

Lokale Hybrid-Suche: Retrieval ohne RAG-Pipeline
Vor zwei Wochen habe ich darüber geschrieben, was sich ändert, wenn das Modell gleich bleibt und nur der Harness wechselt. Kurzfassung: der Wrapper macht mehr

2.500 API-Endpoints. Jeden einzelnen als MCP-Tool exponiert, das wären laut Cloudflare 1,17 Millionen Tokens allein für die Tool-Definitionen, bevor der Agent auch nur eine einzige Anfrage formuliert hat. Cloudflare nennt das "Context-Suicide".1
Ihre Lösung: zwei Tools. search() und execute(). Der Agent sucht, was er braucht, und führt es aus. Alles andere kommt dynamisch, just-in-time, direkt aus der Dokumentation. Rund 1.000 Tokens statt 1,17 Millionen, eine Reduktion um 99,9 Prozent.2
Am anderen Ende derselben Achse steht ein Werkzeug, das aus der Gegenrichtung kommt. Mario Zechners pi, der minimale Coding-Agent-Harness hinter einem Teil der aktuellen Agent-Welle, exponiert genau vier Tools: read, write, edit, bash. System-Prompt und Tool-Definitionen zusammen unter tausend Tokens. Kein MCP, bewusst und auf Dauer.3 Cloudflare komprimiert 2.500 Endpoints von oben nach unten, pi verweigert die Oberfläche von vornherein. Zwei entgegengesetzte Startpunkte, ein erstaunlich ähnliches Ergebnis: wenige Tools, Code oder Shell übernimmt die Komposition, das Modell sieht eine schmale Naht.
Das klingt nach einer eleganten Optimierung für einen Spezialfall. Seit ich die Zahlen gesehen habe, glaube ich, es ist mehr: ein Designprinzip für die Schnittstelle zwischen Agenten und Systemen, das tiefer reicht als die reine Tool-Anzahl. Der Begriff Tool-Surface-Kompression ist nicht meiner, er kursiert in der MCP-Community, von Atlassians Open-Source-Compressor bis zu einer Microsoft-Research-Arbeit über Tool-Space-Interference.4 Was mir an der Diskussion fehlt, ist weniger der Begriff als eine saubere Struktur dahinter: drei Achsen, an denen man tatsächlich drehen kann. Und eine zweite Frage, die seltener gestellt wird: Warum landen zwei so gegensätzliche Werkzeuge wie Cloudflares Code Mode und Zechners pi am selben Punkt, und wo genau treffen sie sich?
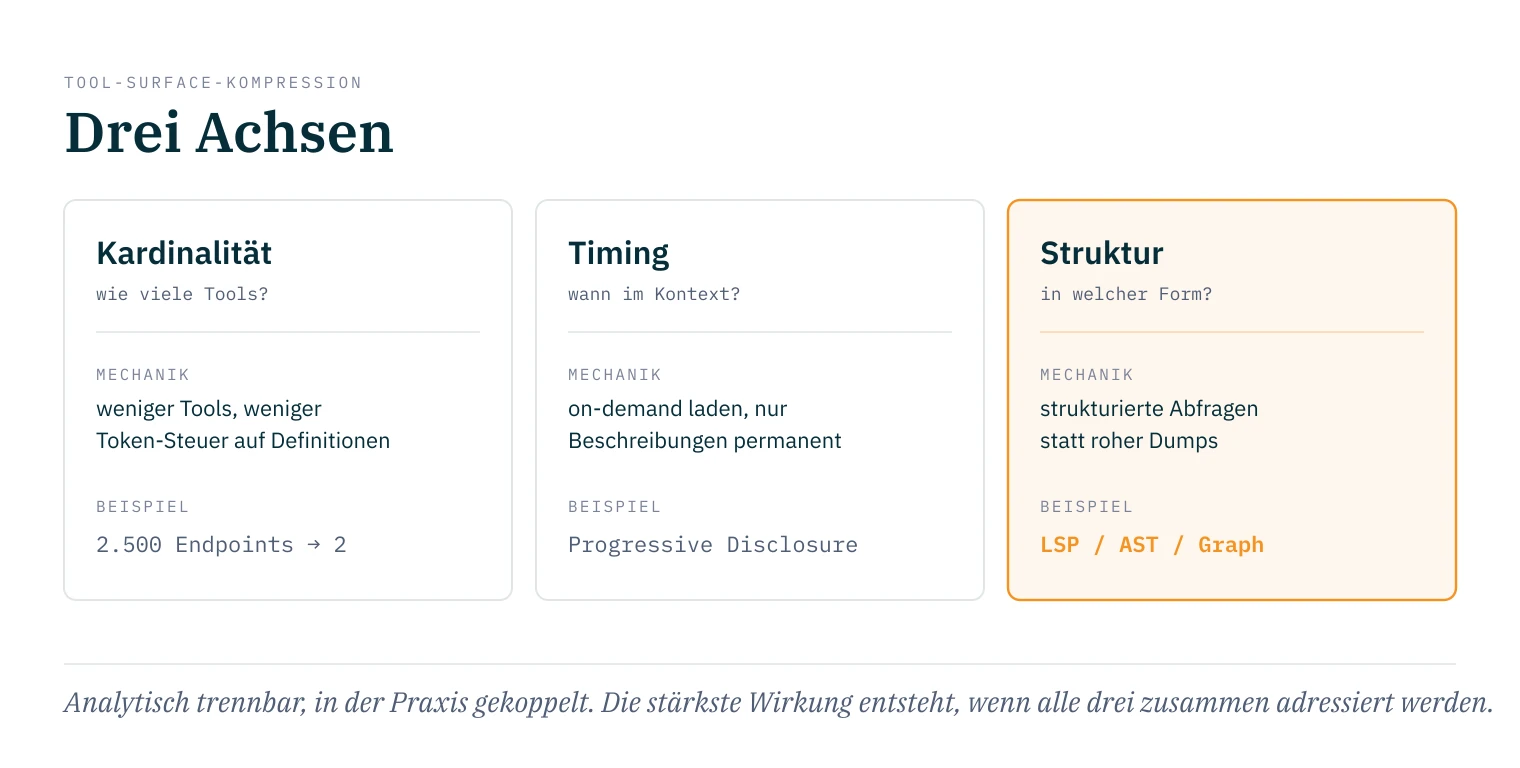
Weniger Tools bedeuten weniger Tokens für Tool-Definitionen, also mehr Kontext-Budget für das eigentliche Reasoning. Das ist die ursprüngliche Intuition, und sie stimmt. Aber Kompression hat drei Achsen, nicht eine.
Kardinalität ist die bekannteste: weniger Tools, weniger Token-Steuer auf Definitionen, weniger Auswahlkomplexität bei jeder Aktion. Bei drei Tools ist die Auswahl trivial. Bei fünfzig wird sie zum eigenständigen Reasoning-Problem. Microsoft Research hat den Effekt gemessen, die Trefferquote sinkt, je mehr Tools gleichzeitig im Spiel sind, und verweist auf OpenAIs Empfehlung, unter zwanzig Funktionen zu bleiben.4
Timing kommt hinzu. Skill-Beschreibungen können dauerhaft im Kontext stehen, der vollständige Inhalt lädt on-demand, wenn der Task passt. Über Dutzende von Skills hält das den dauerhaften Kontext klein, weil nur die kurzen Beschreibungen permanent zählen, nicht die vollen Inhalte. Dieser Ansatz, Progressive Disclosure für Kontext, wird in Zechners pi.dev-Dokumentation explizit benannt: nur die kurzen Beschreibungen stehen permanent im Kontext, die vollen Inhalte laden on-demand.5 Es ist die Timing-Achse: nicht weniger Tools, sondern Tools, die erst dann auftauchen, wenn sie gebraucht werden.
