

Lokale Hybrid-Suche: Retrieval ohne RAG-Pipeline
Vor zwei Wochen habe ich darüber geschrieben, was sich ändert, wenn das Modell gleich bleibt und nur der Harness wechselt. Kurzfassung: der Wrapper macht mehr

Update Juni 2026. Diesen Text habe ich im März geschrieben. Drei Monate und einige Studien später ist die These dieselbe geblieben, aber schärfer geworden. Ich habe sie überarbeitet, statt einen zweiten Artikel zu schreiben: „weniger Kontext" war die richtige Richtung, aber die falsche Vokabel. Die genauere lautet kompiliert statt zusammengeschüttet. Wo das den Unterschied macht, steht es jetzt drin.
Vor einigen Wochen habe ich angefangen, unsere CLAUDE.md-Dateien auszumisten. Warum? Weil ein Agent immer wieder denselben Fehler machte, gegen eine Regel, die explizit in der Konfiguration stand. Wenn eine klare Anweisung den Fehler nicht verhindert, stimmt mit der Vorgehensweise etwas nicht. Also habe ich sie gelesen, dreihundert Zeilen. Und dabei wurde mir klar: vieles davon beschreibt Wünsche, keine Entscheidungen. Wunsch-Regeln, die kein Mensch durchsetzen würde, wenn er das Code-Review selbst gemacht hätte.
Das Muster beschreiben viele, die mit Coding-Agents arbeiten: Das Modell macht einen Fehler, jemand schreibt eine Regel dagegen, beim nächsten Mal passiert der Fehler trotzdem. Länger geworden ist nur die Datei. Mich hat weniger die Beobachtung selbst gepackt als die Frage darunter, der ich systematisch nachgehen wollte: Warum greift eine Regel nicht, die klar dasteht? Eine neue Regel nachzulegen ist der schnelle Reflex, er fühlt sich nach Kontrolle an. Verstehen ist die mühsamere, aber wirksamere Variante. Und es stellt sich heraus, dass die Forschung darauf eine ziemlich klare Antwort gibt.
Zwei Studien aus diesem Jahr beschreiben das Problem aus unterschiedlichen Winkeln, und zusammen ergibt sich ein klareres Bild als jede einzelne für sich.
Gloaguen et al. von der ETH Zürich haben untersucht, wie AGENTS.md-Dateien die Agentenleistung beeinflussen1. Ihr Befund ist unbequem und lässt sich auf einen Satz eindampfen: Kontext-Dateien senken die Erfolgsrate tendenziell, verglichen damit, dem Agenten gar keinen Repository-Kontext zu geben. Konkret reduzieren LLM-generierte Kontext-Dateien die Erfolgsrate um rund 3% und erhöhen die Kosten durch 14 bis 22% mehr Reasoning-Tokens um über 20%. Nicht dramatisch, aber konsistent, und es zeigt in die falsche Richtung.
Der wichtigere Teil steckt im Detail: Es macht einen Unterschied, wer die Datei schreibt. Sorgfältig von Hand kuratierte, kleine Kontext-Dateien schneiden in der ETH-Auswertung knapp positiv ab. LLM-generierte Dateien schaden mehr, als sie helfen. Das ist kein Argument gegen AGENTS.md. Es ist ein Argument gegen die reflexartige Variante davon: erst mal eine Datei generieren lassen und hoffen.
Gleichzeitig: Lulla et al. haben den Effekt von AGENTS.md-Dateien in realen Pull Requests gemessen2. Dort sieht es anders aus: AGENTS.md reduzierte die Laufzeit um 28,6% und den Output-Token-Verbrauch um 16,6%. Dieselbe Technologie, gegenteiliger Effekt.
Wie passt das zusammen?
Die Auflösung liegt im Zweck: Kontext-Dateien helfen bei der Repo-Exploration, dem Auffinden im Repository. Finde den Build-Befehl, kenne die Test-Konvention, weiß, welches Verzeichnis relevant ist. Sie scheitern bei Instruktion, also bei komplexen Logikaufgaben, die Tiefe und Reasoning verlangen. Das ist kein Implementierungsfehler, das ist strukturell. Repo-Exploration spart Such-Aufwand. Instruktion schlägt auf das Reasoning-Budget.
Genau dieser Unterschied trennt die beiden Studien. In realen PRs überwiegt der Explorations-Anteil. In Benchmark-Aufgaben mit Logiktiefe überwiegt der Instruktionsanteil. Context-Dateien sind ein Werkzeug für die Repo-Exploration, kein Ersatz für Reasoning.

Jetzt wird es konkreter. Wie viele Regeln verträgt ein Modell, bevor es anfängt zu degradieren?
Jaroslawicz et al. haben das im IFScale-Benchmark direkt gemessen3, über die Modell-Generationen von Mitte 2025 hinweg und mit systematisch steigender Regelanzahl. Das Ergebnis zeigt drei Degradierungsmuster, je nach Modell-Klasse:
Threshold Decay (Top-Reasoning-Modelle der Zeit, etwa o3 oder Gemini 2.5 Pro): Bis etwa 150 bis 200 Instruktionen nahezu perfekte Befolgungs-Rate, dann rapider Abfall. Eine Art Kapazitätsdecke: darunter robuste Leistung, darüber Kollaps.
