

HashiCorp Nomad und Vault mit .NET: ASP.NET Core in einem sicheren Workload
Als wir unseren Beitrag HashiCorp Nomad and Vault: Dynamic Secrets veroeffentlichten, lief die Demo ausschliesslich als Python Flask-Anwendung. Seitdem ist das

Die aktuelle Debatte um Claude Code und Open Code wird meistens als Pricing-Streit erzählt: Anthropic sperrt Drittanbieter-Apps aus dem subventionierten Subscription-Kanal, die Entwickler-Community ist empört, und alle rechnen aus, ob API-Pricing das neue Tool noch erschwinglich macht. Das ist eine reale Auseinandersetzung, keine Frage — aber sie lenkt von der eigentlich wichtigen Geschichte ab.

Die Geschichte ist diese: Der industrielle Bruch in AI-Coding kam nicht von einem Modell-Upgrade. Er kam von einem Wechsel des Form-Factors. Und dieser Wechsel hat den Entwickler-Workflow so fundamental verändert, dass das Modell — Opus 4.5 gegen GPT 5.2 Codex gegen offene Alternativen wie GLM 4.7 oder Minimax M2.1 (Stand Januar 2026) — für die meisten Teams zweitrangig ist.
Ich behaupte das auf Basis von vier Jahren Trajektorie, konkret beobachtbar, plus einer wachsenden Anzahl von Studien, die den Datenpunkt liefern und gleichzeitig zeigen, wo das Bild noch lückenhaft ist.
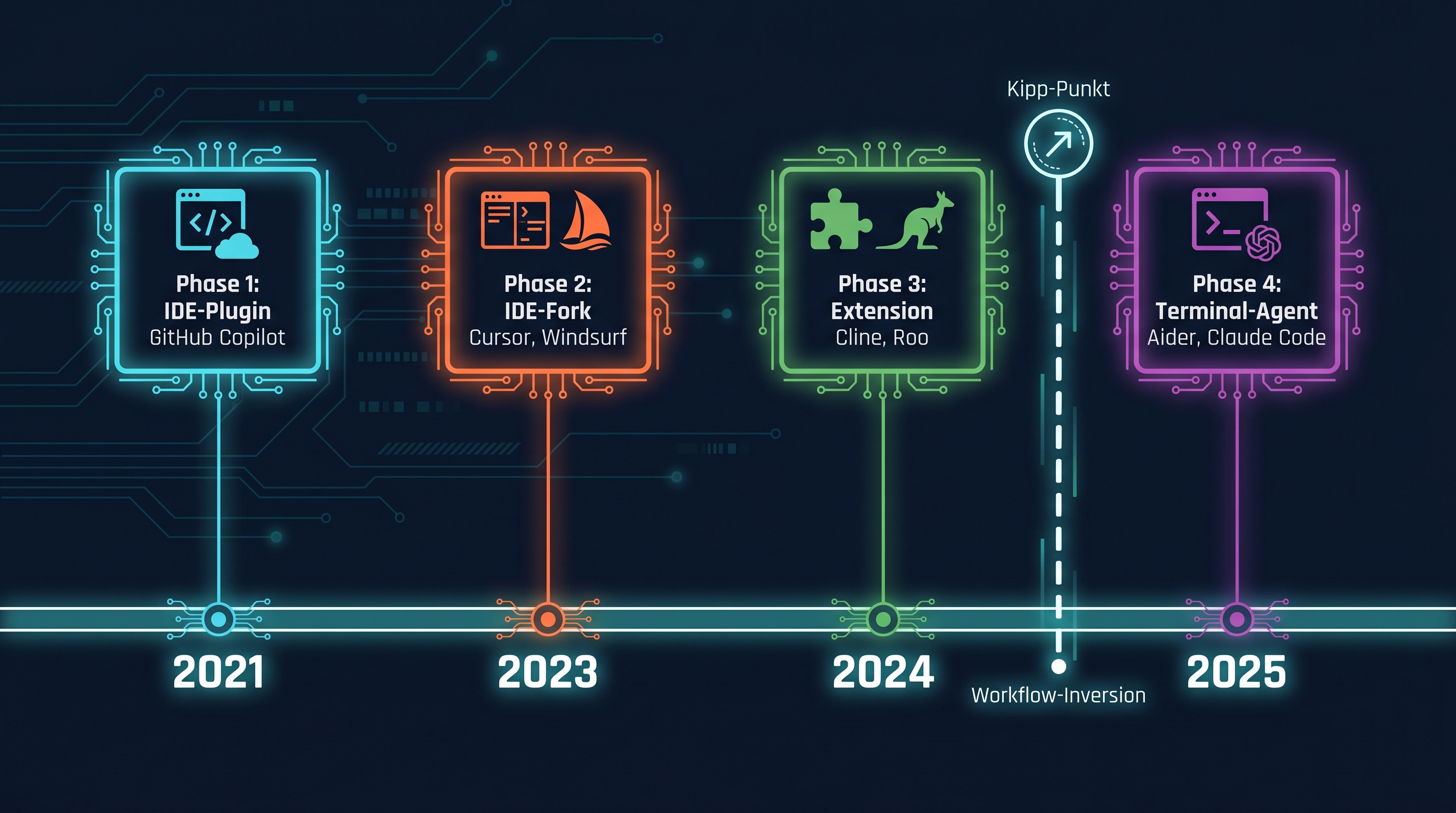
Wer 2021 anfing, GitHub Copilot zu nutzen, hat ein nützliches Werkzeug bekommen.1 Kein Workflow-Wechsel. Nur ein schnellerer Schreiber. Der Entwickler tat weiterhin alles selbst, Copilot half bei der letzten Meile: der Cursor blinkte, die Suggestion erschien, Tab oder Esc. Das war Phase 1: IDE-Plugin, AI hilft in der finalen Eingabestufe, Mensch bleibt Dirigent und Ausführender zugleich.
