

HashiCorp Nomad and Vault with .NET: ASP.NET Core in a Secure Workload
When we published our HashiCorp Nomad and Vault: Dynamic Secrets post, the demo ran exclusively as a Python Flask application. Since then, the repository has

The previous article, Tool-Surface Compression, was about getting external functionality, entire APIs and systems, into the agent as token-efficiently as possible. MCP-Server or CLI is exactly the choice of how you trim that surface: Cloudflare compresses thousands of endpoints into two MCP tools, Zechner's pi manages with four shell primitives and no MCP at all, and both poles converge on the same narrow seam. That was one lever on the token load, not the only one.
This time I am taking the next one, which sits independently beside it. No matter how functionality enters the agent, the output that tools return at runtime stays raw and verbose. And with grep, with the test runner, with every third-party tool whose default output was not built for agents and cannot easily be rewritten, you cannot fix that at the source. This is exactly where an entire class of tools comes in: it filters output from the outside, precisely because it cannot change the command itself. Output proxies, boilerplate compressors, middleware. In the previous article, this layer was deliberately out of scope.
These tools are not new. I have been watching them for a while, just with a different focus. By now they form a whole family: I looked at five tools, one with over 60,000 GitHub stars (as of June 2026), and since October 2025 there is a first paper that measures the core assumption systematically rather than just citing product numbers. What I left out last time is its own topic, and this post picks up exactly that layer.
Back to the frame for a moment, because the rest does not make sense without it. In the previous article I separated two cost types. There is the fixed tax on tool definitions, which grows with the number of tools (cardinality). And there is the variable tax on what each call returns. The structure axis addresses this variable tax at the origin: the response is already lean and structured at the source, rather than arriving as a raw dump.