Linear Decay (die breite Mittelklasse, etwa GPT-4.1): Gleichmäßiger Leistungsabfall mit jeder zusätzlichen Instruktion. Keine Decke, kein plötzlicher Kollaps, aber auch keine Stabilisierung. Jede neue Zeile kostet etwas.
Exponential Decay (kleine Modelle, etwa Haiku 3.5): Schneller Verfall schon bei niedriger Regeldichte. Was bei großen Modellen noch funktioniert, überlastet diese Klasse deutlich früher.
Die konkreten Modelle altern schnell, das Muster nicht. Jede Generation schiebt die Schwelle höher, der Effekt verschwindet aber nicht: Er hängt an der endlichen, effektiven Aufmerksamkeit eines Modells, und die lässt nach, lange bevor das Kontext-Fenster voll ist.
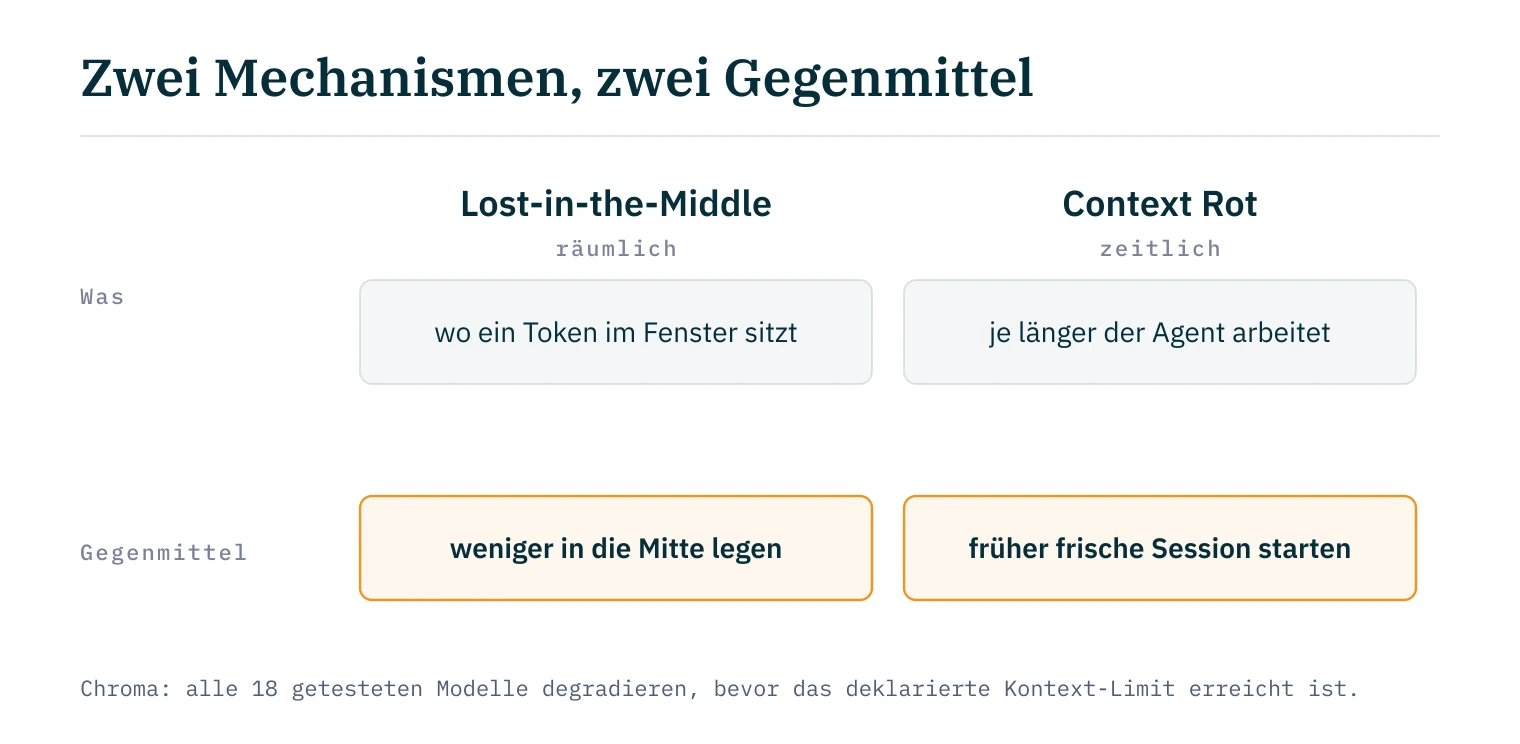
Dazu kommt ein Phänomen, das in der Benchmark-Literatur als Primacy Bias beschrieben wird: Instruktionen am Anfang des System-Prompts werden zuverlässiger befolgt als solche in der Mitte oder am Ende. Liu et al. haben dafür das „Lost-in-the-Middle"-Muster dokumentiert, eine U-förmige Aufmerksamkeitskurve: Was am Anfang und am Ende steht, bleibt präsent (rund 75% und 72% Recall), was in der Mitte landet, fällt auf etwa 55%4.
