Mechanismus. Erreichbar ist das Ziel damit gezeigt. Dass die Tools es erreichen, nicht. Zweitens, und das ist die schärfere Linie: die Achse statisch gegen gelernt. Die meisten Tools filtern statisch, mit Regex, TOML oder hardcoded Logik, und sind auf bekannte Muster getunt: RTK bringt Strategien für über hundert Commands mit, ctx-wire filtert über TOML-Regeln, die man pro Fall anlegt. Für ein nicht-standardisiertes oder neues Tool, für das weder eine Strategie noch eine Regel existiert, bleibt entsprechend wenig hängen. Das ist die strukturelle Grenze des statischen Ansatzes, nicht ein Bug einzelner Tools.
Eine Ausnahme deutet in die andere Richtung: LeanCTX verkauft sich nicht als Filter, sondern als Context-Intelligence, die entscheidet und sich merkt. Ob hinter dem Label wirklich etwas Gelernt-Adaptives steckt oder eine Heuristik, sagt die Eigenbeschreibung nicht, und unabhängig gemessen ist es nicht. ACON ist der gelernte Gegenpol, der diese Richtung tatsächlich zeigt: eine Policy, die sich dort anpasst, wo ein statischer Filter genau die Zeile wegschneidet, die der Agent gebraucht hätte, und die nicht an einer Liste bekannter Commands hängt. Die Richtung ist im Tool-Markt also angedeutet. Gemessen ist sie nur bei ACON.
Der per-Tool-Vergleich selbst, RTK gegen Headroom gegen ctx-wire, ist damit noch offen. Diese Grenze ziehe ich bewusst, sie wäre der nächste Schritt, den ich noch nicht gegangen bin.
Damit lässt sich die Entscheidung, die mich eigentlich interessiert, sauber stellen. Variable Token-Steuer drücken, ja, aber an welchem Ende?
Design-Zeit, wenn ich das Tool besitze. Baue ich den MCP-Server selbst, gehört die Struktur der Antwort ins Design; schreibe ich den Command selbst, bekommt er einen kompakten Agent-Output-Mode statt des verbosen Default. Strukturierte Abfragen, schmale Responses, das ist die dünnste tragfähige Schicht, und sie kostet zur Laufzeit nichts.
Laufzeit, wenn ich das Tool nicht besitze. grep, der Test-Runner, ein fremder MCP-Server, ein Vendor-CLI: das kann ich nicht umbauen, also schiebe ich einen Kompressor davor. Retrofit, tool-agnostisch, sofort wirksam, gröber.
Und eine versteckte Kosten-Stelle, die ich noch nicht ausgerechnet habe, aber für real halte: ein Layer, der Prefixe komprimiert, kann die Provider-seitigen KV-Cache-Treffer untergraben, die man an anderer Stelle teuer zu erhalten versucht. Kompression spart Tokens und kann zugleich Cache-Hits kosten. Wo dieser Trade-off kippt, weiß ich nicht. Das ist eine der Stellen, an denen ich gerade selbst nachmesse.
Die präzisere Version der ursprünglichen These lautet inzwischen: die variable Token-Steuer ist ein Ziel mit zwei Angriffsflächen, und die Industrie baut an beiden gleichzeitig. Am Design-Ende konvergieren die Oberflächen auf wenige Primitive. Am Laufzeit-Ende entsteht eine eigene Middleware-Schicht, die sich stapeln statt nur konkurrieren lässt, und deren Grund-Prämisse, dass Kompression die Genauigkeit hält, gerade ihre erste herstellerunabhängige Stütze bekommt. Die einzelnen Tools haben sie noch nicht.
Die Frage, die ich offen mitnehme, ist die statisch-gegen-gelernt-Achse. Die Tools sitzen heute fast alle auf der statischen Seite, weil das billig und sofort lieferbar ist. ACON zeigt, dass der gelernte Pol funktioniert. Ich vermute, dass sich die Klasse in den nächsten Quartalen genau dorthin bewegt, und ich würde es gern gegen echte Per-Tool-Benchmarks prüfen, statt es zu glauben.