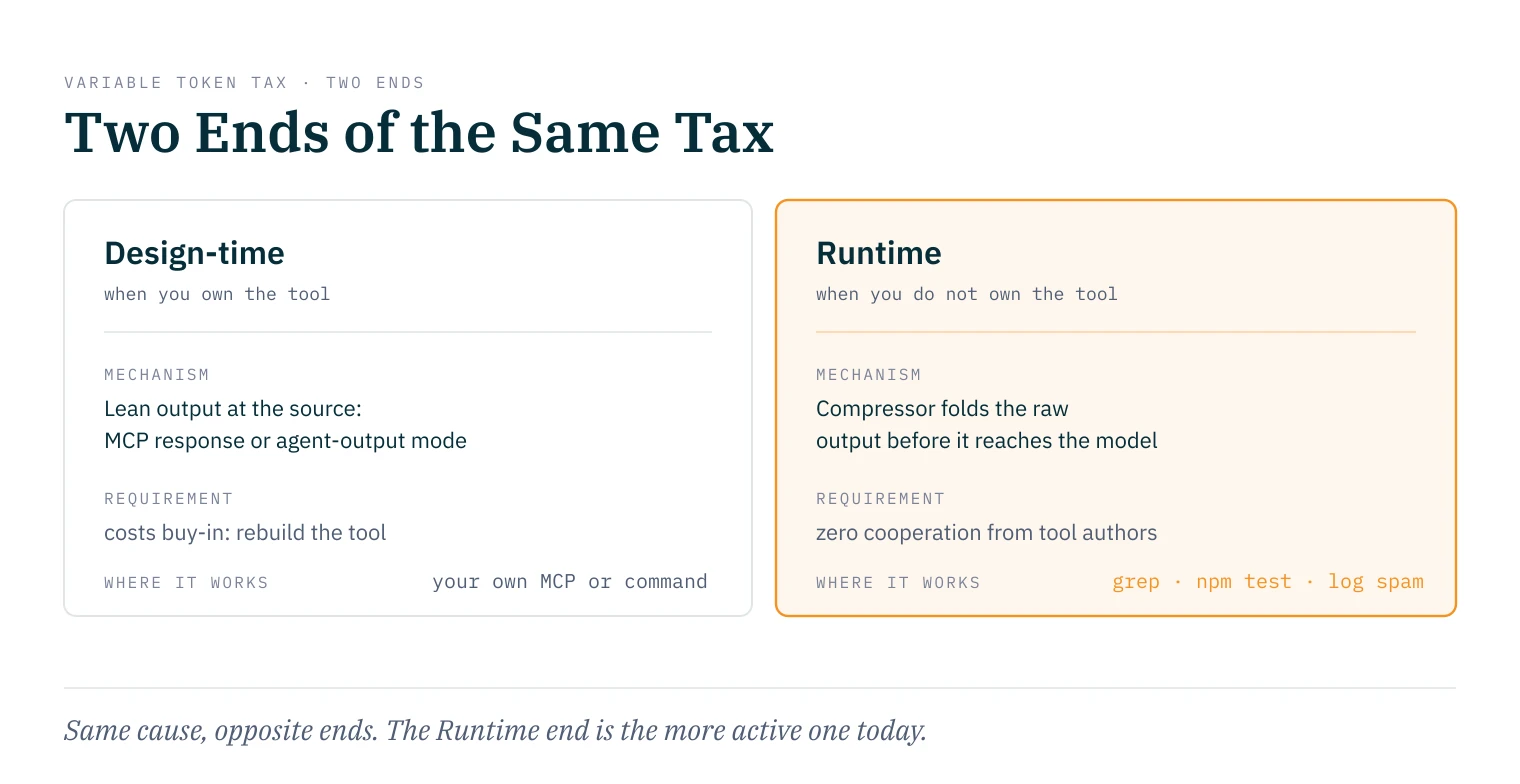
The variable tax has two attack points, not one.
One end is Design-time: when I own the tool, I shape the response to be narrow at the source. For an MCP-Server that means LSP-style queries instead of file dumps, "pointers over copies", normalized minimal responses. For a custom command or CLI it means building in an agent-output mode, a compact format for the machine reader instead of the human-readable default. The noise never gets generated in the first place. This fixes the problem where it originates, but it costs buy-in: I have to rebuild or build the tool myself.
The other end is Runtime: the tool keeps returning raw, verbose output, and a compression layer in between folds it down before it reaches the model context. This fixes nothing at the origin, but it needs zero cooperation from the tool authors. It works on grep, npm test, and any log spam I cannot rewrite.
Same cause, opposite ends. And while the previous article covered only the Design-time end, the Runtime end is where the market is more active right now.
I call this class the Context-Compression-Layer: a tool class that sits between tool execution, the read path, and the model context, and reduces what actually reaches the model from tool outputs, logs, RAG chunks, files, or conversation history. The claimed token reduction across this tool family is typically 60 to 95 percent. I will come back to those numbers; they are the sore point.
Tools in this class arrange themselves along a few dimensions. Headroom, one of the tools, openly categorizes adjacent tools by Scope (what gets compressed), Deploy (how it integrates), Local (does data stay on-premise), and Reversible (can compression be undone). That is a usable map, so I will use it.
"Compression" is the umbrella term here, but three distinct mechanics live underneath it: filter, externalize, replace-the-read-path. What matters for each member is which one it actually does.
That last sentence is the actual point. These tools do not just compete; they stack. You do not pick one, you stack them: a broad layer on top running a narrow, fast shell compressor underneath. That is a different mental model than "which tool is best."