Hier ist der Punkt, den ich im März noch nicht sauber getrennt hatte. Lost-in-the-Middle ist ein räumliches Problem: wo ein Token im Fenster sitzt. Es gibt daneben ein zeitliches: Context Rot. Je länger ein Agent arbeitet, desto mehr füllt sich sein Fenster mit rohem Tool-Output, und das Signal-zu-Rausch-Verhältnis sinkt. Chroma hat das über 18 aktuelle Modelle gemessen, und alle 18 lassen schon weit unter ihrer maximalen Fensterlänge nach5. Zwei Mechanismen, zwei verschiedene Gegenmittel: gegen das räumliche Problem hilft, weniger in die Mitte zu legen. Gegen das zeitliche hilft, früher eine frische Session zu starten.
Was beides für die Praxis bedeutet: Jede redundante Regel verdrängt Budget, das ein Modell für projektspezifische, tatsächlich kritische Instruktionen braucht. Eine Datei mit dreihundert Zeilen generischer Best Practices ist kein Sicherheitsnetz. Sie ist Lärm, der Signal übertönt.
Bevor ich weitermache: Der naheliegendste Einwand gegen dieses Argument geht so. Bessere Tooling löst das Problem, nicht weniger Kontext. Linters, Formatter, CI-Gates, Typ-Checker. Die meisten „Regeln" in AGENTS.md-Dateien sind Dinge, die man automatisieren könnte. Wenn der Build-Befehl make test ist, braucht kein Sprachmodell das in einer Textdatei. Das steht im Makefile.
Das ist ein legitimes Argument, und zu einem großen Teil stimmt es. Wenn eine Regel tool-erzwingbar ist, gehört sie ins Tooling, nicht in den Kontext. Das ist nicht nur effektiver, es ist robuster, weil es nicht von der Aufmerksamkeitskapazität eines Sprachmodells abhängt.
Aber Tooling löst das Problem nicht vollständig. Architekturentscheidungen, Domain-spezifische Konventionen, Begründungen für Abweichungen vom Default: das sind Dinge, die kein Linter trägt. Genau dafür bleibt Context Engineering relevant. Der Punkt ist nicht „kein Kontext", der Punkt ist der richtige Kontext, präzise formuliert.
Es gibt einen Benchmark-Befund, der mich überrascht hat. Vercel-Ingenieur Gao hat in einer eigenen Engineering-Eval untersucht, wie AGENTS.md-Dateien im Vergleich zu dynamisch geladenen Skills abschneiden6. Ein komprimierter 8-KB-Index in der AGENTS.md erreichte dort eine Erfolgsrate von 100% für Next.js-16-APIs. Dynamisch geladene Skills schafften 79%. Das legt nahe: Ein präziser, dedizierter Index schlägt generische Fähigkeiten, wenn der Index tatsächlich das Richtige enthält und nichts anderes.
Im März hatte ich daraus drei Prinzipien abgeleitet. Inzwischen ist ein viertes dazugekommen, und es ist das wichtigste.
Zeiger statt Kopien. Context-Dateien sollten auf Code verweisen, file:line, statt Code einzubetten. „Schau dir diese Funktion an, das ist unser Muster" ist präziser als eine dreißigzeilige Erklärung, was die Funktion tun soll. Der Agent kann die Funktion lesen. Was er nicht kann: aus einer vagen Beschreibung die genaue Implementierungserwartung ableiten. Dasselbe Prinzip skaliert über Skills: Bei der Progressive-Disclosure-Mechanik steht nur die kurze Skill-Beschreibung permanent im System-Prompt, der volle Inhalt wird erst bei Bedarf nachgeladen. Bei dutzenden Skills hält das den permanenten Kontext schlank, statt für jeden Skill den vollen Inhalt vorzuhalten7.
Convention over Configuration. Was das Modell bereits weiß, muss nicht erklärt werden. Ralf D. Müller hat das Konzept der „Semantic Anchors for LLMs" geprägt, aufbauend auf Peter Naurs „Programming as Theory Building" (1985): Fachbegriffe fungieren als Brücke zwischen mentalen Modellen und Codegenerierung8. Chang et al. haben das empirisch untermauert: Präzise Fachbegriffe aktivieren spezifische Gewichtsmuster im trainierten Modell9. Wer „Terraform Module" schreibt, aktiviert ein Cluster samt Konventionen, Dateipfaden, HCL-Syntax. Wer stattdessen dieselben Konventionen in der AGENTS.md ausformuliert, verschwendet Instruktions-Budget für etwas, das ein einzelner Term bereits auslöst.