Phase 2 kam mit Cursor und Windsurf, IDE-Forks, die den Entwickler erstmals eine Schicht höher in den Stack beförderten. Statt Zeilen zu tippen, schreibt man Prompts, und das Modell vervollständigt. Business-Requirement → Prompt → AI completes. Das klingt ähnlich, fühlt sich aber anders an: Der Entwickler delegiert zum ersten Mal, anstatt nur zu beschleunigen. Extensions wie Cline und Roo (Phase 3) brachten dieselbe Delegations-Idee in ein leichteres Setup ohne IDE-Fork: Turn-by-Turn, aber immer noch innerhalb der vertrauten Entwicklungsumgebung.
Phase 4 ist der eigentliche Kipp-Punkt. Aider war eines der ersten prominenten Tools, das AI konsequent aus der IDE herauslöste und als eigenen Terminal-Prozess aufstellte. Die IDE ist nicht mehr das Zentrum. Sie wird zur Beobachtungsfläche. Meine These ist: Claude Code hat sich gegen Aider nicht primär über ein besseres Modell durchgesetzt, sondern über Approachability und tiefe MCP-Integration. Das Tool fühlte sich von Anfang an für Nicht-Power-User zugänglich an, und das MCP-Tooling öffnete eine eigene Plattform-Logik.
Was passiert an diesem Kipp-Punkt genau? Die Arbeit invertiert sich. Bis Phase 3 passt das Tool den Workflow des Entwicklers an: der Mensch ist die stabile Variable, das Tool die veränderte. Ab Phase 4 beginnt der Entwickler, seine eigene Arbeit an das Tool anzupassen. Wer Claude Code ernsthaft nutzt, denkt nicht mehr in Modulen und Tasks, er denkt in Projekten und Handoffs. Er schreibt CLAUDE.md-Dateien, um implizites Wissen explizit zu machen. Er strukturiert seine Repo-Konventionen so, dass der Agent sauber navigieren kann.
Das ist keine Kleinigkeit. Das ist eine Inversion.