One limit of the whole class surfaced above with RTK: the shell hook only fires on Bash calls, so what the agent reads through its built-in Read and Grep tools stays uncompressed. There is a second answer to exactly that gap, and it takes a different approach. It does not compress the output; it makes the grep unnecessary. A tool like Graphify builds the codebase once into a queryable knowledge graph, commits it to the repo, and redirects the agent via hook away from reading files and toward targeted graph queries. Over 69,000 stars (as of June 2026), MIT; the claimed savings of roughly factor 70 per query come from the README and one large example repo, so the same caution applies here as with all numbers in this piece. The direction is different from the compressors: not making verbose output smaller, but avoiding the expensive read path entirely. This path is not free, though. It trades accuracy for cost, just at a different point than the compressors. The read path is the ground truth; it reads the file as it is. The graph is a derived layer on top, and Graphify admits this by tagging its edges as EXTRACTED, INFERRED, or AMBIGUOUS. A graph query is cheaper and faster, but it can return an inferred edge where file-reading would have returned the fact.6
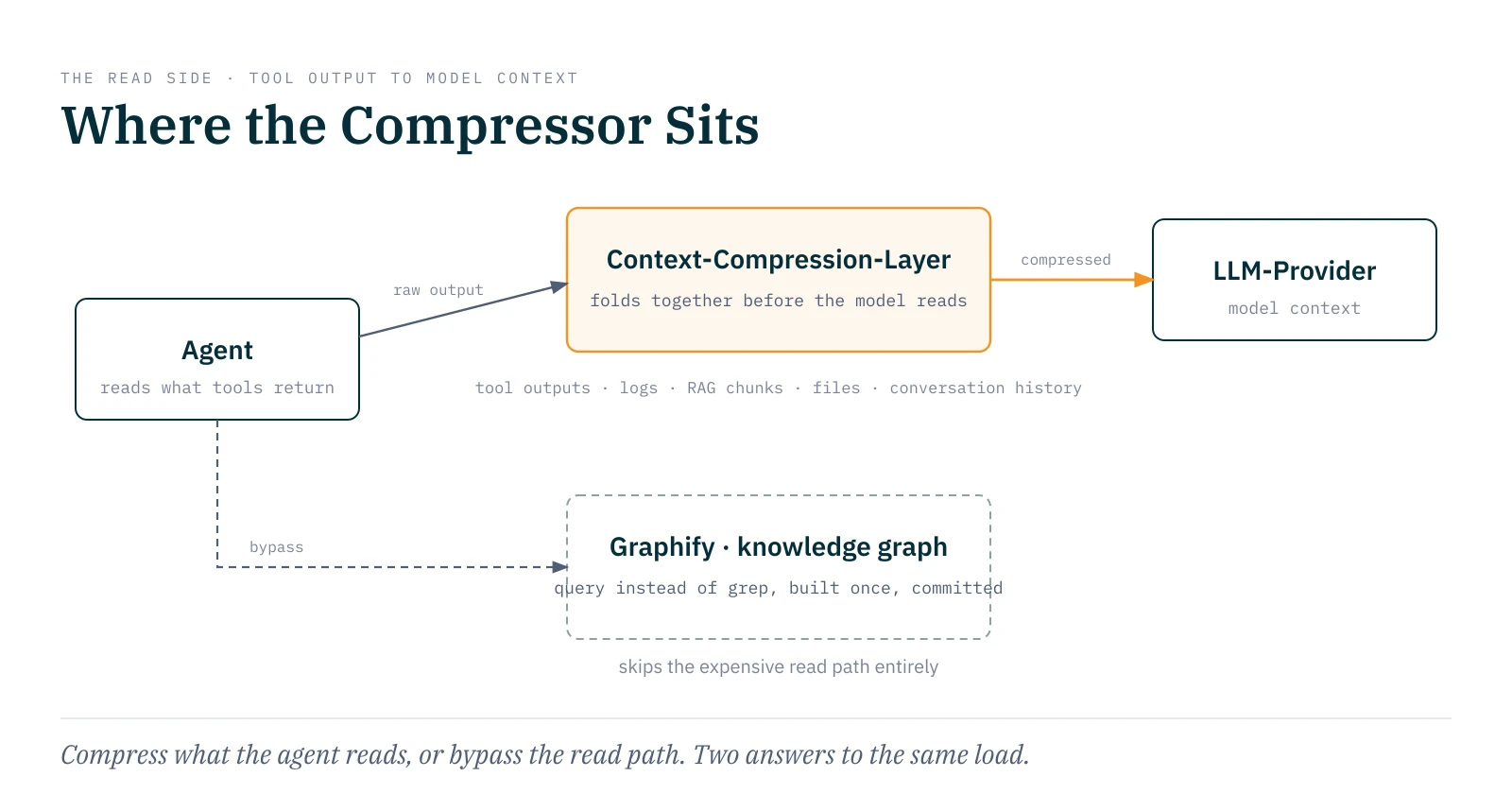
The three mechanics can now be mapped to the tools. RTK and ctx-wire actually filter: they shorten and group output. ctx-zip and Headroom externalize: they write large results away and give the model only a reference, which is closer to retrieval than compression. Graphify replaces the read path so that the expensive raw path never gets taken. What they share is not the mechanism but the position in the stack: they all sit between what an agent could read and what actually gets into the model context.
In the previous article, the central observation was a convergence: Cloudflare, AWS, and a minimal single-player harness like pi approach the same form from opposite ends, a few primitives plus code that composes. Design-time, at the surface.