Progressive Disclosure. Nicht alles sofort laden. Was braucht der Agent für diesen Task, jetzt? Deployment-Konfiguration ist irrelevant beim Schreiben eines Unit-Tests. Kontext als Ressource behandeln, nicht als Sicherheitsnetz. Patrick Debois hat das als CDLC formuliert, einen Context Development Life Cycle aus Generate, Evaluate, Distribute, Observe10. Kontext als evolvierendes Artefakt, nicht als statische Konfigurationsdatei. Tessl.io geht einen Schritt weiter und behandelt Agent-Skills wie Software-Pakete: versioniert, evaluiert, gezielt geladen. Ein Terraform-Stacks-Skill stieg laut Tessl damit von 47% auf 96% Erfolgsrate11. Nicht mehr Kontext, präziserer, evaluierter Kontext.
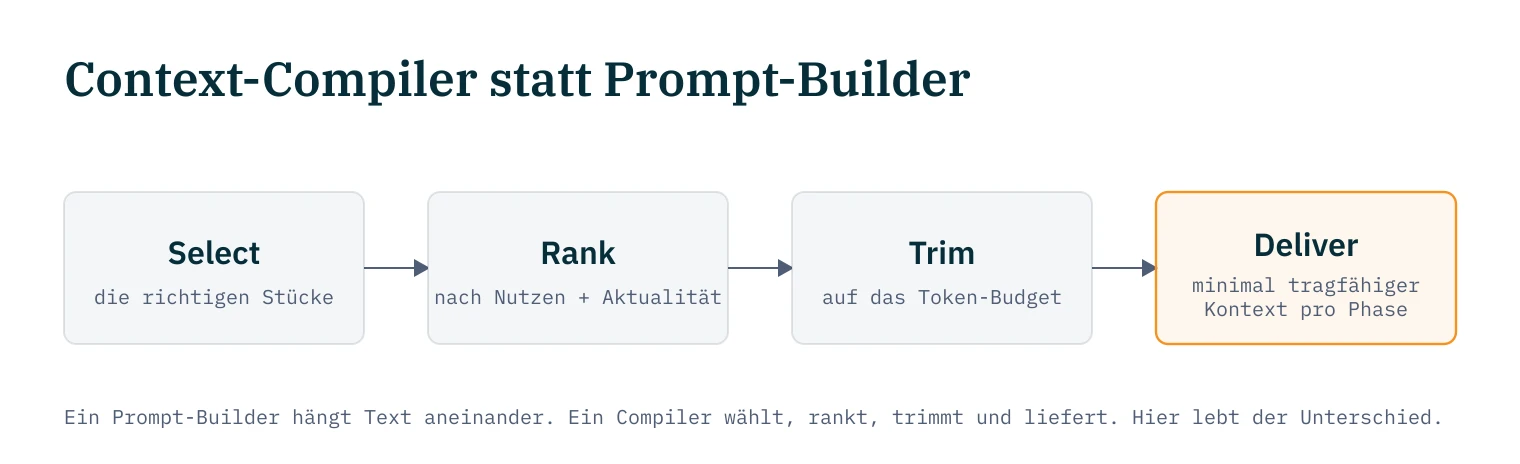
Phase-Aware Compilation. Das ist das neue, vierte Prinzip, und es bündelt die anderen drei. Boden Fuller unterscheidet einen Prompt-Builder von einem Context-Compiler: Ein Prompt-Builder hängt Text aneinander. Ein Context-Compiler wählt die richtigen Stücke aus, rankt sie nach Nutzen und Aktualität, trimmt auf das Token-Budget und liefert den minimal tragfähigen Kontext für die aktuelle Phase12. Der Agent, der recherchiert, braucht anderen Kontext als der, der implementiert. Fullers schärfster Satz: Genau hier lebt 99% des Unterschieds zwischen Teams, die AI-Coding-Agents benutzen, und Teams, die verlässliche Ergebnisse von ihnen bekommen. Damit kippt auch meine eigene März-Vokabel. Der Hebel ist nicht weniger gegen mehr. Er ist kompiliert gegen zusammengeschüttet. Ein ziellos versammelter Kontext schadet, ob groß oder klein.
Warum funktioniert präziser Kontext überhaupt? Es gibt eine informationstheoretische Lesart, und sie ist verlockend genug, dass ich sie nicht überdehnen will.
Auf der Token-Ebene ist die Sache belastbar. Sorensen et al. wählen aus einem Satz von Prompt-Templates jenes aus, das die Mutual Information (den statistischen Zusammenhang zwischen Eingabe und Ausgabe) maximiert, ganz ohne gelabelte Beispiele, ohne Zugriff auf die Gewichte. Hohe Mutual Information korreliert mit hoher Genauigkeit, und das Verfahren erreicht „90% des Wegs von der durchschnittlichen zur besten Prompt-Genauigkeit"13. Dazu kommt das Theorem von Delétang et al.: Sprachmodellierung ist Kompression, Prädiktion und Kompression sind dasselbe14. Beides stützt die Intuition, dass die Wahl des richtigen Kontexts eine Form von Entropie-Reduktion ist.
