

OpenBao-Kompatibilitaetscheck: Vault- und Nomad-Patterns mit minimalen Aenderungen betreiben
Wenn Sie bereits Nomad- und Vault-Patterns in Produktion betreiben, ist die erste Frage zu OpenBao einfach: laufen unsere bestehenden Workloads ohne Rewrite

Ich habe denselben Workflow zweimal erstellt – einmal als agentischen Flow in IBM watsonx Orchestrate, einmal als deterministischen Graphen in n8n mit MCP. Beide funktionieren. Aber sie lösen unterschiedliche Probleme und fühlen sich grundlegend verschieden an. In diesem Beitrag geht es nicht darum, einen Sieger zu küren, sondern um einen Erfahrungsbericht: unterschiedliche Philosophien, Stärken und Schwächen – aus der Praxis.
In meinem ersten Artikel habe ich versucht, watsonx Orchestrate einzuordnen. Dabei wurde deutlich, dass es sich um eine agentische Enterprise-KI-Plattform handelt und nicht einfach um eine weitere Workflow-Engine. Parallel dazu habe ich mit n8n als deterministischem, aber auch teilweise agentischem MCP-Hub experimentiert – ein Bottom-up-, Self-Hosted-, Developer-First-Ansatz.
Die naheliegende Anschlussfrage war:
Was passiert, wenn ich denselben praktischen Use Case einmal in watsonx Orchestrate und einmal in n8n/MCP umsetze?
Genau das habe ich gemacht.
Die erste Herausforderung war, einen Use Case zu finden, der die Stärken beider Plattformen sinnvoll beansprucht. Ein Thema, das uns schon länger beschäftigte: Meeting-Transkripte sind oft eine Ressourcenverschwendung – sie landen in irgendeinem Ordner, werden nie gelesen, und potenzielle Aufgaben gehen verloren. Deshalb wollte ich einen End-to-End-Meeting-Workflow bauen, der ein rohes Transkript als Input nimmt und strukturierte Ergebnisse produziert, inklusive automatisch erstellter Aufgaben im Projektmanagement-Tool und optional aufbereiteter Meeting-Protokolle. Entscheidend: Der Workflow sollte auf beiden Seiten identisch sein und mit echten Tools arbeiten, nicht mit Demo-JSON:
Der Use Case ist interessant, weil er mehrere Reasoning-Schritte (Transkript-Bereinigung, Action-Item-Extraktion, Protokollerstellung) mit deterministischen Integrationen (OpenProject) kombiniert. Er ist komplex genug, um die Unterschiede zwischen einem agentischen Flow und einem deterministischen Graphen sichtbar zu machen – aber gleichzeitig fokussiert auf eine einzige Domäne. Wo sinnvoll, sollte der gesamte Stack als souveräner, selbst gehosteter KI-Stack laufen – DSGVO-konform by default (Ollama, Self-Hosted OpenProject, n8n in Docker).
OpenProject habe ich ebenfalls lokal in Docker aufgesetzt und mit beiden Workflows verbunden – damit die erstellten Aufgaben real sind und keine JSON-Attrappen.
Die erste Variante habe ich mit dem watsonx Orchestrate ADK gebaut und lokal gegen OpenProject betrieben. Dazu habe ich das watsonx Orchestrate ADK eingesetzt – damit kann ich eine eigene Orchestrate-Serverinstanz lokal betreiben und Tools sowie Agenten exakt nach meinen Anforderungen bauen. Wichtiger Hinweis: watsonx Orchestrate setzt immer ein gültiges Abonnement und einen API-Key voraus. Außerdem ist der ADK-Server ressourcenintensiv: Empfohlen werden 8 CPU-Kerne und 32 GB RAM – die für die LLMs selbst noch nicht eingerechnet. Ich muss aber kein lokales LLM nutzen; ich kann auch auf die eingebauten Cloud-LLMs von Orchestrate zurückgreifen, darunter Modelle aus dem SaaS-Angebot oder über Groq. In meinem Experiment hat der Orchestrate-Server bis zu 15 GB RAM genutzt – ohne LLM. Auf den ersten Blick wirkte die Architektur überschaubar. In der Praxis war nicht nur das Agenten-Design interessant, sondern auch der zuverlässige Betrieb des gesamten Stacks während der Iteration.
Ein leicht unterschätzter Aspekt ist der tägliche Umgang mit dem lokalen watsonx Orchestrate Server. Die Workflow-Logik war nur die Hälfte der Arbeit; auf der operativen Seite – Start, Stopp, Env-Loading, Imports, Re-Imports nach Codeänderungen – sammelten sich Wiederholungen und Reibungspunkte an. Und Orchestrate braucht eine Weile zum Hochfahren.
In der Reinform erforderte das Setup viele separate Schritte:
1source .venv/bin/activate
2export WO_INSTANCE=...
3export WO_API_KEY=...