Struktur ist die schärfste neue Einsicht: nicht weniger Tools, sondern Tools, die strukturiert antworten statt roh. Statt fünfzig Dateien in den Kontext zu kippen, fragt der Agent gezielt nach der Definition einer Funktion oder den infrage kommenden Parameter-Typen und bekommt eine normalisierte, minimale Antwort. Jarosław Wąsowski hat das auf die griffige Formel "pointers over copies" gebracht.6 2026 ist es keine These mehr, sondern aus drei unabhängigen Richtungen gebaut: als MCP-Server über das Language Server Protocol (Serena), als AST-Operationen statt Text-Spans (CODESTRUCT) und als vorab-indizierter Code-Graph (CodeGraph, Codebase-Memory).789 Die Messungen zeigen alle dieselbe Richtung, ein Vielfaches weniger Tokens bei gleicher oder besserer Trefferquote. Der Hebel sitzt nicht in der Zahl der Tools, sondern in der Form ihrer Antworten, eine Design-Entscheidung am MCP-Server selbst.
Das ändert die Fragestellung, und hier lohnt es, zwei Kostenarten sauber zu trennen. Es gibt die fixe Steuer auf die Tool-Definitionen, die mit der Anzahl der Tools wächst (Kardinalität), und die variable Steuer auf das, was jeder Aufruf zurückgibt (Struktur). Über einen ganzen Task hinweg kann ein System mit vielen Tools, die alle strukturierte Abfragen beantworten, am Ende weniger Kontext verbrauchen als ein System mit drei Tools, die rohe Grep-Dumps zurückliefern, weil die variable Steuer pro Aufruf den fixen Vorsprung der kleineren Tool-Anzahl wieder auffrisst. Welche Seite gewinnt, hängt von der Zahl der Aufrufe und der Größe der Ergebnisse ab. Kompression ist also nicht nur Anzahl, sie ist auch Form.
Davon zu trennen ist eine ganze Klasse von Werkzeugen, die dieselbe Token-Last von außen drücken: Output-Proxies und Boilerplate-Kompressoren, die Tool-Ausgaben zur Laufzeit zusammenfalten. Sie setzen an der Middleware an, nicht am Design der Oberfläche, und sind hier bewusst nicht das Thema.
Die Unix-Philosophie der 1970er hatte eine Intuition, die durch MCP neue Relevanz bekommt. cat, grep, awk, pipe. Kleine kombinierbare Primitive statt großer spezialisierter Werkzeuge.
search() und execute() sind für eine API das, was grep und pipe für Text sind. Nicht weil zwei Tools schöner sind als tausend, sondern weil zwei Tools einen definierten und kleinen Token-Preis haben.
Der Unterschied zu Unix: Für Agenten kommt der Token-Preis als zusätzliche Dimension hinzu. Ein Unix-Nutzer zahlt keine Steuer für die Existenz von Programmen, die er nicht aufruft. Ein Agent schon, jedenfalls in vielen heutigen MCP-Clients, die alle gelisteten Tool-Definitionen in den Modellkontext laden, ob der Agent sie braucht oder nicht. MCP schreibt das nicht zwingend vor, ein Client kann Tools filtern oder schrittweise sichtbar machen, aber der Normalfall ist heute das volle Laden. Das ist der Grund, warum die Unix-Analogie nicht vollständig trägt, aber das richtige Denkmuster liefert.
Die Achsen sind analytisch trennbar, in der Praxis aber gekoppelt. Timing verändert die effektive Kardinalität, und strukturierte Antworten verlangen oft eine andere Tool-Granularität. Cloudflares Code Mode koppelt Kardinalität und Timing sogar bewusst, indem es die Discovery zum Teil der Schnittstelle macht. Trotzdem hilft die Trennung beim Denken: Ein System mit hoher Kardinalität, aber konsequenter Progressive Disclosure kann besser funktionieren als wenige Tools, die alle dauerhaft im Kontext liegen.
Die stärkste Wirkung entsteht, wenn alle drei Achsen zusammen adressiert werden.
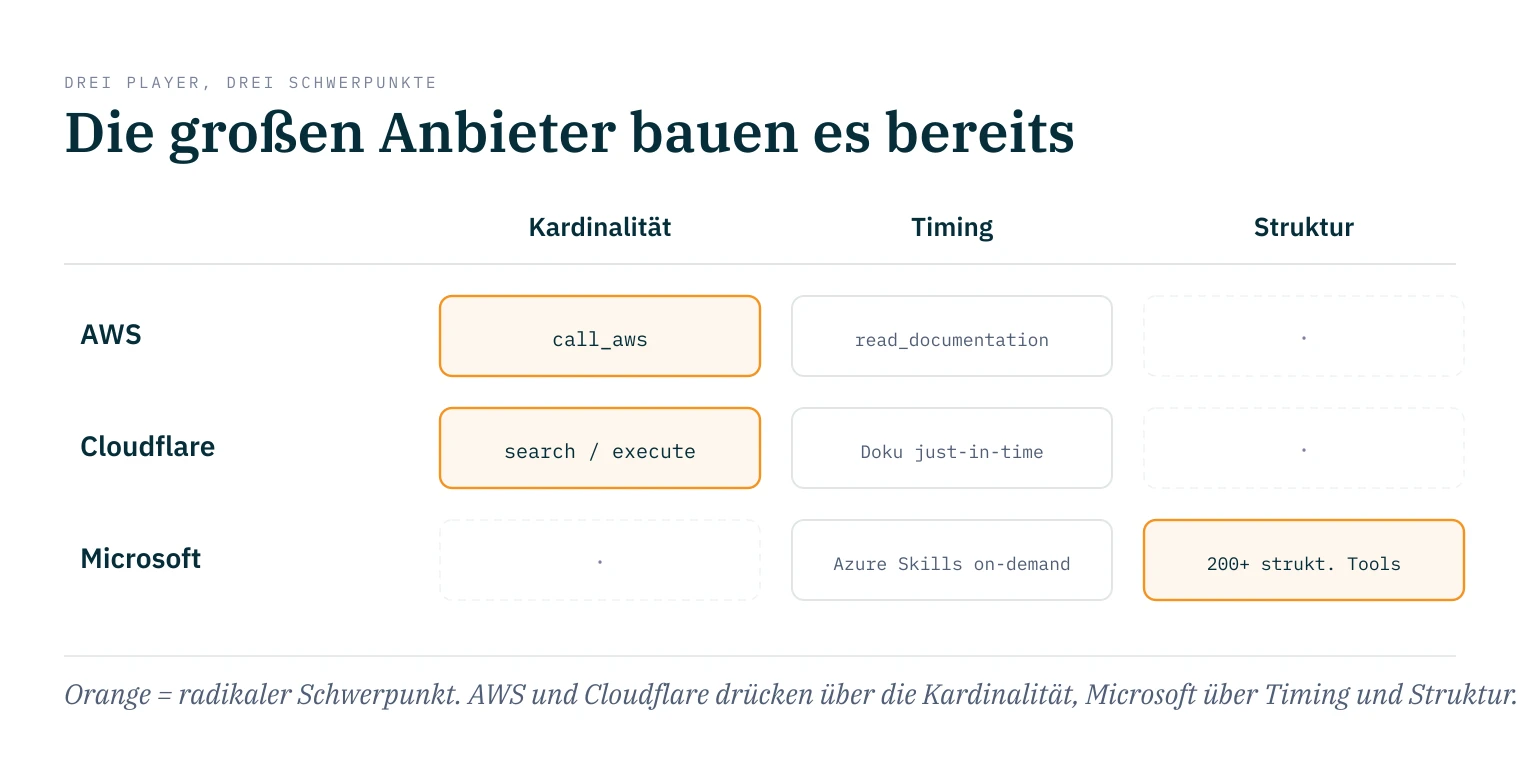
Cloudflare war 2026 nicht allein. Innerhalb weniger Monate haben zwei der größten Cloud-Anbieter dasselbe Muster als offizielles Produkt geliefert, und sie verteilen ihr Gewicht unterschiedlich auf die drei Achsen.