Das Kompressions-Theorem sagt, wie lang die Kodierung gegeben einen Kontext ist. Es sagt nicht, welcher Kontext optimal oder minimal ist. Der Sprung von „Modellierung ist Kompression" zu „Kontextwahl ist Kompression" ist eine Interpretation, kein Beweis. Und es gibt eine handfeste Gegenkraft: niedrige Entropie ist nicht dasselbe wie Korrektheit. Eine scharfe, selbstsichere Verteilung kann auf das Falsche kollabieren, etwa durch eine Fehlkalibrierung aus dem Training auf menschliches Feedback oder durch Sycophancy (die Neigung des Modells, dem Nutzer nach dem Mund zu reden). Auf der Ebene der Agenten-Aktionen, also bei der Frage „senkt besserer Kontext zur Laufzeit die Fehlerrate", fehlt der saubere kontrollierte Test bislang. Mein aktueller Stand: token- und template-seitig ist die These belegt, agenten-seitig ist sie offen. Ich nutze sie als Kompass, nicht als Naturgesetz.
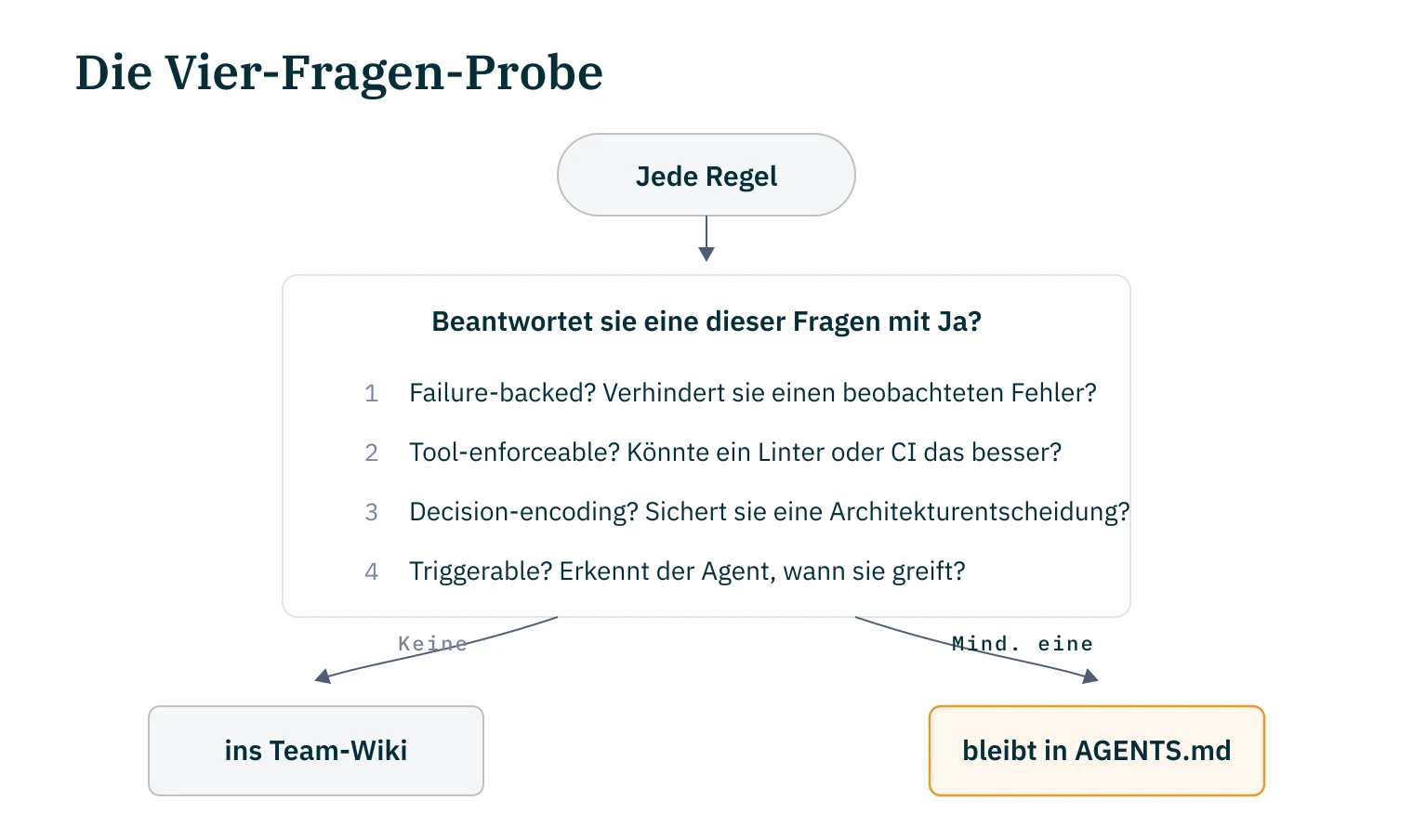
Wortmann hat eine einfache Heuristik vorgeschlagen, um Regeln zu evaluieren15. Vier Fragen pro Regel:
Regeln, die keine dieser Fragen mit Ja beantworten, sind Aspirationen. Sie gehören ins Team-Wiki, nicht in die AGENTS.md.