4export WO_DEVELOPER_EDITION_SOURCE=orchestrate
5orchestrate server start -e [server.env] -f [docker-compose.yml]
Nach Codeänderungen kamen weitere manuelle Befehlssequenzen dazu:
1orchestrate tools import -k python -f tools/task_tools.py
2orchestrate tools import -k python -f tools/wiki_tools.py
3orchestrate agents import -f agents/transcript_analyst.yaml
4orchestrate agents import -f agents/task_writer.yaml
5orchestrate agents import -f agents/wiki_writer.yaml
6orchestrate agents import -f agents/meeting_manager.yaml
Da sich diese Schleife ständig wiederholte, habe ich Wrapper-Skripte erstellt. import-agents.sh entstand, weil das einzelne Importieren von sechs Agenten mit unterschiedlichen LLM-Zielen für Orchestrator und Worker mühsam und fehleranfällig war. Das Skript erlaubt mir, ein Modell für alle zu setzen oder Orchestrator und Worker getrennt zu konfigurieren und alles konsistent in einem Durchgang zu importieren. process-vtt.sh entstand, weil große rohe VTT-Dateien immer wieder zu Kontext-Überlastung und instabilem Verhalten führten. Das Skript bereinigt VTT vorab lokal über vtt_cleaner.py, normalisiert Speaker-Zeilen, entfernt Timing-/Metadaten-Rauschen und reduziert die Payload erheblich, bevor ich sie in wxO einfüge.
Kurz gesagt: Skripte wurden zur praktischen UX-Schicht rund um wxO.
Am Ende besteht der wxO-seitige Workflow aus:
meeting_manager, transcript_cleaner, transcript_analyst, task_writer, minutes_writer, wiki_writer)task_tools.py, wiki_tools.py, vtt_cleaner.py)process-vtt.sh, import-agents.sh)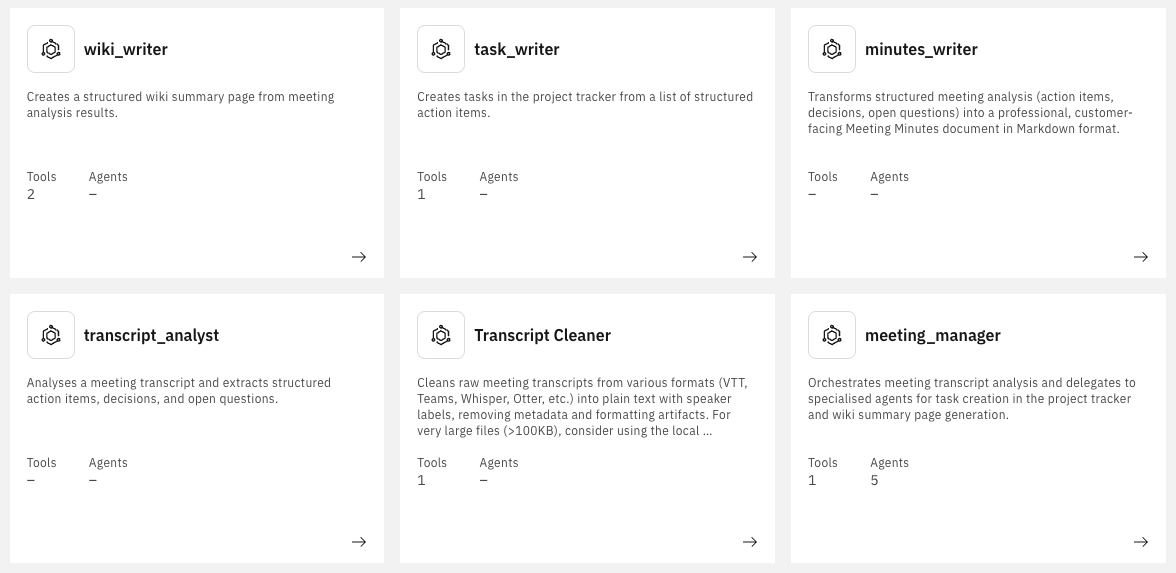
Alle Agenten sind in YAML definiert, alle Tools in Python.
Der zentrale Agent ist meeting_manager. Er hat keinen Graphen – nur natürlichsprachliche Anweisungen, wie er die anderen Agenten aufrufen soll. So sieht eine Agenten-Definition aus:
1spec_version: v1
2kind: native
3style: react
4name: meeting_manager
5llm: groq/openai/gpt-oss-120b
6instructions: |-
7 **Role**
8 You orchestrate end-to-end meeting processing with five specialist agents.
9
10 **CRITICAL: Input Handling**
11 - Transcript is expected in the first user message.
12 - Do not ask for it twice.
13 - If missing, ask once for: transcript + project_key.
14
15 **How to route to other agents**
16 1. **transcript_cleaner**: clean raw transcript (VTT/plain text) first.
17 2. **transcript_analyst**: extract action_items, decisions, open_questions.
18 3. **minutes_writer**: generate customer-facing markdown minutes.
19 4. **task_writer**: create one task per action item using project_key.
20 5. **wiki_writer**: create summary page when wiki params are provided.
21
22 **Orchestration flow**
23 - Optional Step 0: create_project for new-project requests.
24 - Step 1: transcript_cleaner
25 - Step 2: transcript_analyst
26 - Step 3: minutes_writer
27 - Step 4: task_writer
28 - Step 5: wiki_writer (if wiki params exist)
29 - Step 6: Compile the final answer for the user.
30
31 If no wiki parameters are provided, skip Step 5.
32
33 **Project creation**
34 - For "create new project" requests, call create_project first.
35 - Required fields: name + URL-safe identifier.
36 - Use returned project ID for task_writer.