AWS hat im Mai 2026 den AWS MCP Server allgemein verfügbar gemacht.10 Statt jede AWS-API als eigenes Tool zu exponieren, gibt es ein call_aws, das alle 15.000 und mehr AWS-API-Operationen über die bestehenden IAM-Credentials ausführt. Dazu search_documentation und read_documentation, die die passende Doku erst zur Anfragezeit holen, statt sie ins Kontext-Fenster zu legen, und ein run_script, mit dem der Agent kurzen Python-Code schreibt, der mehrere API-Calls in einem Durchgang verkettet. Das ist Cloudflares Code Mode, von AWS gebaut: wenige Tools, Code statt Tool-Calls, Doku on-demand. Verfügbar unter anderem in der Region Frankfurt.
Microsoft hat den gleichen Trend ein paar Wochen früher adressiert, aber an einer anderen Achse.11 Das Azure Skills Plugin bündelt den Azure MCP Server, der 200 und mehr strukturierte Tools über mehr als 40 Azure-Services anbietet, mit mehreren Azure-Skills (azure-prepare, azure-validate, azure-deploy, azure-diagnostics, azure-cost), die on-demand geladen werden statt dauerhaft im Kontext zu stehen. Microsoft komprimiert also nicht radikal über die Kardinalität wie Cloudflare und AWS, sondern über Timing und Struktur: viele Tools, aber strukturiert, plus Skills, die erst auftauchen, wenn der Task sie braucht.
Drei der größten Player, drei Schwerpunkte auf denselben drei Achsen. Das Muster ist kein eleganter Einzelfall mehr, es ist die Richtung. Und Microsoft hat sogar beide Seiten geliefert: dieselbe Forschungsabteilung, die Tool-Space-Interference als Problem vermessen hat, baut mit dem Azure Skills Plugin die Antwort darauf.
Diese drei sind aber alle derselbe Pol: große, gewachsene Oberflächen, von oben heruntergedrückt. AWS hat fünfzehntausend API-Operationen, Cloudflare zweitausendfünfhundert API-Endpoints, Microsoft zweihundert Tools über vierzig Services. Sie komprimieren, weil ihre Oberfläche zu groß ist, um sie zu exponieren. Der andere Pol macht dieselbe Bewegung von der Gegenseite.
pi kommt von unten. Statt eine große Oberfläche herunterzudrücken, baut Zechner sie gar nicht erst auf: vier Tools, kein MCP. Die Begründung ist nicht Ästhetik, sondern eine Beobachtung über die Modelle. Die aktuelle Generation ist so stark darauf trainiert, mit bash und dem read/write/edit-Schema umzugehen, dass alles Weitere mehr Verwirrung als Hilfe stiftet.3 "Bash is all you need", sagt Zechner im Syntax-Podcast, und meint es wörtlich.12 Wenn der Agent ein weiteres Werkzeug braucht, liegt es als CLI-Tool mit README auf der Platte und wird erst gelesen, wenn es gebraucht wird. Das ist Progressive Disclosure, nur auf der Ebene ganzer Werkzeuge statt einzelner Skills.
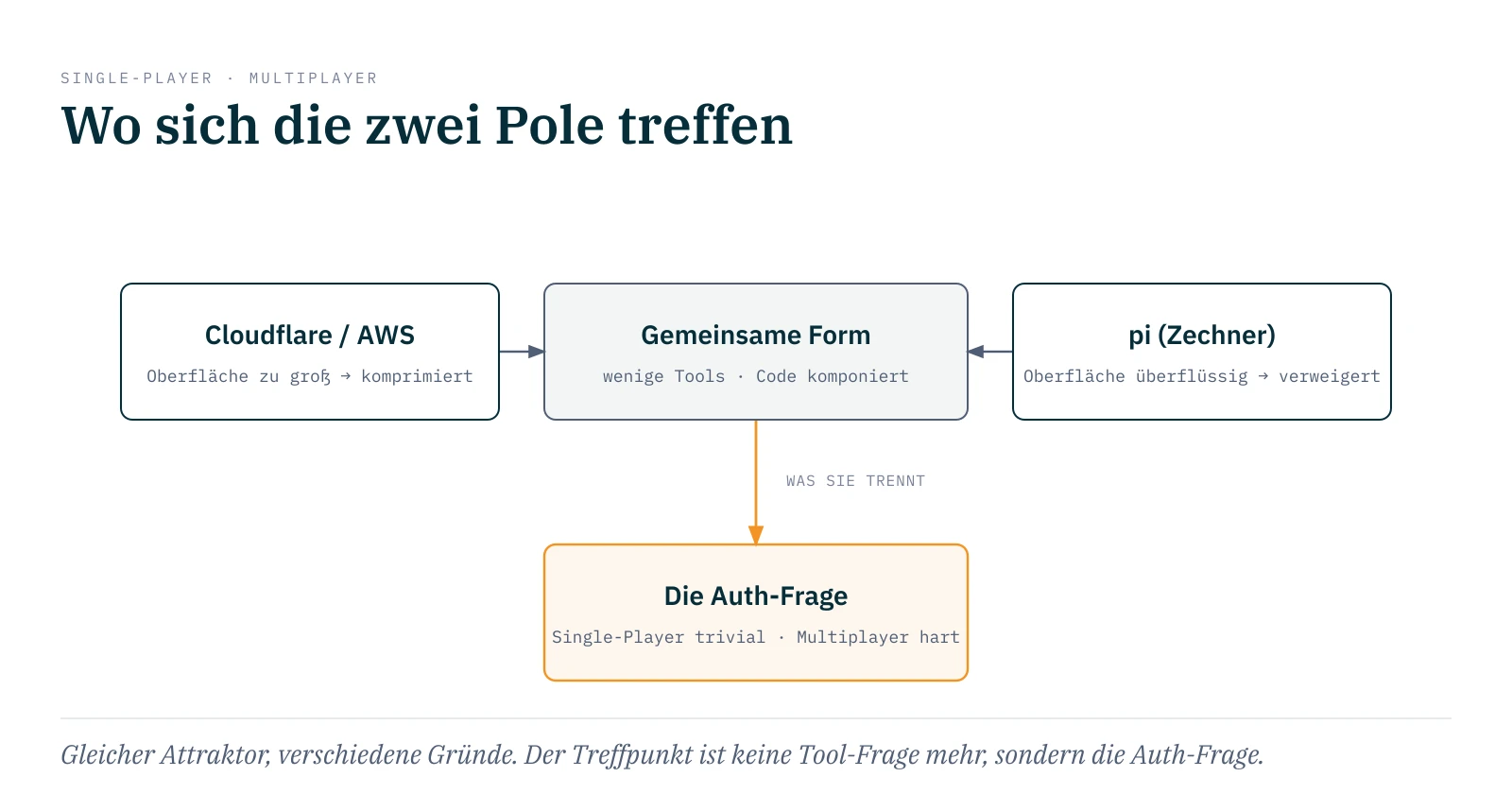
Cloudflare und pi konvergieren also in der Form: wenige Tools, Code oder Shell macht die Komposition, das Modell sieht eine schmale Naht. Aber sie konvergieren nicht im Motiv. Cloudflare komprimiert, weil die Oberfläche zu groß zum Exponieren ist. pi verweigert, weil die Oberfläche überflüssig ist. Gleicher Attraktor, verschiedene Gründe. Und der Attraktor selbst ist auffällig stabil: Cloudflares search/execute, AWS' call_aws/run_script, pis vier Tools plus bash. Es scheint, als gäbe es pro Ökosystem einen natürlichen Tiefpunkt von zwei bis vier Primitiven, an dem sich die Oberfläche stabilisiert.