Ob diese Heuristik auf alle Projekte skaliert, ist offen, und das Information-Bottleneck-Modell (ein informationstheoretisches Optimierungs-Modell) liefert zwar die formale Sprache für „minimal hinreichender Kontext", aber bisher kein praktisches Kriterium. Was ich sehe: Die Fragen sind eine nützliche Reibungsfläche. Wer sie im Team durchläuft, findet mindestens dreißig Prozent der Regeln, die nichts Konkretes verhindern.
Es gibt einen Begriff, der mir seit dem Frühjahr nicht mehr aus dem Kopf geht, und er stammt von Jarosław Wąsowski: Context Debt. Technische Schuld entsteht, wenn ein Entwickler abkürzt. Context Debt entsteht, während der Entwickler schläft, weil der Agent weiterarbeitet5.
Wąsowskis Beispiel sitzt. Freitag, 17:23 Uhr. Ein Agent arbeitet 35 Minuten an einem Refactoring. Ein grep liefert acht Treffer, der Agent editiert den vierten, der Diff sieht gut aus, das Review dauert sieben Minuten, das Deployment ist sauber. Um 02:14 Uhr der Produktionsalarm: Rechnungen werden für Neukunden nicht erzeugt. Die richtige Datei war nicht die vierte, sondern die zweite. Treffer vier lag in der toten Zone in der Mitte einer langen Liste, und nach 35 Minuten war das Fenster zu 60% mit rohem Tool-Output gefüllt. Kein Modell-Bug. Context Debt, die sich als kaputter Code materialisiert hat.
Das ist der Unterschied, der mir die Dringlichkeit der ganzen Sache erst klargemacht hat: Bei Code ist Schuld sichtbar, im Build, im Test, im Review. Bei Kontext ist sie still. Kein Compiler, kein Linter, kein Reviewer schlägt an. Der Code besteht das Review, gerade weil er plausibel aussieht. Deshalb reicht es nicht, die AGENTS.md einmal aufzuräumen. Sie altert ohne Warnsignal weiter.
Context Engineering wird die neue DevOps-Disziplin, mit demselben Reifegrad-Bedarf, den Infrastructure as Code damals brauchte. Konfigurationsdateien wurden irgendwann versioniert, getestet, reviewed. AGENTS.md-Dateien heute: meistens ein einzelner Commit, der wächst, wenn etwas schiefgeht.
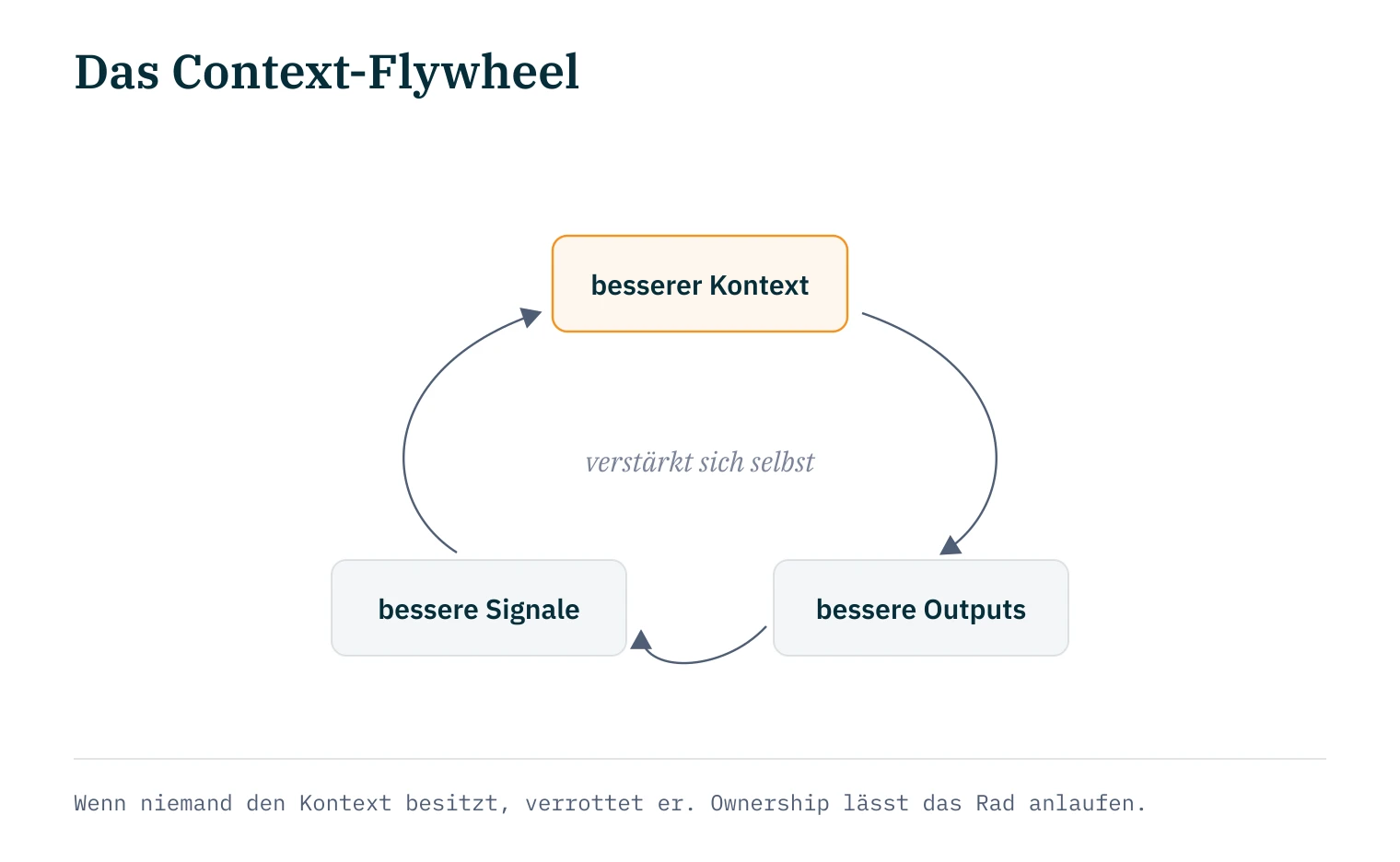
Das wird sich ändern weil die Teams, die Context-Dateien wie Code behandeln, messbar bessere Ergebnisse erzielen. Patrick Debois beschreibt die Dynamik als Flywheel: besserer Kontext erzeugt bessere Agenten-Outputs, bessere Outputs erzeugen bessere Signale, bessere Signale erzeugen besseren Kontext10. Die Schleife verstärkt sich selbst. Sein unglamouröser Zusatz: Wenn niemand den Kontext besitzt, verrottet er. Ownership ist die Bedingung dafür, dass das Schwungrad überhaupt anläuft.
Und genau da sitzt der eigentliche Wettbewerbsvorteil. Modelle werden zur Commodity, alle haben dieselben Foundation-Modelle. Tools konvergieren, das Skill-Format ist binnen Wochen überall adoptiert. Was bleibt, ist der über Jahre akkumulierte, gepflegte Kontext. Zwei Firmen mit identischem Toolstack: Die eine pflegt seit zwei Jahren disziplinierte Kontext-Dateien mit Eval-Pipelines, die andere fängt heute an. Den Vorsprung kauft man nicht nach.