Diese Gegenprobe ist kein exotisches Vorhaben: derselbe Task einmal ohne, einmal mit Kompressor, und gemessen wird nicht die Token-Ersparnis, sondern ob die Antwort dieselbe blieb, also Treue, Vollständigkeit, keine neuen Halluzinationen. Werkzeuge dafür liegen fertig herum, offline gegen ein fixes Task-Set wie RAGAS, DeepEval oder promptfoo, oder gegen echte Produktions-Traces wie dt-evals von Dynatrace. Die Zahl, die zählt, ist nicht 60 bis 95 Prozent gespart, sondern dass die Aufgabe genauso gut ausging.
Wenn du heute einen Agenten-Stack baust: kläre erst, welche deiner Token-Last aus Tools kommt, die du besitzt, und welche aus fremden. Das erste Ende reparierst du im Design. Für das zweite stapelst du einen Kompressor davor, und du wählst ihn entlang Scope, Lokalität und Reversibilität, nicht entlang der README-Prozente.
Eine letzte Abgrenzung, damit der Rahmen sauber bleibt. Die ganze Steuer hier sitzt auf dem, was der Agent liest: Tool-Output, Logs, fremder Kontext. Daneben gibt es eine davon unabhängige Steuer auf das, was das Modell selbst schreibt, die Länge seiner eigenen Antworten. Die ist nicht nur eine Kostenfrage: ein Paper vom März 2026 zeigt, dass erzwungene Kürze auf der Antwort-Seite die Trefferquote großer Modelle sogar heben kann, weil sie deren Hang zum Über-Argumentieren bremst, auf manchen Aufgaben genug, um kleine und große Modelle in der Rangfolge zu tauschen.9 Das ist eine eigene Achse mit eigener Evidenz und verdient ein eigenes Stück, nicht eine Randnotiz in diesem.
Dieser Post ist Teil einer Serie über AI und Software-Architektur. Der direkte Vorgänger ist Tool-Surface-Kompression; davor unter anderem Harness Engineering und Context Engineering.
Die These, dass die variable Token-Steuer zwei Enden hat, stammt aus dem vorigen Artikel, der die Laufzeit-Klasse bewusst ausklammert. Die Substanz für diesen Nachfolger habe ich davor in einer systematischen Aufarbeitung aufgebaut: eine eigene Einordnung der Context-Compression-Layer-Klasse plus Einzelprofile für die fünf Tools (RTK, ctx-wire, ctx-zip, LeanCTX, Headroom) und für die gelernte Kompressions-Guideline aus dem ACON-Paper. An den Rändern später ergänzt: Graphify als Werkzeug anderer Bauart, das die Read/Grep-Lücke nicht komprimiert sondern umgeht, und das Brevity-Constraints-Paper für die abgegrenzte Antwort-Seite. Die Tool-Zahlen sind READMEs entnommen und als projektbehauptet markiert; die ACON-Zahlen sind gegen den Paper-Volltext geprüft und als unabhängige Evidenz gekennzeichnet, das Brevity-Paper ist ein Single-Author-Preprint und entsprechend vorsichtig geführt. Star-Zahlen sind Stand Juni 2026 und veralten.
Den Draft hat Claude Opus 4.8 in einer Stimme und nach Maßstäben gebaut, die ich ihm Stück für Stück beigebracht habe; Idee, Gewichtung und die offen gelassenen Grenzen sind meine.