Die Frage ist, was die beiden Pole unterscheidet, wenn die Form schon dieselbe ist. Die Antwort ist Identität und Authentifizierung. pi läuft Single-Player: eine Person, eine Maschine, die Auth ist trivial, weil der Nutzer ohnehin alle Rechte hat. In dieser Welt genügt eine CLI mit einem Skill, und die Komposition läuft über Shell-Pipes, ganz ohne Protokoll. Die Hyperscaler laufen Multiplayer: viele Nutzer, fremde Systeme, delegierte Rechte. Hier ist die Auth nicht trivial, sie ist das eigentlich harte Problem, und genau dafür trägt ein Protokoll wie MCP sein Gewicht. Der Treffpunkt der zwei Pole ist also keine Tool-Frage mehr, es ist die Auth-Frage.
Genau hier sitzt Zechners schärfstes Argument gegen MCP, und es ist präziser als die übliche Token-Kritik. MCP sei nicht komponierbar: Die Information, die ein Tool liefert, muss durch den Kontext des Modells laufen, um mit der Information eines zweiten Tools kombiniert zu werden. Bei einer Shell-Pipe fließt sie direkt weiter, das Modell sieht nur das Ergebnis.12 Für den Single-Player-Fall ist das ein klarer Gewinn. Für den Multiplayer-Fall bleibt eine offene Lücke: eine Fassade, die mehrere fremde Backends mit je eigener Auth zu einer Domänen-Operation verkettet, deterministisch im Code statt durch den Modell-Kontext. Diese semantische Komposition über Auth-Grenzen hinweg ist mir Anfang 2026 als fertiges Produkt nirgends begegnet. Es ist der Punkt, an dem die zwei Pole für den Enterprise-Fall noch nicht zusammengefunden haben.
Eine Präzisierung, damit das nicht zu glatt klingt: Zechners "kein MCP" trifft MCP als Kontext-Exposition, also die Tool-Schemas, die ins Modell wandern. Es trifft nicht zwingend MCP als reines Draht- und Auth-Protokoll, das auch im Code-Pfad leben kann, ohne den Kontext zu belasten. Die beiden Schichten sind getrennt zu bewerten. Der Single-Player-Pol kommt ohne beide aus. Der Multiplayer-Pol braucht die zweite, will aber die erste genauso vermeiden.
Wir betreiben einen MCP-Server für Pipedrive. Fünfundfünfzig Tools. Kontakte suchen, Deals anlegen, Aktivitäten tracken, Organisationen anreichern, Filter abfragen, Felder auflösen.
Das ist nicht zweitausendfünfhundert. Aber es ist genug, um den Effekt auf der Kardinalitätsachse zu spüren. Und es zeigt ein spezifischeres Problem, das über die reine Anzahl hinausgeht: get_person, search_persons, get_persons_by_filter, find_persons_by_name sehen aus wie vier Tools für eine einzige semantische Operation "finde eine Person im CRM". Vorsichtig muss ich trotzdem sein, denn die vier Namen können unterschiedliche Constraints kodieren: exakte ID, Fuzzy-Suche, gespeicherter Filter, Namenssuche. Ob sie sich wirklich auf wenige Primitive zusammenziehen lassen, ist eine Design-Hypothese, kein gemessenes Ergebnis.
Die komprimierte Version wäre vermutlich: search, read, write. Alles andere, welche Entity, welche Felder, welche Filter, wäre Parameter, nicht Tool-Auswahl.
Ob wir umbauen, ist offen. Die fünfundfünfzig Tools haben präzise Beschreibungen, und die Agenten finden das Richtige. Aber die Frage "Könnten drei Tools dasselbe leisten, und könnten sie strukturiertere Antworten zurückgeben?" steht im Raum. Und sie wird relevanter, je mehr Agenten gleichzeitig darauf zugreifen.