Die Produktivitäts-Erzählung rund um AI-Coding ist mit echten Zahlen unterlegt, aber nur für die frühen Form-Factor-Phasen.
Der am häufigsten zitierte Datenpunkt stammt aus dem GitHub-Next-Experiment von Kalliamvakou et al. (2022): Entwickler, die Copilot nutzten, schlossen eine definierte Aufgabe (HTTP-Server in JavaScript) 55 % schneller ab als die Kontrollgruppe, 71 Minuten versus 161 Minuten.1 73 % berichteten, dass sie sich "im Flow" fühlten. Das klingt eindrücklich, bis man die Rahmenbedingungen liest: eine einzelne Aufgabe, einzelne Entwickler, hoher Selbstbericht-Anteil. Ökologische Validität ist begrenzt.
Cui, Demirer et al. (2024) lieferten Felddaten aus drei echten Unternehmens-Kontexten — Microsoft, Accenture, ein Fortune-100-Unternehmen — mit 4.867 Entwicklern.2 Ergebnis: rund 26 % mehr abgeschlossene Tasks pro Woche, gemessen an realem Git-PR-Throughput, nicht an Selbstberichten. Stärker bei Junior-Entwicklern (27–39 %), schwächer oder nicht signifikant bei Seniors. Das ist robust, aber auch hier: Die meisten Teilnehmer arbeiteten mit IDE-Assistenz, also Phase 1 bis 3.
DORA 2024 bringt dann die Nuance, die in Vendor-Ankündigungen nie vorkommt: 75 % der befragten Entwickler nutzen AI für mindestens eine Aufgabe. Und: Jede 25-%-Steigerung in der AI-Adoption korreliert mit ungefähr 1,5 % weniger Delivery-Throughput und rund 7,2 % weniger Delivery-Stability, zumindest in der Breite, über alle Teams.3 39 % der Befragten vertrauen dem AI-Output nur mäßig. DORA 2025 bestätigt den Trend: über 90 % der Entwickler nutzen AI im Workflow, median rund zwei Stunden täglich.4 Der Stability-Trade-off bleibt sichtbar, lässt sich aber durch sieben Team-Praktiken eines "AI Capability Model" teilweise abfedern.
Und dann ist da noch das METR-Experiment von Anfang 2025, das ich als Anti-Hype-Anker für ernsthafte Diskussionen empfehle: Sechzehn erfahrene Open-Source-Maintainer mit AI-Tools — Cursor plus Claude 3.5/3.7, also die zum Studien-Zeitpunkt Anfang 2025 verfügbaren Modelle — wurden bei 246 realen Repository-Tasks gemessen, within-subject (jeder Entwickler war sein eigenes Control).5 Ergebnis: 19 % langsamer als ohne AI. Subjektive Einschätzung: 20 % schneller. Die erfahrenen Entwickler glaubten, sie seien schneller, waren es aber messbar nicht. Wichtig zur Einordnung: Mit n=16 ist die Stichprobe klein; die Autoren selbst nennen die statistische Power "gerade ausreichend". Das ist ein Datenpunkt mit Vorbehalt, kein finaler Beweis — aber ein zu deutlicher Vorbehalt, um ihn beim internen AI-Coding-Roll-out zu ignorieren.