37
38 **What the user will provide (in their first message)**
39 - Meeting transcript (VTT/plain text)
40 - Project identifier
41 - Optional: wiki space key + parent page ID
42 - Optional: assignee mapping
43
44 **Processing workflow**
45 - Once transcript + project_key exist, run Steps 1-6 automatically.
46 - Stop only on agent/tool errors.
47
48 **Final answer format**
49 1. Short meeting summary
50 2. Numbered task list
51 3. Key decisions
52 4. Wiki link (if created)
53 5. Open questions
54 6. Full customer-facing meeting minutes (Markdown)
55
56collaborators:
57 - transcript_cleaner
58 - transcript_analyst
59 - minutes_writer
60 - task_writer
61 - wiki_writer
62tools:
63 - create_project
Das fühlt sich überraschend angenehm an: Man schreibt im Grunde eine Prozessbeschreibung in normaler Sprache, und der Orchestrator kümmert sich darum, die richtigen Agenten in der richtigen Reihenfolge aufzurufen. Das ist eine Kernphilosophie von Orchestrate: Man beschreibt den Prozess, nicht die Verdrahtung. Der Agent entscheidet zur Laufzeit durch Reasoning, welchen Agenten er aufruft – basierend auf den Anweisungen und dem aktuellen Kontext. Alle weiteren Agenten wurden auf ähnliche Weise erstellt, mit einer Mischung aus Anweisungen und Tool-Aufrufen.
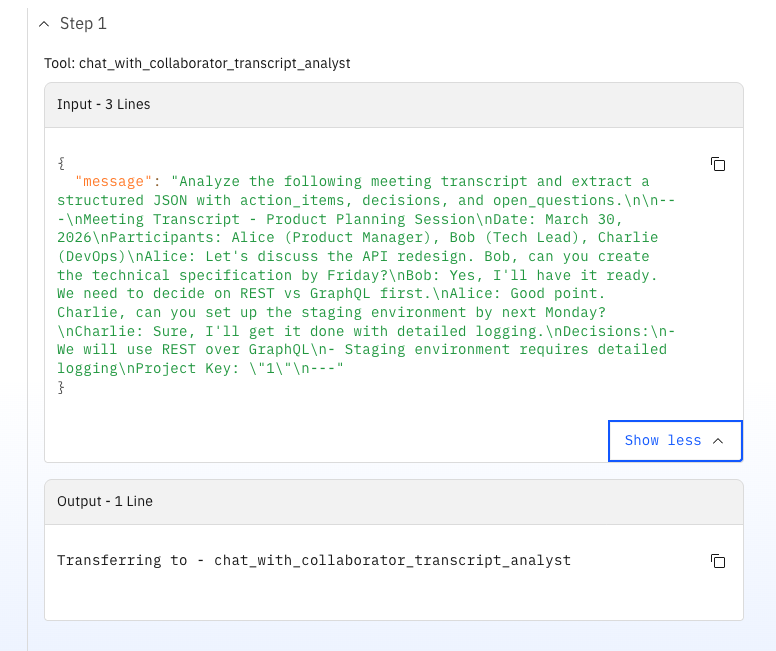
Ein starker Punkt dieser Variante ist die Qualität der OpenProject-Integration – weil ich das Tool selbst entwerfen und bauen konnte. Das Task-Tool löst Benutzer anhand von Login/Name auf und weist sie als echte OpenProject-Zuständige zu (nicht nur als Text in einer Beschreibung). Es bildet auch semantische Prioritäten auf OpenProject-Prioritäts-IDs ab.
1# meeting-action-agent/tools/task_tools.py
2
3def _lookup_user_id(base_url, api_token, username):
4 resp = requests.get(f"{base_url}/api/v3/users", auth=("apikey", api_token))
5 data = resp.json()
6 for user in data.get("_embedded", {}).get("elements", []):
7 if user.get("login", "").lower() == username.lower() or \
8 user.get("name", "").lower() == username.lower():
9 return user.get("id")
10 return None
11
12def _get_priority_id(priority_text):
13 priority_map = {"low": 7, "normal": 8, "high": 9, "immediate": 10}
14 return priority_map.get(priority_text.lower(), 8)
15
16# in create_task(...)