RTK (Rust Token Killer), github.com/rtk-ai/rtk. CLI-Proxy, Apache-2.0, vier Kompressions-Strategien, Shell-Hook nur auf Bash-Calls; Star-Zahl Stand Juni 2026. Gegen das README geprüft. ↩︎
ctx-wire, github.com/pivanov/ctx-wire. MIT, deklarative TOML-Filter, Secret-Scrubbing, full-log-on-disk, mcp-wrap für MCP-Output. Gegen das README geprüft. ↩︎
ctx-zip, github.com/karthikscale3/ctx-zip. TypeScript, MIT, Tool Discovery plus Output Compaction, Vercel-AI-SDK. Gegen das README geprüft. ↩︎
LeanCTX (lean-ctx), github.com/yvgude/lean-ctx. Lokaler Context-Intelligence-Layer in Rust, Apache-2.0; Star-Zahl Stand Juni 2026. Gegen das README geprüft. ↩︎
Headroom, github.com/chopratejas/headroom. Komprimiert Tool-Outputs, Logs, Files, RAG-Chunks; Library, Proxy oder MCP-Server; Reversibilität / Wiederherstellbarkeit über gecachte Originale als Produktversprechen. Gegen das README geprüft. ↩︎
Graphify, github.com/safishamsi/graphify. MIT, AI-Coding-Assistant-Skill; baut Code, Docs und Schemas in einen abfragbaren Wissensgraphen (lokale tree-sitter-Extraktion), den der Agent per Hook statt Read/Grep abfragt; jede inferierte Kante als EXTRACTED, INFERRED oder AMBIGUOUS getaggt. Faktor-70-Ersparnis und Star-Zahl (Stand Juni 2026) sind README-/Benchmark-behauptet. Gegen das README geprüft. ↩︎
Feld-Berichte aus einem LinkedIn-Thread von Mitko Vasilev (CTO, on-device-AI), 17. Juni 2026. Headroom brachte 4,8 statt der erwarteten 90 Prozent auf einem bereits aggressiv optimierten Stack, bei einem Layer-Overhead von rund drei Prozent. In den Kommentaren: Sean Burke (~4 Prozent auf vanilla Claude Code/Codex, plus zusätzliche Harness-Calls durch zu aggressives Clipping), Rick Raddue (~5 Prozent), Varun R. (meist 8 bis 10 Prozent); zugleich der Hinweis von Vasilev und Adam Pippert (Red Hat), dass ein unoptimierter Pfad wie ein durchgeproxytes GitHub-Copilot-Abo sehr wohl hohe Prozente liefert. Anekdotisch, kein kontrollierter Benchmark. Permalink. ↩︎
Kang, M. et al. (2025). ACON: Optimizing Context Compression for Long-horizon LLM Agents. arXiv:2510.00615. arxiv.org/abs/2510.00615. Gelernte Kompressions-Guideline via contrastive failure analysis; 26 bis 54 Prozent weniger Spitzen-Tokens bei gehaltener oder besserer Trefferquote; gegen den Volltext geprüft. ↩︎
Hakim, M. A. (2026). Brevity Constraints Reverse Performance Hierarchies in Language Models. arXiv:2604.00025. arxiv.org/abs/2604.00025. 31 Modelle, 1.485 Probleme: erzwungene Antwort-Kürze hebt die Genauigkeit großer Modelle in einer kausalen Intervention um rund 26 Punkte und kehrt auf Mathematik- und Wissens-Benchmarks die Größen-Rangfolge um; Mechanismus ist das Über-Argumentieren großer Modelle. Single-Author-Preprint, gegen den Volltext geprüft, vorsichtig zu führen. ↩︎
Lerne, wie man KI in Codeprojekte integriert, um effizienter zu arbeiten und innovative Lösungen zu schaffen.
Als wir unseren Beitrag HashiCorp Nomad and Vault: Dynamic Secrets veroeffentlichten, lief die Demo ausschliesslich als Python Flask-Anwendung. Seitdem ist das
Im vorigen Artikel, Tool-Surface-Kompression, ging es um die Frage, wie man externe Funktionalität, ganze APIs und Systeme, möglichst token-effizient in den
2.500 API-Endpoints. Jeden einzelnen als MCP-Tool exponiert, das wären laut Cloudflare 1,17 Millionen Tokens allein für die Tool-Definitionen, bevor der Agent
Jedes Nomad-Tutorial, das Sie online finden, verwendet den docker-Treiber. Das ist verstaendlich — Container sind portabel, Images buendeln alles, und Docker
In unserem vorherigen Beitrag ueber HashiCorp Nomad und Vault: Dynamic Secrets haben wir den gesamten Lebenszyklus des Secrets Managements fuer eine Python
Sie interessieren sich für unsere Trainings oder haben einfach eine Frage, die beantwortet werden muss? Sie können uns jederzeit kontaktieren! Wir werden unser Bestes tun, um alle Ihre Fragen zu beantworten.
Hier kontaktieren