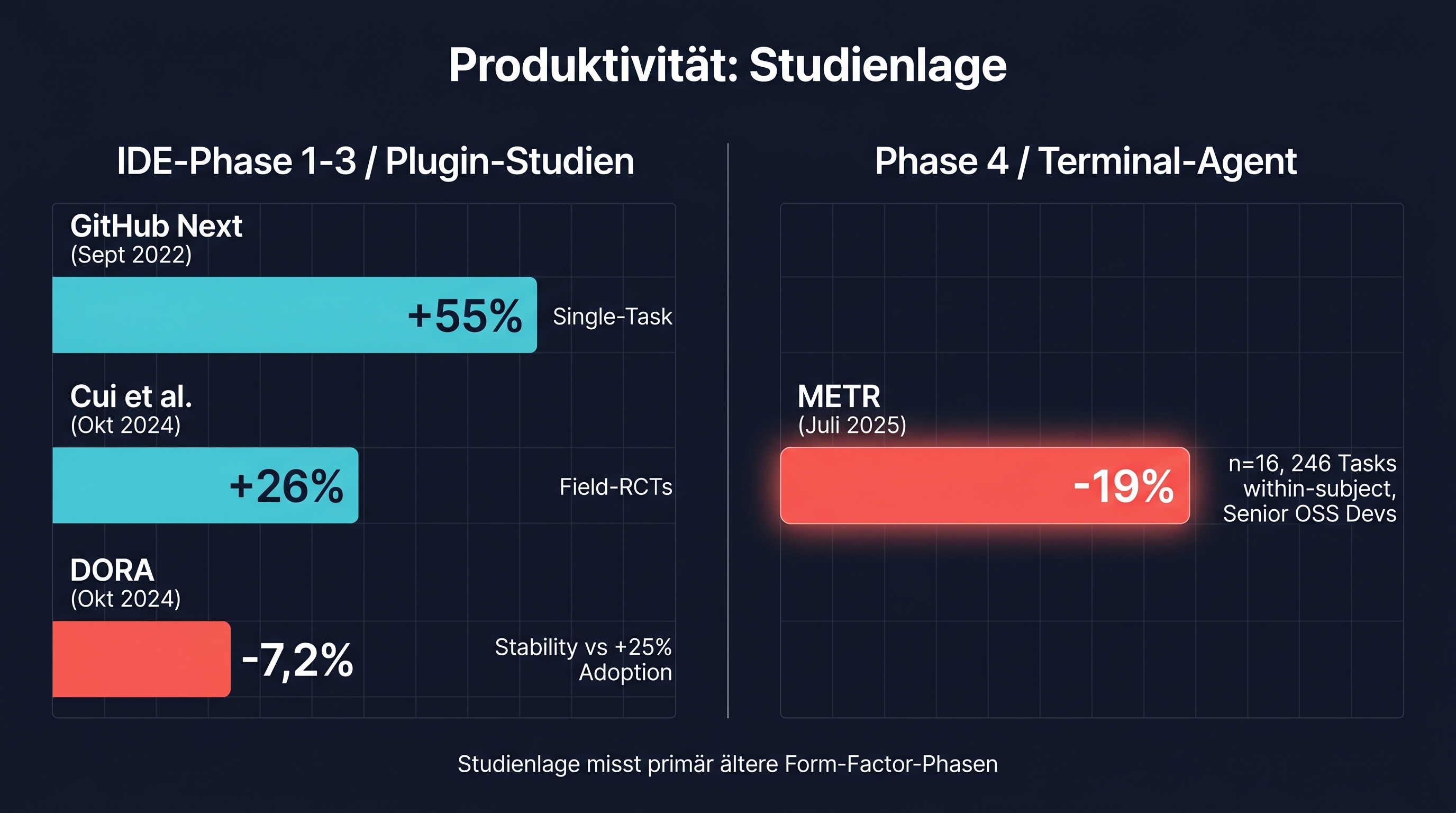
Das ist kein Argument gegen AI-Coding. Es ist ein Argument dafür, die Form-Factor-Phase ernst zu nehmen. IDE-Plugin-Studien messen Code-Completion-Acceptance in einem Workflow, der vom Entwickler kontrolliert wird. Terminal-Agent ändert die Grundstruktur des Workflows. Dass Senior-Devs mit Phase-1-bis-3-Tools langsamer werden, überrascht wenig: der Kopf-Overhead des "AI-Babysitting" frisst den Speed-Gewinn auf. Phase-4-Tools mit sauberem Plan-Step, Diff-Review und klarer Aufgabentrennung bringen strukturell andere Voraussetzungen. Gemessen ist das aber noch nicht belastbar, und das ist die ehrliche Lücke.
Der Punkt, der mir in der öffentlichen Debatte zu wenig Aufmerksamkeit bekommt, ist dieser: Claude Code erzwingt eine Dokumentations-Disziplin, die vorher freiwillig war und damit oft nicht stattfand.