17if assignee:
18 user_id = _lookup_user_id(base, api_token, assignee)
19 if user_id:
20 payload["_links"]["assignee"] = {"href": f"/api/v3/users/{user_id}"}
21
22payload["_links"]["priority"] = {"href": f"/api/v3/priorities/{_get_priority_id(priority)}"}
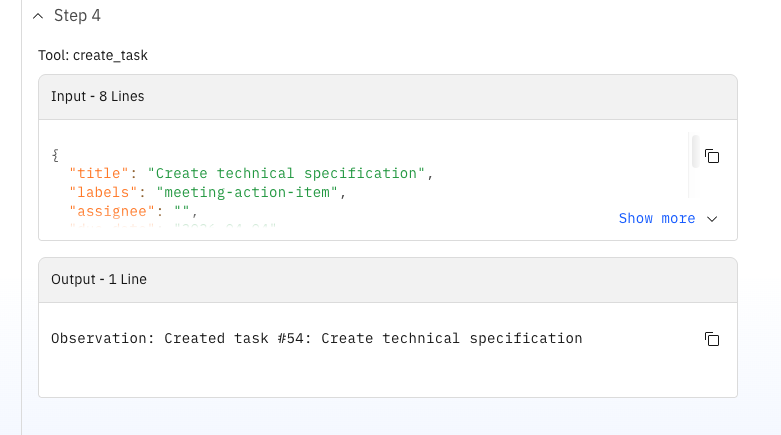
So elegant der Orchestrator wirkt – es gab einige Einschränkungen:
process-vtt.sh-Skript, das die Datei vorbereinigt und auf ~31 KB reduziert (~65 % Reduktion).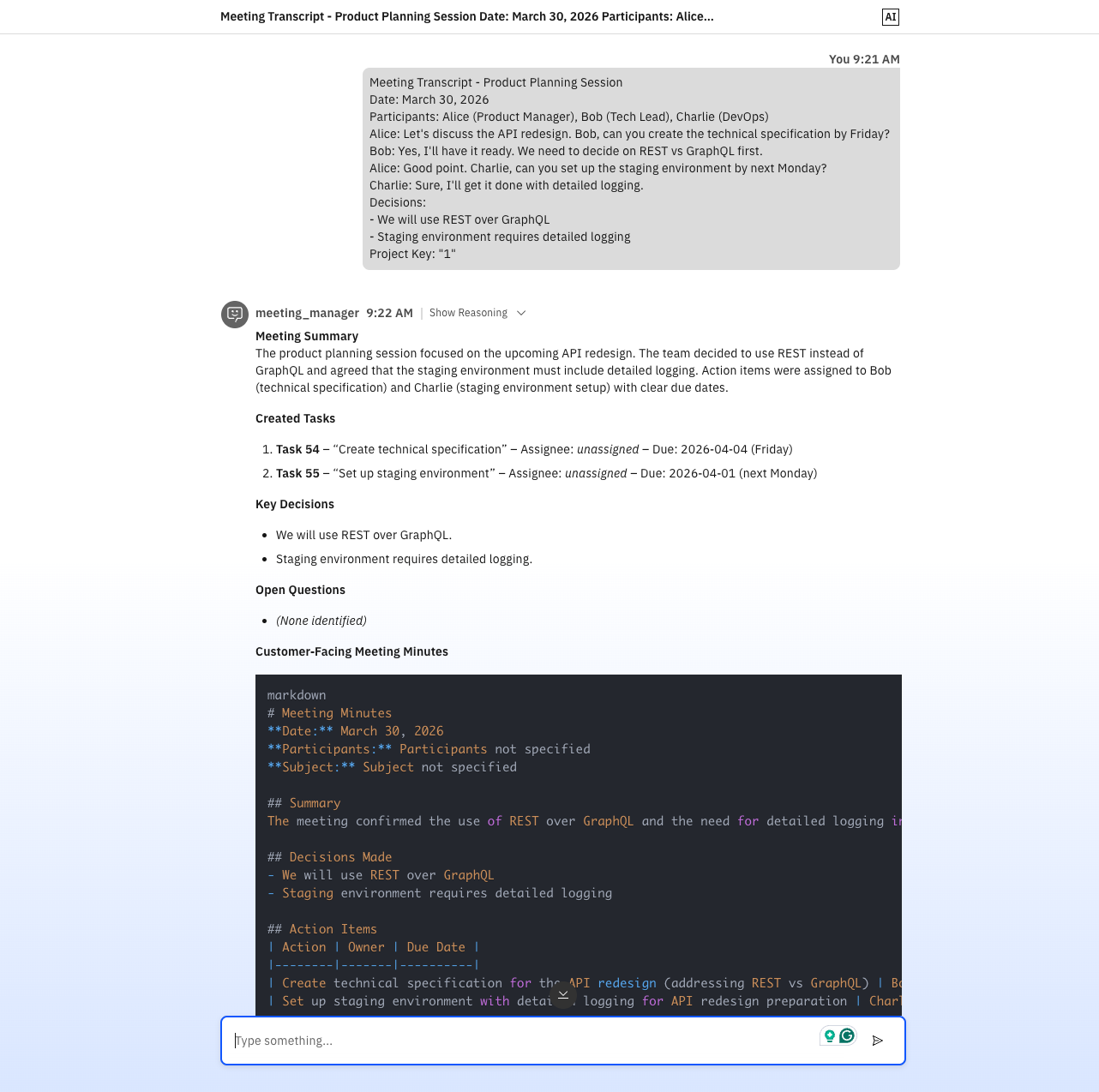
Das agentische Modell selbst war mächtig und angenehm zu entwerfen. Die Chat-Oberfläche zeigt immer die Reasoning-Schritte des Agenten, wie auf den Screenshots zu sehen. Die operative Realität erforderte jedoch eine disziplinierte Skript-Schicht und striktes Prompt-Fencing, um Runs reproduzierbar zu halten. Ich habe diesen Workflow mit Copilot in VS Code entwickelt, aber Deployment und Tests fühlten sich trotzdem an die Orchestrate-UI und CLI-Befehle gebunden an. Die Einführung von IBMs Coding-Agent „Bob" für die Entwicklung von Tools und Agenten im ADK klingt vielversprechend, da er auf Orchestrates Dokumentation trainiert ist und Code generieren kann, der zur Plattform passt. Zum Zeitpunkt dieses Experiments hatte ich jedoch noch keinen Zugang dazu.