Konkret, drei Schritte, mit denen man sofort anfangen kann:
Context-Audit. Jede Regel in der AGENTS.md durch die Vier-Fragen-Probe führen. Nicht als Kritik, als Hygiene. Das Ziel ist nicht Kürze um der Kürze willen, sondern Präzision.
Tooling-Transfer. Alles, was tool-erzwingbar ist, raus aus dem Kontext und ins Tooling. Linting, Formatting, Build-Befehle, Test-Konventionen. Das entlastet das Reasoning-Budget für das, was nur Kontext leisten kann.
Failure-Log. Eine Tabelle anlegen: Wann hat der Agent eine Regel gebrochen? Was war die tatsächliche Konsequenz? Regeln ohne Einträge in dieser Tabelle sind Streichungskandidaten.
Patrick Debois hat eine Frage, die den Reifegrad in einem Satz freilegt: Ihr habt in Agenten, Modelle, Tools und Infrastruktur investiert. Was habt ihr in den Kontext investiert, der das alles erst zum Funktionieren bringt? Wer darauf keine Antwort hat, weiß jetzt, wo er anfängt.
Dieser Post ist Teil einer Serie über AI und Software-Architektur. Die vorherigen Teile behandeln die Fünf Stufen der KI-Entwicklung, Dark Factory Architektur, den Dark Factory Gap, Conway's AI-Inverse und Harness Engineering.
Die Kernthese, Context Engineering als minimale, präzise Injektion, entstand aus direkter Arbeit mit unseren eigenen CLAUDE.md-Dateien. Die Forschungslage zu AGENTS.md war Anfang 2026 neu genug, dass ich die Quellen gesichtet und die Befunde gegeneinander geprüft habe: Gloaguen et al. (ETH Zürich) und Lulla et al. liefern scheinbar widersprüchliche Ergebnisse, die sich nur durch den Unterschied zwischen Repo-Exploration und Instruktion auflösen lassen. Das war keine vorgefertigte These, sondern das Ergebnis des Abgleichs. Die IFScale-Studie (Jaroslawicz et al.) habe ich über die arXiv-Zusammenfassung verifiziert. Der Vercel-Benchmark (Gao) ist ein Engineering-Blog-Post, kein peer-reviewed Paper, und steht hier als zugeschriebene Aussage, nicht als gesichertes Experiment.
Die Juni-Überarbeitung zieht Material nach, das erst seit dem Frühjahr existiert. Den Context-Compiler-Begriff (Boden Fuller) und Context Debt (Jarosław Wąsowski) behandle ich als zugeschriebene Aussagen aus Engineering-Blogs. Die informationstheoretische Stütze ruht auf zwei Primärquellen, Sorensen et al. (Mutual-Information-Prompt-Selektion) und Delétang et al. (Language Modeling Is Compression); die Aussagen sind gegen diese Quellen geprüft. Bewusst zurückhaltend bleibt der Sprung von der Token-Ebene auf die Agenten-Ebene: Dafür gibt es bislang keinen sauberen kontrollierten Test, und das steht so im Text. Claude wurde für Strukturierung und Formulierungsvorschläge eingesetzt. Alle Zahlen, Quellen-Zuordnungen und die Kernargumentationslinie wurden manuell geprüft. Den vollständigen Workflow beschreibe ich in AI-gestützte Wissensarbeit: Wie ich meinen Recherche- und Schreibprozess neu aufbaue.