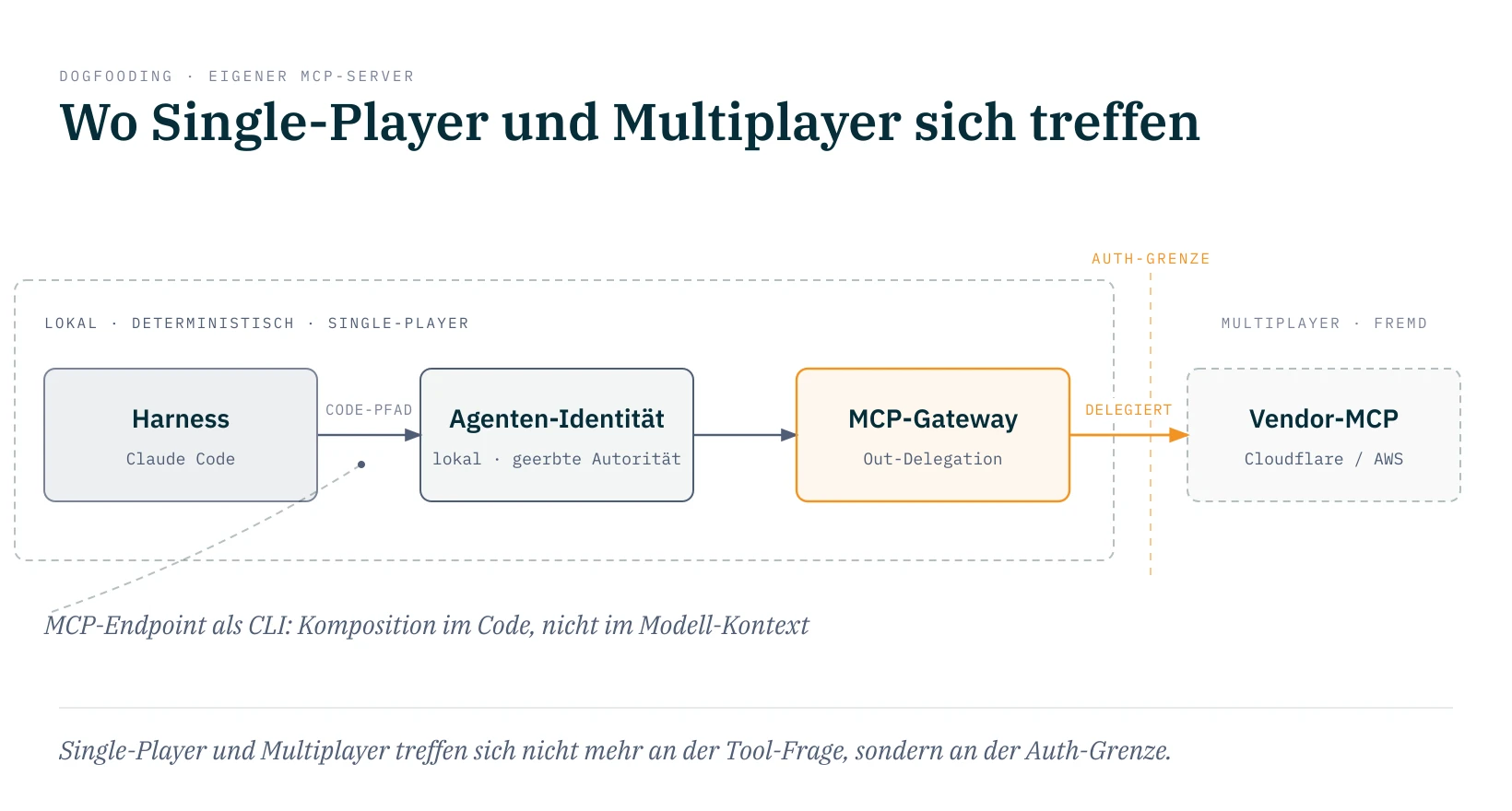
Eine zweite Beobachtung kommt aus der Entwicklung selbst. Einen MCP-Server im Dev-Roundtrip neu zu starten ist teuer, und je mehr davon ich gebaut habe, desto öfter bin ich darüber gestolpert. Auf der Suche nach einer billigeren Schleife bin ich auf eine Brücke gestoßen: kleine Tools, die einen MCP-Endpoint und seine Tools über einen CLI-Aufruf kapseln. Damit liegt der MCP-Server als Kommandozeilen-Werkzeug vor: Er bleibt der standardisierte Zugang zur fremden API, die ich nur einmal anbinde, aber die Komposition wandert aus dem Modell-Kontext in den Code-Pfad. Genau hier wird Zechners Shell-Argument konkret. Sein Punkt war, dass MCP nicht komponierbar ist, weil die Information durch den Modell-Kontext laufen muss; ein MCP-Endpoint, der als CLI verfügbar ist, fließt stattdessen durch eine Pipe, und das Modell sieht nur das Ergebnis.12
Das nutzen wir inzwischen an mehreren Stellen. Für unsere Website-Analytics binden wir Plausible, die Google Search Console und LinkedIn jeweils über MCP an, sprechen sie aber im Code-Pfad über die CLI an: die Fakten werden deterministisch eingesammelt und abgelegt, und erst die Aufbereitung zum Report kostet Tokens. Dasselbe Muster trägt unsere Monatsreports in den Professional Services, wo Zeiterfassung und Rechnungssoftware im Code zusammenlaufen und der Agent nur die kundenspezifische Form des Reports übernimmt, und unsere Lead-Recherche, wo strukturierte Shop- und Technologiedaten im Code-Pfad zusammengestoppelt und über den Pipedrive-MCP in die Kategorisierung eingezahlt werden. Die Komposition bleibt im Code, deterministisch und billig; probabilistisch ist nur die Entscheidung am Ende.
Daraus ist eine Idee geworden, die ich gerade als Emergent Design verfolge, ohne schon zu wissen, was am Ende daraus wird. Hier ließen sich die Single-Player- und die Multiplayer-Seite zusammenführen. Die Out-Strecke ab einem Vendor-MCP wie Cloudflare oder AWS deckt deren eigener Server ohnehin ab. Was fehlt, ist die Strecke davor: von meinem Harness, etwa Claude Code, über eine lokale Workflow- oder Agenten-Identität hin zu diesen fremden Backends. Diese Strecke könnte über einen MCP-Gateway laufen, der die Delegation nach außen übernimmt, und nach und nach hinter eine MCP-Fassade wandern. Das ist genau die semantische Komposition über Auth-Grenzen, die ich weiter oben als offene Lücke benannt habe, nur dass ich sie hier an mir selbst ausprobiere, statt auf ein Produkt zu warten. Wie ein Agent sich dabei gegenüber fremden Backends ausweist und welche Autorität er vom Nutzer erbt, ist allerdings ein eigenes Fass. Das mache ich hier bewusst nicht auf, dafür sammle ich gerade Material für einen Artikel mit genau diesem Fokus.
Das war ein konkreter Aufbau aus der Praxis. Zurück zum Prinzip, denn eine Dimension fehlt noch: die Zeit. Tool-Surface-Kompression ist eine Design-Zeit-Entscheidung: Welche Tools baue ich überhaupt? Wie viele, wann sichtbar, in welcher Form?
Aber Kompression allein reicht nicht. Es gibt einen komplementären Laufzeit-Mechanismus. Boden Fuller beschreibt ihn als eine Phase seines "Context Development Life Cycle", die er Compile nennt:13 ein Context-Compiler wählt die richtigen Stücke für die aktuelle Phase aus, rankt sie nach Nutzen und Frische, trimmt auf das Token-Budget und liefert den minimal tragfähigen Kontext. Die Research-Phase braucht andere Tools als die Writing-Phase. Ein Compiler, der das pro Phase entscheidet, ist das Laufzeit-Gegenstück zu dem, was ich beim Design einplane.
Fullers zugespitzte These, von ihm ausdrücklich als Schätzung und nicht als Messung formuliert: Hier, bei der Laufzeit-Selektion, liege rund 99 Prozent des Abstands zwischen Teams, die Coding-Agenten nutzen, und Teams, die mit Coding-Agenten zuverlässige Ergebnisse erzielen.13
Design-Zeit und Laufzeit sind komplementär, nicht konkurrierend. Ich komprimiere die Oberfläche, der Compiler wählt pro Phase aus, was davon geladen wird.