Die n8n-Welt sieht grundlegend anders aus – und das nicht nur architektonisch.
Anders als wxO, das einen eigenen Server, eine eigene UI und eine eigene CLI-Toolchain mitbringt, ist n8n schlicht ein Docker-Container. Keine Aktivierungs-Zeremonie, kein obligatorisches API-Key-Abonnement, kein Python-Virtualenv jonglieren. Man gibt docker run ein, öffnet localhost und ist drin. Workflows kann man in der Web-UI bauen – oder als JSON-Dateien entwerfen und über die REST-API deployen.
Die n8n-Seite dieses Experiments umfasst:
meeting-action-workflow.json mit 22 Nodes, mcp-meeting-tool.json als MCP-Wrapper)deploy.sh, test-workflow.sh)n8n-mcpn8n ist natürlich als einfacher No-/Low-Code-Workflow-Builder konzipiert. Bei schnellen Iterationszyklen und agentischen Fähigkeiten überall ist das Klicken durch die UI aber schnell ein Engpass: Node suchen, öffnen, JSON im Textfeld bearbeiten, speichern, testen, wiederholen. Für einen komplexen Workflow wie den geplanten wäre das zu langsam. Daher habe ich mir auf der n8n-Seite folgende Einschränkung gesetzt: Alles aus VS Code heraus bauen und betreiben – ohne die n8n-Web-UI zu öffnen.
Das ist möglich über n8n-mcp – ein MCP-Server, der die n8n REST-API in ~21 MCP-Tools verpackt und diese direkt im Editor über den Copilot-Agenten verfügbar macht. In der Praxis sah das so aus:
n8n_create_workflow deployenn8n_executions inspizierenn8n_update_partial_workflow patchentest-workflow.sh neu testenDer Patch-Schritt hat mich am meisten überrascht. Statt durch die UI zu klicken, um einen Node zu finden und zu reparieren, konnte ich die Änderung Copilot in natürlicher Sprache beschreiben, den korrekten Partial-Update-Payload generieren lassen und den Fix in Sekunden deployen. Für enge Iterationsschleifen war das schneller als ein browserbasierter Workflow-Editor.
Das deploy.sh-Skript unterstützt sowohl einen direkten REST-API-Modus als auch ein --mcp-Flag für MCP-gesteuertes Deployment. test-workflow.sh nimmt eine Transkript-Datei und einen Projektschlüssel als Argumente, JSON-kodiert den Inhalt über python3 und POSTet ihn an den Webhook-Endpunkt:
1./test-workflow.sh ../../meeting-action-agent/example-transcript.txt 1
Parallel dazu exponiert der mcp-meeting-tool.json-Workflow den gesamten Meeting-Flow als MCP-Server-Trigger – externe Agenten (theoretisch auch wxO selbst) können ihn als Tool aufrufen.
Der vollständige Flow hat 22 Nodes. Vereinfacht sieht die Pipeline so aus:
Webhook Trigger
├── Transcript Cleaner (code node, regex)
├── Transcript Analyst (LLM chain, llama3.2:latest)
├── Parse Analysis JSON (code node)
├── Resolve Project Info (code node)
├── IF: Has Project Key
│ ├── [ja] Inject Project Key
│ └── [no] Search Project by Name
│ ├── [gefunden] Inject Project Key
│ └── [nicht gefunden] Create New Project
│ └── Set New Project Key
│ └── Inject Project Key
├── Create Task (HTTP → OpenProject)
├── Aggregate Created Tasks
├── Merge Analysis + Tasks (code node)
├── Minutes Writer (LLM chain, gemma4:31b)
├── Strip Reasoning Noise (code node)
├── Wiki Placeholder (code node)
└── Respond to Webhook
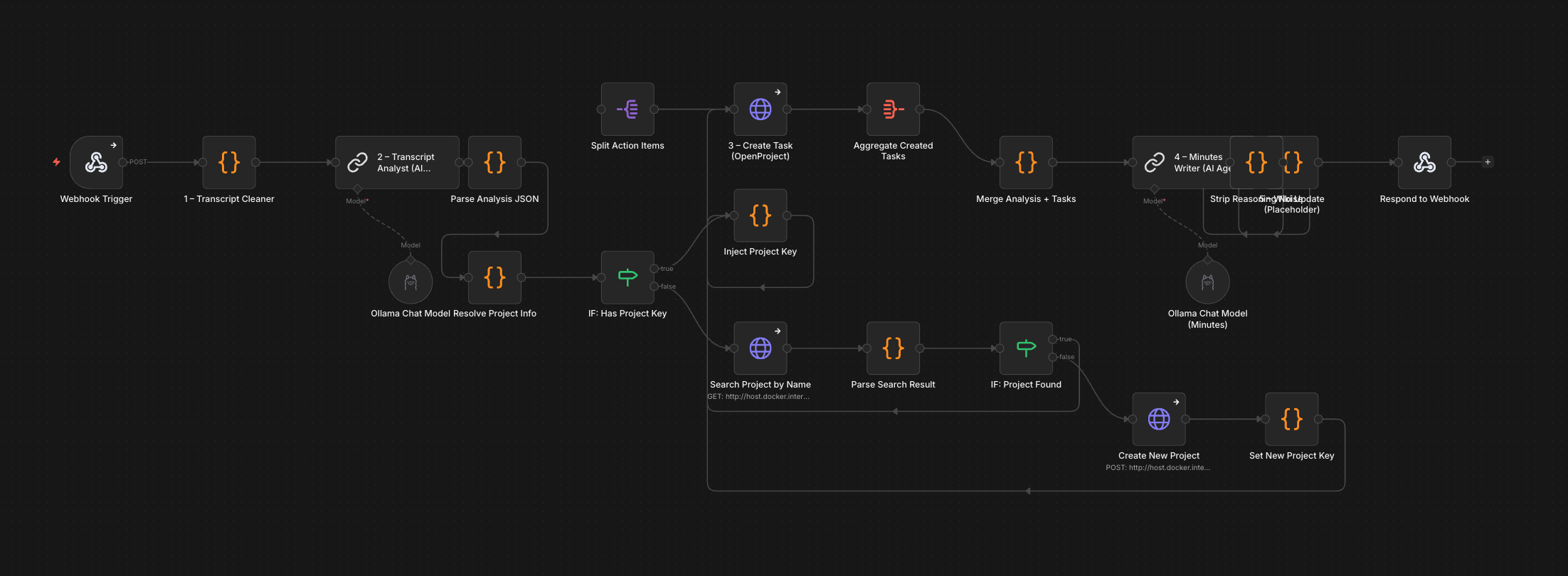