Gloaguen, R. et al. (ETH Zürich) (2026). Evaluating AGENTS.md: How Context Files Affect LLM Agent Performance. arXiv:2602.11988. arXiv ↩︎
Lulla, A. et al. (2026). On the Impact of AGENTS.md Files on AI-Assisted Software Development. arXiv:2601.20404. arXiv ↩︎
Jaroslawicz, D. et al. (2025). How Many Instructions Can LLMs Follow at Once? The IFScale Benchmark. arXiv:2507.11538. arXiv ↩︎
Liu, N. F. et al. (2023). Lost in the Middle: How Language Models Use Long Contexts. arXiv:2307.03172. arXiv ↩︎
Wąsowski, J. (2026). Managing Agent Context at Every Stage of the SDLC. Medium, zugeschriebene Aussage: Originator des Begriffs „Context Debt"; das Friday-5:23-PM-Beispiel und die Lost-in-the-Middle-vs-Context-Rot-Differenzierung stammen von dort. Context-Rot-Zahlen über 18 Modelle: Chroma (2025), Context Rot Report. ↩︎ ↩︎
Gao, J. (Vercel) (2026). AGENTS.md outperforms skills in our agent evals. Vercel Engineering Blog. vercel.com ↩︎
Progressive Disclosure ist Mechanik des Agent-Skills-Standards (Anthropic, 2025); pi setzt sie um und formuliert sie prägnant: pi.dev: „only descriptions are always in context, full instructions load on-demand." Verwandt: Pocock, M., How To Make Codebases AI Agents Love (progressive disclosure of complexity auf Deep-Module-Interfaces). ↩︎
Müller, R. D. (2025). Semantic Anchors for LLMs. Projektseite und Vorträge. Aufbauend auf Naur, P. (1985). Programming as Theory Building. ↩︎
Chang, E. Y. et al. (2025). Semantic Anchoring in LLMs: Thresholds, Transfer, and Geometric Correlates. arXiv:2506.02139. ICLR 2026 submission. arXiv ↩︎
Debois, P. (2026). The Context Flywheel. jedi.be. jedi.be ↩︎ ↩︎
Zhang, Q. et al. (2026). Agentic Context Engineering (ACE). arXiv:2510.04618. ICLR 2026. arXiv als konzeptioneller Rahmen. Die 47%→96%-Zahl (Faktor 2,04) für den Terraform-Stacks-Skill ist eine Tessl.io-Eval-Angabe, zugeschriebene Aussage, nicht aus dem ACE-Paper. ↩︎
Fuller, B. (2026). The Context Development Life Cycle. Engineering-Blog, zugeschriebene Aussage: „a context compiler selects the right pieces, ranks them by utility and freshness, trims to the token budget". ↩︎
Sorensen, T. et al. (2022). An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels. arXiv:2203.11364. arXiv ↩︎
Delétang, G. et al. (2024). Language Modeling Is Compression. arXiv:2309.10668. arXiv ↩︎
Wortmann, J.-N. (2026). Agent Instructions: The Failure-Backed Rubric. wordman.dev. wordman.dev ↩︎
Lerne, wie man KI in Codeprojekte integriert, um effizienter zu arbeiten und innovative Lösungen zu schaffen.
Transformieren Sie Ihre technischen Arbeitsabläufe mit praktischer AI: Setzen Sie LLMs ein, automatisieren Sie die Infrastruktur und beherrschen Sie die neuesten Tools und Protokolle.
Vor zwei Wochen habe ich darüber geschrieben, was sich ändert, wenn das Modell gleich bleibt und nur der Harness wechselt. Kurzfassung: der Wrapper macht mehr
Diese Woche habe ich denselben Coding-Task durch vier AI-Coding-Tools laufen lassen – opencode, Pi, GitHub Copilot in VS Code und Claude Code –, alle
Wenn Sie bereits Nomad- und Vault-Patterns in Produktion betreiben, ist die erste Frage zu OpenBao einfach: laufen unsere bestehenden Workloads ohne Rewrite
Als wir unseren Beitrag HashiCorp Nomad and Vault: Dynamic Secrets veroeffentlichten, lief die Demo ausschliesslich als Python Flask-Anwendung. Seitdem ist das
Im vorigen Artikel, Tool-Surface-Kompression, ging es um die Frage, wie man externe Funktionalität, ganze APIs und Systeme, möglichst token-effizient in den
Sie interessieren sich für unsere Trainings oder haben einfach eine Frage, die beantwortet werden muss? Sie können uns jederzeit kontaktieren! Wir werden unser Bestes tun, um alle Ihre Fragen zu beantworten.
Hier kontaktieren