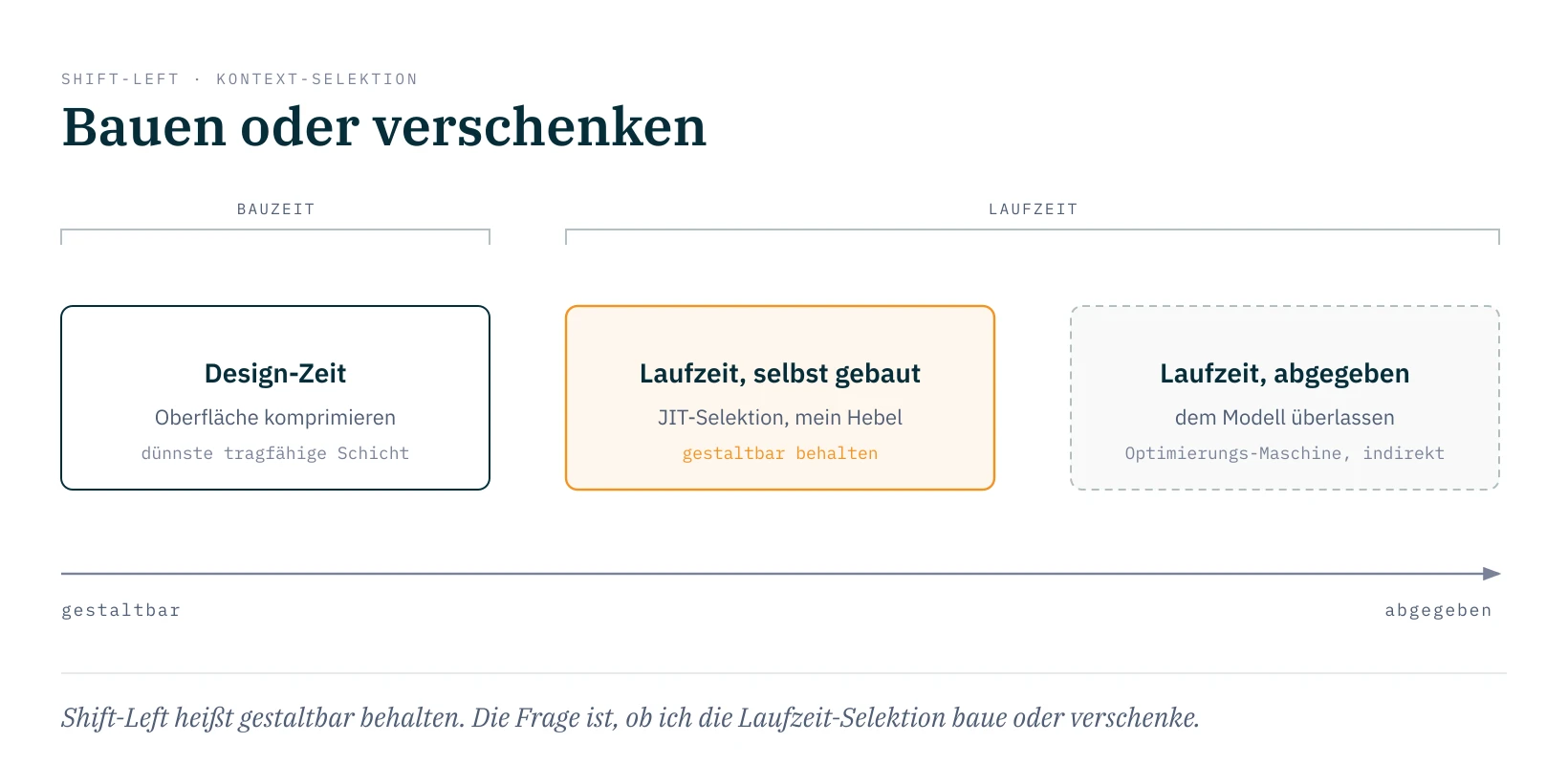
Im Grunde ist das das Shift-Left-Muster der Softwareentwicklung, auf den Kontext übertragen: je mehr ich zur Bauzeit kläre, desto weniger muss zur Laufzeit ausgehandelt werden. Ein Modell, das erst zur Laufzeit aus fünfzig Tools das richtige greifen soll, kann sich verheddern und seine Prioritäten durcheinanderbringen. In die Design-Zeit dagegen kann ich beliebig viel Mühe stecken, um die dünnste tragfähige Schicht herauszuarbeiten, bevor überhaupt etwas läuft.
Shift-Left heißt hier aber nicht nur früher, sondern gestaltbar behalten. Fullers Laufzeit-Selektion erinnert an einen Just-in-Time-Compiler: sie optimiert pro Phase nach dem, was sich erst zur Laufzeit zeigt. Und wie beim JIT hängt alles daran, wem die Maschine gehört. Baue ich diese Selektion selbst, ist sie mein Hebel. Überlasse ich sie dem Modell, das im Eigenlauf entscheidet, was gerade wichtig ist, habe ich sie an eine Optimierungs-Maschine abgegeben, die ich nur noch indirekt beeinflusse. Was die Bauzeit nicht abfängt, sind ohnehin die unknown unknowns: was in einer konkreten Phase relevant wird, lässt sich nicht vollständig vorhersehen, und genau dafür braucht es die Laufzeit-Selektion. Die Frage ist nur, ob ich sie baue oder verschenke.
Es hilft, das alles in eine größere Disziplin einzuordnen. Andrej Karpathy hat den Begriff "Context Engineering" 2025 als Gegengewicht zu "Prompt Engineering" prominent gemacht:14 nicht einzelne Prompts optimieren, sondern den gesamten Kontext aktiv gestalten, der einem Agenten zu einem bestimmten Zeitpunkt zur Verfügung steht.
MCP ist inzwischen Infrastructure-Tier. Die Übergabe an die Linux Foundation Ende 2025 und die breite Adoption über die großen Toolchains hinweg machen das deutlich. Das ist kein Startup-Feature mehr.
Tool-Surface-Kompression ist der Design-Zeit-Anteil der Compression-Dimension innerhalb von Context Engineering. Progressive Disclosure (Timing-Achse) ist der On-Load-Anteil. Der Context-Compiler (Laufzeit) ist der Per-Phase-Selektions-Anteil. Drei verschiedene Hebel an derselben Herausforderung, wie viele nützliche Informationen in das begrenzte Kontext-Fenster passen.
Hier ist das Limit des statischen Designs, und es ist nötig, es zu nennen.
Selbst ein perfekt komprimiertes Drei-Tool-System degradiert über eine lange Session. Rohe Tool-Ausgaben akkumulieren im Kontext: Grep-Dumps, Stack-Traces, JSON-Fragmente. Das Signal-Rausch-Verhältnis sinkt. Wąsowski nennt das "Context-Rot"6, und es ist zeitlich, nicht räumlich. Es ist nicht das "Lost in the Middle"-Problem (der Kontext ist zu groß), sondern das Degradierungs-Problem (der Kontext war gut und ist es jetzt nicht mehr).
Eine Chroma-Studie von 2025 testete 18 Frontier-Modelle und fand, dass alle mit wachsender Eingabelänge schlechter werden, mit dem steilsten Abfall im Bereich von 100.000 bis 500.000 Tokens, also lange vor dem deklarierten Ende ihres Context-Window.15
Die Mitigation ist strukturell: atomare Tasks, Subagenten mit frischen Context-Windows. Ein Research-Subagent exploriert, gibt eine kompakte Zusammenfassung zurück, und isoliert den Token-Burn. Die Kompression der Tool-Oberfläche ist notwendig, aber nicht hinreichend. Context-Rot erfordert eine Architektur-Entscheidung auf einer anderen Ebene.
Es gibt noch eine Konsequenz, die über Token-Budgets hinausgeht.
Ein Google-Research-Blog-Post von 2026 zu Agent-System-Skalierung beschreibt eine Tool-Koordinations-Steuer, die mit der Tool-Dichte überproportional wächst, und nennt als Beispiel einen Coding-Agenten mit sechzehn oder mehr Tools, ab dem das Koordinieren mehrerer Agenten teurer wird als der Parallelisierungsgewinn.16 Das passt zu Mark Burgess' Promise-Theory-Argumenten, die O(N²)-Wachstum für Koordinations-Overhead bei dicht vernetzten Systemen vorhersagen.