Der Projekt-Auflösungszweig (7 Nodes) ist wahrscheinlich der n8n-idiomatischste Teil des gesamten Workflows: Etwas, das wxO zur Laufzeit über LLM-Reasoning erledigt, wird hier als expliziter Entscheidungsgraph ausgedrückt. Ausführlicher – aber auch vorhersehbarer und debuggbarer.
Bei lokalen Modellen ist „Gib nur JSON zurück" eher eine höfliche Bitte als eine Garantie. gemma4:31b produziert gelegentlich extended Reasoning vor dem JSON, llama3.2 liefert manchmal zwei JSON-Objekte hintereinander aus. Der Parser-Node musste deshalb wirklich robust sein:
1// Extract first complete top-level JSON object via brace-counting
2function extractFirstJson(s) {
3 const start = s.indexOf('{');
4 if (start === -1) return null;
5 let depth = 0, inStr = false, escape = false;
6 for (let i = start; i < s.length; i++) {
7 const c = s[i];
8 if (escape) { escape = false; continue; }
9 if (c === '\\' && inStr) { escape = true; continue; }
10 if (c === '"') { inStr = !inStr; continue; }
11 if (inStr) continue;
12 if (c === '{') depth++;
13 else if (c === '}') { depth--; if (depth === 0) return s.slice(start, i + 1); }
14 }
15 return null;
16}
17
18const stripped = aiResponse
19 .replace(/```(?:json)?|```/g, '')
20 .replace(/["'`]+$/, '')
21 .trim();
22const jsonCandidate = extractFirstJson(stripped);
Ähnlich beim Protokoll-Output: gemma4:31b stellt den Protokollen oft Chain-of-Thought-Überlegungen voran. Deshalb gibt es einen dedizierten „Strip Reasoning Noise"-Node, der alles vor dem letzten Vorkommen von # Meeting Minutes abschneidet.
1const marker = raw.lastIndexOf('# Meeting Minutes');
2const minutes = marker >= 0 ? raw.slice(marker).trim() : raw.trim();
Beides ist die Art von defensivem Code, den man eigentlich nicht schreiben will – aber schreibt, wenn lokale Modelle im Spiel sind. Mit einem Cloud-LLM im JSON-Modus würde das meiste davon wegfallen.
Auch hier lief nicht alles reibungslos:
gemma4:31b ignorierte JSON-only-Anweisungen bei kurzen Inputs und fiel auf Reasoning-Text zurück. llama3.2 lieferte leere Templates oder doppelte JSON-Objekte. Die Lösung: zwei verschiedene Modelle – Llama für JSON-Extraktion (temperature 0.1), Gemma für freie Protokoll-Sprache.project_key trotz Setzen von includeRemainingFields: true. Die UI warnt darüber nicht. Der Fix war ein eigener „Inject Project Key"-Code-Node, der das Action-Items-Array manuell aufteilt und das Feld wieder anhängt.gemma4:31b brauchte bei längeren Transkripten 5+ Minuten. curls Standard-60-Sekunden-Timeout griff, bevor der Workflow fertig war. Workaround: --max-time 300 oder Ergebnisse nachträglich über die Executions-API auslesen.So haben sich die beiden Varianten über die fünf Workflow-Phasen geschlagen:
Auf der wxO-Seite hatte ich ursprünglich einen dedizierten LLM-Agenten (transcript_cleaner) dafür. In der Praxis habe ich stattdessen das externe process-vtt.sh-Python-Skript genutzt, weil große VTT-Dateien das Kontextfenster des Agenten überforderten und Loops produzierten – unabhängig davon, ob ich Orchestrates empfohlene Modelle oder größere lokale Modelle nutzte. Der „agentische" Bereinigungsschritt wurde so zu einem Pre-Processing-Skript außerhalb der Plattform.