CLAUDE.md-Dateien und Skills (jeweils eine SKILL.md im Skill-Verzeichnis) sind keine netten Extras. Sie sind der Mechanismus, durch den implizites Team-Wissen — "bei uns hat der Terraform-State diese Struktur", "API-Keys kommen aus Vault, nie aus .env", "das Build-System hat diesen spezifischen Workaround wegen eines Go-Bugs von 2023" — in explizite, für den Agenten lesbare Form gebracht wird. Context Engineering im direkten Sinn: dem System zur Laufzeit den richtigen Kontext geben, nicht als nachträgliches Briefing, sondern als Infrastruktur.6
Was ich dabei beobachte, mit Teams, die das ernsthaft angehen: Der erste Schmerz ist das Schreiben der Dateien. Das ist mühsam, weil niemand gerne dokumentiert, was er für selbstverständlich hält. Der zweite Schmerz ist das Feststellen, wie viel Wissen tatsächlich nirgendwo aufgeschrieben war. Und der dritte Schmerz — der überraschende — ist, dass das jetzt Konsequenzen hat, weil der Agent exakt das tut, was in der Dokumentation steht, und nicht das, was die Entwickler still wussten.
Dieser Zwang zur Externalisierung ist kein Bug. Es ist der eigentliche industrielle Hebel, der weit über AI-Produktivität hinausgeht: Teams, die CLAUDE.md ernsthaft betreiben, machen nebenbei Onboarding schneller, Übergaben sicherer, Bus-Faktor kleiner. AI ist hier der Katalysator für etwas, das schon immer gut gewesen wäre.
Jetzt zur Debatte, die den Anlass für diesen Post gegeben hat.
Anthropic hat die Nutzung der subventionierten Claude-Subscription über Drittanbieter-Tools eingeschränkt — am breitesten dokumentiert für OpenClaw und allgemein Third-Party-CLI-Wrapper, im Branchen-Diskurs auch im Kontext von Open Code diskutiert. Wer das gleiche Anthropic-Modell über solche Tools nutzen will, fällt auf API-Pricing zurück, das deutlich teurer liegt. Aus dem Diskurs in Foren, YouTube-Videos und Blogs lese ich zwei Lesarten: legitime Plattform-Strategie innerhalb von Anthropics Rechten, oder ein Zeichen, dass Anthropic den Application-Layer aktiv gegen Drittanbieter schützt.
Ich halte das für eine faire Beschreibung. Steelman der Gegenposition: Anthropic subventioniert Claude.ai-Subscriptions, weil ein direkter Customer-Relationship-Kanal für ein Frontier-AI-Lab langfristig wichtiger ist als Plattform-Offenheit. Das ist keine Bösartigkeit, das ist Plattform-Strategie. Jeder, der AWS, Apple und Google in den letzten zehn Jahren beobachtet hat, kennt das Muster.
Die interessantere Frage dahinter lautet: Was ist der eigentliche Edge im Application-Layer, wenn Modell-Qualität zunehmend vergleichbar wird? Open Code wird in der Community als gleichwertige Alternative positioniert: vergleichbare Tiefe, MCP-Tools, freie Modelle out-of-the-box. Ich bin mir hier unsicher, wie der direkte Feature-Vergleich in der Praxis aussieht, weil keine belastbaren unabhängigen Tests vorliegen. Was ich mit Sicherheit sagen kann: Der Wettbewerbsdruck im Application-Layer ist real und hoch. Wenn Modell-Qualität commodity wird, entscheidet Approachability, Tooling-Integration und — ja — Pricing-Kanal.
2026 könnte das Konsolidierungsjahr werden. Eine wiederkehrende These im Branchen-Diskurs: Viele LLM-Wrapper werden nicht überleben, weil der Differenzierungsraum zu schmal ist. Ich halte das für plausibel, würde es aber nicht als Gewissheit formulieren: zu viele Variablen, zu schnelle Modell-Entwicklung.