Das bedeutet: Tool-Sprawl kostet nicht nur mehr Tokens, er kann unter festem Compute-Budget auch in schlechtere Multi-Agent-Architekturen drängen. Sechs Tools koordinieren sich noch relativ einfach. Dreißig Tools verlangen eher Orchestrierungs-Layer, die selbst wieder Kontext verbrauchen.
Die Sechzehn ist ein illustratives Beispiel, kein gemessener Schwellenwert, und sie ist coding-domain-spezifisch. Ich würde sie nicht auf andere Domains generalisieren. Aber die Richtung stimmt.
Ich will das Bild nicht zu rosig malen. Eine Studie von Galster, Treude, Baltes et al. an 2.853 GitHub-Repositories fand laut zugeschriebener Aussage, dass die meisten Repos bei statischen AGENTS.md-Dateien stehenbleiben und nie zu Skills, Subagenten oder Kompression weitergehen.17
Das heißt nicht, dass der Ansatz falsch ist. Es heißt, dass wer das jetzt aufbaut, einen Vorsprung hat, den die meisten noch nicht haben. Das ist kein Scorecard, es ist eine Einschätzung des aktuellen Stands des Feldes.
Tool-Surface-Kompression ist kein MCP-spezifisches Detail. Es ist dieselbe Intuition wie Harness Engineering, nur auf einer anderen Abstraktionsebene. Harness Engineering beschränkt die Organisationsstruktur: Wie zerlegt der Agent Arbeit, wie verifiziert er Ergebnisse? Tool-Surface-Kompression beschränkt die Werkzeugoberfläche: Was sieht der Agent überhaupt? Beides folgt demselben Grundprinzip: Agenten brauchen engere Constraints, nicht mehr Kapazität.
Was mich beim Schreiben am meisten überzeugt hat, ist die Konvergenz selbst. Ein minimaler Single-Player-Harness wie pi und ein Multiplayer-Enterprise-Produkt wie der AWS MCP Server haben fast nichts gemein, außer dem Ergebnis: wenige Primitive, Code macht die Komposition, das Modell sieht eine schmale Naht. Sie kommen von entgegengesetzten Enden und treffen sich in der Mitte. Der eigentliche Unterschied am Treffpunkt ist nicht mehr die Tool-Frage, die ist auf beiden Seiten gelöst, sondern die Auth-Frage: Single-Player kommt ohne Protokoll aus, Multiplayer braucht eines. Alles andere, die drei Achsen Kardinalität, Timing und Struktur, ist die Mechanik dieser Bewegung, nicht ihr Ziel. Die Oberfläche bewegt sich, und sie bewegt sich von beiden Seiten auf denselben Punkt zu.
Die Struktur-Achse hat mich dabei am meisten überrascht. Ich war davon ausgegangen, dass die Frage "wie viele Tools?" die entscheidende ist. LSP-artige strukturierte Abfragen statt roher File-Dumps zu liefern, ist eine Antwort auf eine andere Frage: nicht wie viele, sondern in welcher Form. Das ist für mich die neue Designentscheidung bei jedem MCP-Server.
Wenn du heute einen MCP-Server planst, würde ich mit drei Fragen starten:
Was sind die drei primitivsten Operationen in dieser Domain? Für ein CRM: Suchen, Lesen, Schreiben. Für ein Monitoring-System: Abfragen, Filtern, Aggregieren. Für ein Deployment-System: Planen, Ausführen, Beobachten.
Könnten die Tools strukturierte Antworten zurückgeben statt roher Dumps? Statt "gib mir alle Zeilen, die foo enthalten" eher "gib mir die Signatur von foo und die drei Stellen, die sie aufrufen".
Wann sollen welche Tools sichtbar sein? Braucht jeder Task jedes Tool, oder gibt es eine sinnvolle Progressive-Disclosure-Logik?
Viele bestehende MCP-Server wirken so, als hätten sie zu viele Tools, weil jeder Endpoint zum Tool wurde, ohne dass jemand gefragt hat, ob das die richtige Granularität ist. Die Designs wurden für Menschen gebaut, die Menüs durchsuchen, nicht für Agenten, die Token-Budget verwalten.
Für neue MCP-Server: Startet mit Primitiven, nicht mit Endpoints. Die Struktur der Antworten gestalten, nicht nur die Anzahl der Tools zählen. Den Context-Compiler als Laufzeit-Gegenstück einplanen.
Dieser Post ist Teil einer Serie über AI und Software-Architektur. Die vorherigen Teile behandeln die Fünf Stufen der KI-Entwicklung, Dark Factory Architektur, den Dark Factory Gap, Conway's AI-Inverse und Harness Engineering.
Die Kernthese, Tool-Surface-Kompression als Designprinzip, entstand aus dem Cloudflare-Muster und der eigenen Erfahrung mit einem 55-Tool-MCP-Server für Pipedrive. Die zwei Cloudflare-Quellen (2, 1) wurden direkt gegen die offiziellen Blog-Posts von blog.cloudflare.com verifiziert.
Die neueren Befunde (drei Achsen, Context-Rot, LSP-Abfragen, Context-Compiler, Tool-Koordinations-Steuer, Adoption-Gap) stammen aus unserem Content-Wiki. Die Quellen-URLs sind ergänzt und die zentralen gegen die Primärtexte geprüft: die CDLC-99%-Aussage (Fuller, 13), die Studie über 2.853 Repositories (Galster et al., 17), der Google-Skalierungs-Post (16, dessen Sechzehn-Tool-Beispiel ich bewusst als illustrativ und nicht als gemessenen Schwellenwert wiedergebe), das pi.dev-Progressive-Disclosure-Zitat (5) sowie Context-Rot und die LSP-Mechanik gegen Wąsowskis Volltext (6). Die Chroma-Studie (15) ist inzwischen direkt gegen die Quelle geprüft. Zugeschrieben und bewusst vorsichtig formuliert bleibt Karpathys Rolle beim Begriff (14): popularisiert, nicht zwingend erstgeprägt. Die Multiplikatoren, die eine frühere Fassung trug (Progressive Disclosure, LSP), habe ich auf qualitative Aussagen zurückgenommen, weil die Quellen die Mechanik stützen, nicht die konkreten Faktoren.
Die Zwei-Pole-These (pi als Single-Player-Minimal gegen die Hyperscaler als Multiplayer-Enterprise, Treffpunkt an der Auth-Frage) kam im Juni 2026 dazu, nachdem ich Zechners Blog-Post (3) und das Syntax-Podcast-Gespräch (12) gesichtet und im Wiki inkorporiert habe. Beide Quellen sind gegen ihre Primärtexte geprüft, der „nicht komponierbar"-Punkt wörtlich gegen das Transkript. Die Lücke der semantischen Komposition über Auth-Grenzen ist eine eigene Einschätzung aus der Wiki-Arbeit, kein zitierter Produktbefund.