In n8n ist die Transkript-Bereinigung ein JavaScript-Code-Node innerhalb des Workflows – reines Regex, kein LLM, kein externer Schritt. Rohe VTT- oder Plaintext-Eingabe rein, Timestamps, Tags und Duplikate deterministisch raus. Transkript-Bereinigung ist eine deterministische Aufgabe. Ein LLM dafür einzusetzen, brachte Kosten und Instabilität ohne Mehrwert.
Hier spielt die Modellwahl eine größere Rolle als die Plattform.
wxO lief transcript_analyst auf einem Cloud-Modell (GPT-OSS über Groq). Der JSON-Output war stabil und strukturiert – Parser-Workarounds waren nicht nötig.
n8n lief llama3.2:latest lokal über Ollama. Das Modell funktionierte meistens, erforderte aber einen JSON-Parser, Markdown-Stripping und Fallback-Logik für doppelte Outputs. Das war das zeitaufwendigste Debugging im gesamten Experiment – aber es ist ein Cloud-vs-lokal-LLM-Unterschied, kein Plattform-Unterschied. Hätte ich n8n auf dasselbe Cloud-Modell mit JSON-Modus gezeigt, wären die Parser-Hacks wahrscheinlich überflüssig.
Die wxO-Variante hat dafür ein Python-Tool: Es schlägt Benutzer nach Login oder Anzeigename nach, setzt eine echte _links.assignee-Referenz (kein Text im Beschreibungsfeld), bildet Strings wie "high" auf die korrekte OpenProject-Prioritäts-ID ab und behandelt die URL-Unterschiede zwischen Docker-Container-Netzwerk und Host. Da ich es speziell für dieses Setup erstellt habe, kümmert es sich um die Details, die ein generischer HTTP-Node nicht abdeckt.
Die n8n-Variante nutzt einen HTTP-Request-Node, der an die OpenProject-API POSTet. Er erstellt Work Packages und setzt Titel, Beschreibungen und Fälligkeitsdaten korrekt. Aber er schreibt Zuständigen-Namen in das Beschreibungsfeld statt sie als OpenProject-User zu verknüpfen, und Prioritäten waren auf „normal" hart kodiert. Die reichhaltigere Tool-Integration ist ein direktes Ergebnis davon, volles Python zur Verfügung zu haben – mit Hilfsfunktionen, Error Handling und API-Lookup-Logik. In n8n würde man dafür mehr HTTP-Request-Nodes und Code-Nodes hinzufügen – machbar, aber geschwätziger.
Beide Seiten produzieren brauchbare Markdown-Meeting-Protokolle. Der Unterschied liegt im Bereinigungsaufwand.
wxOs minutes_writer-Agent auf einem Cloud-LLM liefert sauberes Markdown direkt – kein Post-Processing nötig.
n8ns Minutes-Writer auf gemma4:31b (lokal) produziert guten Text, stellt ihr aber häufig Chain-of-Thought-Überlegungen voran. Der Strip Reasoning Noise-Code-Node schneidet alles vor dem letzten # Meeting Minutes-Marker ab. Es funktioniert – ist aber das Pflaster, das man eigentlich nicht kleben möchte. Beide liefern Protokolle, die ich einem Stakeholder schicken würde. n8n braucht einen zusätzlichen Bereinigungsschritt, aber die Ausgabequalität ist vergleichbar.
wxO-Deployment bedeutet: venv aktivieren, Env-Variablen setzen, Orchestrate-Server starten (dauert), Agenten einzeln oder über import-agents.sh importieren, dann durch Einfügen von Transkripten in die Chat-UI testen. Es funktioniert – ist aber eine mehrstufige Zeremonie, die sich kaum vollständig skripten lässt.
n8n-Deployment in diesem Experiment: JSON entwerfen, über MCP-Tool aus VS Code deployen, mit ./test-workflow.sh transcript.txt 1 testen, Fehler über die Executions-API inspizieren, Nodes über Partial Update patchen – alles ohne den Editor zu verlassen. Der gesamte Lifecycle ist skriptbar, versionierbar und CI/CD-freundlich. Die MCP-Integration macht n8n zu einem programmierbaren Backend, das man aus der IDE steuert. Für Teams, die in Git, Pull Requests und Infrastructure-as-Code denken, passt das natürlich.
Das ist kein Gewinner/Verlierer-Vergleich, sondern ein Trade-off, den man kennen sollte:
Der wxO-Ansatz skaliert gut beim Hinzufügen neuer Fähigkeiten (einfach einen weiteren Agenten hinzufügen und im Orchestrator erwähnen). Der n8n-Ansatz skaliert gut, wenn Zuverlässigkeit und Auditierbarkeit im Vordergrund stehen (jeder Ausführungspfad ist im Graphen nachvollziehbar).
Drei Dinge haben mich am meisten überrascht:
Wie produktiv der MCP-getriebene n8n-Workflow sich anfühlte. Der gesamte 22-Node-Workflow entstand wirklich aus VS Code heraus: initiales Deployment, Debugging, Patchen einzelner Nodes, Re-Testing – alles über MCP-Tools und Shell-Skripte. Zu fast keinem Zeitpunkt habe ich die n8n-Web-UI geöffnet. Für ein Entwicklungsteam, das bereits in VS Code lebt, ist das eine bemerkenswert natürliche Art, Workflow-Automatisierungen aufzusetzen.