Ich nutze Claude Code seit mehreren Monaten als primäres Werkzeug für alles, was über Einzeldatei-Änderungen hinausgeht. Meine ehrliche Einschätzung: Der Phase-4-Wechsel kostet am Anfang mehr, als er gibt. Die ersten zwei Wochen sind langsamer, nicht weil das Tool schlecht ist, sondern weil man lernt, wie man Aufgaben so aufbereitet, dass der Agent sie sauber bearbeiten kann. Das ist der J-Kurven-Effekt in der Praxis: vorher schlechter werden, um langfristig besser zu sein.
Was mich davon überzeugt, dass es sich lohnt, ist nicht Geschwindigkeit bei Einzelaufgaben. Dafür war Phase 2 oder 3 oft ausreichend. Es ist das Skalieren auf Projektweite: Aufgaben, die vorher zerfielen, weil kein Mensch den vollständigen Kontext im Kopf halten konnte, werden handhabbar, wenn der Kontext in Dateien externalisiert ist und der Agent ihn jederzeit abruft.
Ob das für jeden DevOps-Lead oder Mittelstands-CTO sofort der richtige Schritt ist, da wäre ich vorsichtig mit einer pauschalen Empfehlung. Teams mit starker Dokumentationskultur haben einen deutlichen Anlauf-Vorteil. Teams, die noch im mündlichen Überlieferungs-Modus arbeiten, müssen zwei Veränderungen gleichzeitig stemmen: das Tool und die Kultur.
Das ist keine Warnung vor dem Tool. Es ist eine Warnung vor dem Mythos, dass Phase 4 automatisch schneller und besser ist. Der METR-Befund für erfahrene Senior-Devs sollte jedem zu denken geben, der das intern verkaufen will.
Wer jetzt anfängt oder den nächsten Schritt plant, sollte die Wahl des Tools von der Frage der Team-Reife trennen:
Für Teams in Phase 1–2 (Copilot, Cursor): Die Productivity-Grundlage ist da, die Studien belegen den Gewinn. Bevor Phase 4 sinnvoll ist, lohnt sich eine ehrliche Bestandsaufnahme: Wie viel Projekt-Wissen liegt in Dokumenten, wie viel in Köpfen? Wenn die Antwort "mehrheitlich Köpfe" lautet, ist CLAUDE.md-Disziplin der wichtigere nächste Schritt als das nächste Tool.
Für Teams, die Phase 4 evaluieren: Pilot mit einem klar abgegrenzten Projekt, das drei Voraussetzungen erfüllt: gute vorhandene Dokumentation, tolerable Fehlerkosten, aktive Review-Kultur. Diff-Review ist in Phase 4 nicht optional. Der Agent schreibt Code in einer Geschwindigkeit, bei der blind akzeptieren ein Sicherheitsrisiko ist.
Zur Open-Code-vs-Claude-Code-Frage: Wenn das primäre Modell Anthropic ist und die Kosten relevant sind, ist der Feature-Vergleich zwischen Claude Code und Open Code eine echte Überlegung wert. Ich würde das aktuell nicht pauschal entscheiden, bevor unabhängige Tests mehr Klarheit gebracht haben. Was ich nicht empfehlen würde: den Tool-Wechsel primär auf Basis der Pricing-Debatte treffen, ohne die Workflow-Frage — Phase und Reife — vorher geklärt zu haben.
Die Modell-Frage — Opus 4.5 gegen GPT 5.2 Codex gegen offene Alternativen, Stand Januar 2026 — ist für die allermeisten Teams sekundär. Die OpenAI-Cerebras-Partnerschaft könnte Inferenz-Speed auf vierstellige Tokens pro Sekunde heben, und es wird spekuliert, dass drei schnelle Iterationen dann eine langsame Single-Shot-Iteration überbieten könnten. Das ist interessant. Aber ob Tokens-pro-Sekunde der entscheidende Differenzierungshebel ist, oder Harness-Qualität und Kontext-Engineering, ist noch offen.