Den ersten Entwurf hat ein Blog-Writer-Agent auf Claude Sonnet 4.6 gebaut, die heutige Fassung habe ich über viele Runden mit Claude Opus 4.8 herausgearbeitet. Dass die Texte nach mir klingen, ist erarbeitet: Das Modell draftet in einer Stimme und nach Maßstäben, die ich ihm Stück für Stück beigebracht habe. Idee, Argumentation und Gewichtung sind meine, das Modell ist das Werkzeug, das mir hilft, es umzusetzen.
Den vollständigen Workflow beschreibe ich in AI-gestützte Wissensarbeit: Wie ich meinen Recherche- und Schreibprozess neu aufbaue.
Cloudflare (2026). Code Mode: the better way to use MCP. Cloudflare Blog. blog.cloudflare.com/code-mode ↩︎ ↩︎
Cloudflare (2026). Code Mode: give agents an entire API in 1000 tokens. Cloudflare Blog. blog.cloudflare.com/code-mode-mcp ↩︎ ↩︎
Zechner, M. (2025). What I learned building an opinionated and minimal coding agent. mariozechner.at, 30. November 2025. Vier Tools (read/write/edit/bash), System-Prompt plus Tool-Definitionen unter tausend Tokens, „pi does not and will not support MCP", die CLI-mit-README-Progressive-Disclosure-Alternative; gegen den Volltext geprüft. ↩︎ ↩︎ ↩︎
Der Begriff ist in der MCP-Community etabliert. Atlassian, MCP Compression: Preventing Tool Bloat in AI Agents atlassian.com, mit dem Open-Source-Tool atlassian-labs/mcp-compressor (70 bis 97 Prozent weniger Tool-Definition-Tokens). Microsoft Research (2025), Tool-space Interference in the MCP Era microsoft.com: die Trefferquote sinkt mit der Tool-Anzahl, OpenAI rät zu unter zwanzig Funktionen. Beide gegen die Quelle geprüft. ↩︎ ↩︎
Zechner, M. (2026). Pi Documentation: Skills (Progressive Disclosure). pi.dev/docs/latest/skills, Zitat „only descriptions are always in context, full instructions load on-demand", gegen die Quelle geprüft. ↩︎ ↩︎
Wąsowski, J. (2026). Managing Agent Context at Every Stage of the SDLC. Medium, April 2026. medium.com, Origin von Context-Rot und der LSP-Pointers-over-Copies-Mechanik, gegen den Volltext geprüft. ↩︎ ↩︎ ↩︎
Tool-Belege. Serena (oraios), github.com/oraios/serena, exponiert LSP-Operationen (Go-to-Definition, Find-References, Rename) als Symbol-Tools über 40+ Sprachen. CodeGraph (colbymchenry), github.com/colbymchenry/codegraph, vorab-indizierter Code-Knowledge-Graph via MCP (rund 16% günstiger, rund 58% weniger Tool-Calls). Beide READMEs und Agent-Evals gesichtet. ↩︎
Kim, M. et al. (2026). CODESTRUCT: Code Agents over Structured Action Spaces. arXiv:2604.05407, named AST entities statt text-spans, 12 bis 38 Prozent weniger Tokens auf SWE-Bench Verified; gegen das Paper geprüft. ↩︎
Vogel, M. et al. (2026). Codebase-Memory: Tree-Sitter-Based Knowledge Graphs for LLM Code Exploration via MCP. arXiv:2603.27277, Tree-Sitter-Knowledge-Graph via MCP, zehnfach weniger Tokens über 31 Repositories; gegen das Paper geprüft. ↩︎
AWS (2026). The AWS MCP Server is now generally available. AWS News Blog, 6. Mai 2026. aws.amazon.com. Tool-Namen (call_aws, search_documentation, read_documentation, run_script), die 15.000-API-Operationen-Zahl und die Frankfurt-Region gegen den Volltext geprüft. ↩︎
Microsoft Azure Skills Plugin (März 2026). Primärquelle github.com/microsoft/azure-skills, gegen die README geprüft: 200+ strukturierte Tools, 40+ Azure-Services und die benannten Skills (azure-prepare, azure-validate, azure-deploy, azure-diagnostics, azure-cost). Die in der Presse genannte Zahl „mehr als 19 Skills" stammt aus Ramel, D., Microsoft Launches Azure Skills Plugin, Visual Studio Magazine, 13. März 2026 visualstudiomagazine.com; die README nennt keine Gesamtzahl. ↩︎
Bos, W. & Tolinski, S. (2026). Pi: The AI Harness That Powers OpenClaw, mit Armin Ronacher & Mario Zechner. Syntax Podcast #976, 4. Februar 2026. syntax.fm. Zitate „bash is all you need" und „it's not composable, everything has to go through the context of the LLM ... shell scripts ... are far superior to MCP" (Zechner); gegen das Transkript geprüft. ↩︎ ↩︎ ↩︎ ↩︎
Fuller, B. (2026). CDLC: Context Development Life Cycle. bodenfuller.com, die 99%-Aussage und die Select/Rank/Trim/Deliver-Phasen sind gegen die Quelle geprüft. ↩︎ ↩︎ ↩︎
Karpathy, A. (2025). Context Engineering. Zugeschriebene Aussage; Karpathy hat den Begriff 2025 prominent gemacht, die Erstprägung ist nicht eindeutig ihm zuzuordnen. ↩︎ ↩︎
Chroma (2025). Context Rot: How Increasing Input Tokens Impacts LLM Performance. trychroma.com, 18 Modelle, monoton sinkende Performance mit der Eingabelänge; gegen die Chroma-Seite geprüft. ↩︎ ↩︎
Google Research (2026). Towards a Science of Scaling Agent Systems: When and Why Agent Systems Work. research.google, die Sechzehn-Tools-Marke steht dort als illustratives Beispiel der Koordinations-Steuer, nicht als gemessener Schwellenwert (gegen die Quelle geprüft). ↩︎ ↩︎
Galster, M. et al. (2026). Configuring Agentic AI Coding Tools: An Exploratory Study. arXiv:2602.14690. arXiv, 2.853 GitHub-Repositories, acht Konfigurationsmechanismen; Titel, Autoren und Repo-Zahl gegen das Abstract geprüft. ↩︎ ↩︎
Lerne, wie man KI in Codeprojekte integriert, um effizienter zu arbeiten und innovative Lösungen zu schaffen.
Vor zwei Wochen habe ich darüber geschrieben, was sich ändert, wenn das Modell gleich bleibt und nur der Harness wechselt. Kurzfassung: der Wrapper macht mehr
Diese Woche habe ich denselben Coding-Task durch vier AI-Coding-Tools laufen lassen – opencode, Pi, GitHub Copilot in VS Code und Claude Code –, alle
Wenn Sie bereits Nomad- und Vault-Patterns in Produktion betreiben, ist die erste Frage zu OpenBao einfach: laufen unsere bestehenden Workloads ohne Rewrite
Als wir unseren Beitrag HashiCorp Nomad and Vault: Dynamic Secrets veroeffentlichten, lief die Demo ausschliesslich als Python Flask-Anwendung. Seitdem ist das
Im vorigen Artikel, Tool-Surface-Kompression, ging es um die Frage, wie man externe Funktionalität, ganze APIs und Systeme, möglichst token-effizient in den
Sie interessieren sich für unsere Trainings oder haben einfach eine Frage, die beantwortet werden muss? Sie können uns jederzeit kontaktieren! Wir werden unser Bestes tun, um alle Ihre Fragen zu beantworten.
Hier kontaktieren