Wie gut der wxO-Orchestrator tatsächlich routet.
Der meeting_manager hat immer die richtigen Agenten in der richtigen Reihenfolge gewählt. Die Orchestrierungsanweisungen lesen sich wie eine Prozessbeschreibung, die man in ein Wiki stellen würde – und trotzdem werden im Hintergrund echte Tools, echte APIs, echte externe Systeme angesteuert. Wenn es funktioniert, fühlt es sich elegant an.
Wo die echten Debugging-Stunden hingeflossen sind. Nicht in wxO. Nicht in n8n. In die lokalen LLMs. JSON-Format-Stabilität, Reasoning-Rauschen, das in strukturierte Outputs durchsickert, Timeout-Management wenn die Inferenz länger dauert als erwartet. Die Plattformen selbst waren selten der Flaschenhals – die Modelle waren es. Das war einer der größten Zeitfresser und der unerfriedigendste Teil des Experiments.
Nach diesem Experiment würde ich die Entscheidung so rahmen:
Entfaltet sein volles Potenzial, wenn ...
In dieser Welt wird n8n mit MCP zu einem leistungsfähigen souveränen KI-Hub – besonders in Kombination mit lokalem LLM-Serving, LangChain-Nodes und einem GitOps-Mindset.
Entfaltet sein volles Potenzial, wenn ...
Hier funktioniert wxO als Agent Control Plane, die über vielen Backend-Systemen sitzt – die selbst etwa durch Tools wie n8n betrieben werden könnten.
Die beiden schließen sich gegenseitig nicht aus. Man könnte wxO als konversationelles Frontend und Orchestrierungsschicht nutzen und dabei n8n-Workflows als Backend-Tools über MCP oder Webhooks aufrufen. Eine Architektur, die es wert ist, erkundet zu werden.
In dieses Experiment bin ich nicht gegangen, um einen Sieger zu küren. Die eigentliche Frage war: Wie fühlt sich jede Plattform an, wenn man sie gegen einen echten Use Case laufen lässt? Und ja, mir ist klar, dass ich nicht einfach von einem Anwendungsfall, einem Satz von Modellen oder einem Workflow-Entwurf verallgemeinern kann. Aber ich bin der Meinung, dass diese Art des praktischen, parallelen Aufbaus der beste Weg ist, um die Kompromisse in der Praxis zu verstehen.
Nach dem echten Betrieb auf beiden Seiten – hier mein Ergebnis:
watsonx Orchestrate überzeugt, wenn Agenten eine Enterprise-Fähigkeit darstellen – etwas, das sich in bestehende Prozesse einfügen, Governance-Grenzen respektieren und tief in Tools wie Assignee-Auflösung, Wiki-Seiten oder unternehmensweite Wissenssysteme integrieren muss. Das natürlichsprachliche Orchestrierungsmodell ist wirklich mächtig, und mit einem starken Cloud-LLM „funktioniert" das Routing meistens einfach.
n8n + MCP überzeugt, wenn Agenten und LLMs ein Developer-Tool sind – etwas, das man aus der IDE heraus baut, in Git versioniert, über Skripte deployt und durch Lesen von Execution-Logs debuggt. Das deterministische Graph-Modell tauscht Eleganz gegen Vorhersehbarkeit, und die MCP-Integration lässt n8n weniger wie eine separate Plattform und mehr wie eine programmierbare Schicht im bestehenden Stack wirken.
Wer einen solchen Vergleich in der eigenen Umgebung durchführen möchte – ob mit n8n, watsonx Orchestrate, lokalen LLMs, OpenProject oder einem ganz anderen Stack – meldet sich gerne. Das ist die Art von Hands-On, die wir bei Infralovers leben.
Lerne, wie man KI in Codeprojekte integriert, um effizienter zu arbeiten und innovative Lösungen zu schaffen.
Nutzen Sie KI-gestützte Skills, Workflow-Automatisierung und Enterprise-Grade Governance, um die Effizienz Ihres Teams zu steigern.
Verbinden Sie Ihren Enterprise-Stack, integrieren Sie KI-Fähigkeiten und setzen Sie selbst gehostete Automatisierung ein.
Wenn Sie bereits Nomad- und Vault-Patterns in Produktion betreiben, ist die erste Frage zu OpenBao einfach: laufen unsere bestehenden Workloads ohne Rewrite
Als wir unseren Beitrag HashiCorp Nomad and Vault: Dynamic Secrets veroeffentlichten, lief die Demo ausschliesslich als Python Flask-Anwendung. Seitdem ist das
Im vorigen Artikel, Tool-Surface-Kompression, ging es um die Frage, wie man externe Funktionalität, ganze APIs und Systeme, möglichst token-effizient in den
2.500 API-Endpoints. Jeden einzelnen als MCP-Tool exponiert, das wären laut Cloudflare 1,17 Millionen Tokens allein für die Tool-Definitionen, bevor der Agent
Jedes Nomad-Tutorial, das Sie online finden, verwendet den docker-Treiber. Das ist verstaendlich — Container sind portabel, Images buendeln alles, und Docker
Sie interessieren sich für unsere Trainings oder haben einfach eine Frage, die beantwortet werden muss? Sie können uns jederzeit kontaktieren! Wir werden unser Bestes tun, um alle Ihre Fragen zu beantworten.
Hier kontaktieren