Meine Einschätzung: Der Edge liegt mittelfristig nicht im Modell, nicht im Tool-Name, sondern darin, wie gut ein Team lernt, mit dem Terminal-Agent zu arbeiten, und das setzt voraus, dass das implizite Wissen zuerst explizit wird.
Ausgangspunkt waren Diskussionen rund um Claude Code, Open Code und die Form-Factor-Verschiebung in AI-Coding, verteilt über YouTube-Videos, Blog-Posts und Foren-Threads im Januar 2026. Ich habe die strukturellen Beobachtungen (Vier-Phasen-Modell, Workflow-Inversion, Wrapper-Konsolidierungs-These) gegen die mir vertrauten Studien gegengeprüft: GitHub Next und METR aus primären Quellen, DORA aus den offiziellen Google-Berichten, Cui/Demirer aus dem SSRN-Preprint.
Schreibprozess: Erstentwurf mit Claude Sonnet 4.5 auf Basis eines strukturierten Skeletts. Wo ich vorsichtig formuliere, wo ich klar Stellung beziehe, wie sich die Argumentation aufbaut, an welchen Stellen ich die Gegenposition fair durchdenke — das habe ich manuell überarbeitet. Nicht weil der Entwurf falsch lag, sondern weil diese Entscheidungen sich in meinem Kopf entwickeln müssen, nicht von einem Modell vorformuliert werden können.
Den vollständigen Workflow beschreibe ich in AI-gestützte Wissensarbeit: Wie ich meinen Recherche- und Schreibprozess neu aufbaue.
Kalliamvakou, E. et al. (2022). Research: quantifying GitHub Copilot's impact on developer productivity and happiness. GitHub Next. GitHub Blog ↩︎ ↩︎
Cui, Z., Demirer, M., Jaffe, S., Musolff, L., Peng, S., Salz, T. (2024/2025). The Effects of Generative AI on High-Skilled Work: Evidence from Three Field Experiments with Software Developers. SSRN Preprint (zuletzt 2025 überarbeitet), spätere Journal-Version in Management Science (2026). SSRN / Management Science ↩︎
Google Cloud (2024). Accelerate State of DevOps Report 2024. DORA. Google Cloud ↩︎
Google Cloud (2025). State of AI-assisted Software Development 2025. DORA. Google Cloud ↩︎
METR (2025). Early 2025 AI Experienced OS Dev Study. METR Blog / arXiv:2507.09089 ↩︎
Lütke, T. (Juni 2025). X/Twitter — Shopify-CEO Tobi Lütke führte den Begriff "Context Engineering" am 19. Juni 2025 als Alternative zu "Prompt Engineering" ein. Sechs Tage später, am 25. Juni 2025, hat Karpathy ihn endorsed und mit der Definition "the delicate art and science of filling the context window" popularisiert: Karpathy auf X. ↩︎
Als wir unseren Beitrag HashiCorp Nomad and Vault: Dynamic Secrets veroeffentlichten, lief die Demo ausschliesslich als Python Flask-Anwendung. Seitdem ist das
2.500 API-Endpoints. Jeden einzelnen als MCP-Tool exponiert, das wären laut Cloudflare 1,17 Millionen Tokens allein für die Tool-Definitionen, bevor der Agent
Jedes Nomad-Tutorial, das Sie online finden, verwendet den docker-Treiber. Das ist verstaendlich — Container sind portabel, Images buendeln alles, und Docker
In unserem vorherigen Beitrag ueber HashiCorp Nomad und Vault: Dynamic Secrets haben wir den gesamten Lebenszyklus des Secrets Managements fuer eine Python
In den letzten zwei Wochen haben wir drei Mesh-VPN-Lösungen einzeln vorgestellt: NetBird, Tailscale und Headscale. Drei Posts, drei Produkte, eine Frage blieb
Sie interessieren sich für unsere Trainings oder haben einfach eine Frage, die beantwortet werden muss? Sie können uns jederzeit kontaktieren! Wir werden unser Bestes tun, um alle Ihre Fragen zu beantworten.
Hier kontaktieren