Here I see the same movement, one layer deeper. While vendor surfaces converge design-time toward a few primitives, a middleware market is growing in parallel that reduces the output load at runtime. A single Rust binary, a TypeScript AI-SDK plugin, a local intelligence layer, all with the same promise in the README. Same attractor, different layer. I find that worth noting.
Now to the 60 to 95 percent. Those figures come, on sober inspection, almost entirely from the projects' own READMEs, from commercial providers as much as from open-source ones. Headroom backs its reversibility claim with a sample around one hundred cases; RTK provides none; the rest falls between. "Same answers" is a marketing line, not a verified property. Anyone bringing this class into a regulated context should know that.
There is also field evidence by now, and what it shows above all is how much a compressor delivers depends almost entirely on how optimized the pipeline in front of it already is. In a LinkedIn thread, Mitko Vasilev reported that Headroom on his already aggressively optimized coding stack came nowhere near the marketing number: expected 90 percent, measured 4.8; several practitioners in the same thread reported around 4 to 10 percent on vanilla Claude Code or Codex, rather than the 70 to 90 from the product page. The meager percentages become questionable once you factor in the other side: one person reported that the compressor cut too aggressively and the harness made up for the missing data with additional calls; Vasilev himself puts the overhead of his layer at around three percent, plus latency. The same voices also make clear the case where the layer does deliver: a path where no one has tuned anything yet, like a GitHub Copilot subscription proxied straight through, can yield the high percentages. Anecdotal, not a controlled benchmark, but the warning sign is clear: the README percentages are the ceiling for the unoptimized case, and the more you have already tuned up front, the less the compressor has left to do.7
This is exactly where the ACON paper becomes interesting. ACON (Agent Context Optimization) optimizes compression not through hardwired filters but through a learned instruction in language space: you take pairs of trajectories where full context succeeds and compressed context fails, let a model analyze the cause, and adjust the compression guideline. The measurements are vendor-independent and point in the right direction. 26 to 54 percent fewer peak tokens, at the same or better accuracy, not despite worse. Distilled into smaller models, over 95 percent of accuracy is retained.8
Two things I take from this. First: ACON shows that compression can maintain task accuracy, measured independently rather than claimed by the tool itself. But it supports the premise, not the class. ACON measures its own learned guideline, not the static tools this piece covers. That is a different mechanism. Achievable is now demonstrated. That the tools achieve it is not. Second, and this is the sharper line: the static-versus-learned axis. Most tools filter statically, with regex, TOML, or hardcoded logic, tuned to known patterns. RTK ships strategies for over 100 commands; ctx-wire filters via TOML rules you define per case. For a non-standard or new tool that has neither a strategy nor a rule, there is correspondingly little left to capture. That is the structural limit of the static approach, not a bug in any individual tool.
One exception points in the other direction: LeanCTX markets itself not as a filter but as context intelligence that decides and remembers. Whether there is something genuinely learned and adaptive behind that label, or just a heuristic, the self-description does not say, and it has not been independently measured. ACON is the learned counterpart that actually shows this direction: a policy that adapts where a static filter would cut exactly the line the agent needed, and that is not limited to a list of known commands. The direction is hinted at in the tool market. It is only measured in ACON.

The per-tool comparison itself, RTK against Headroom against ctx-wire, remains open. I draw that boundary deliberately; it is the next step I have not yet taken.
This makes it possible to frame the decision I actually care about. Reduce the variable token tax, yes, but at which end?
Design-time, when I own the tool. If I am building the MCP-Server myself, the response structure belongs in the design; if I am writing the command myself, it gets a compact agent-output mode instead of the verbose default. Structured queries, narrow responses, the thinnest viable layer, and it costs nothing at runtime.
Runtime, when I do not own the tool. grep, the test runner, a third-party MCP-Server, a vendor CLI: I cannot rebuild those, so I put a compressor in front. Retrofit, tool-agnostic, effective immediately, coarser.
And one hidden cost that I have not yet calculated but believe is real: a layer that compresses prefixes can undermine the provider-side KV-cache hits you have worked hard to maintain elsewhere. Compression saves tokens and can simultaneously cost cache hits. Where that trade-off tips, I do not know. This is one of the places I am currently measuring myself.
The more precise version of the original thesis is now: the variable token tax is a target with two attack surfaces, and the industry is building at both simultaneously. At the Design-time end, surfaces converge toward a few primitives. At the Runtime end, a distinct middleware layer is emerging, one that stacks rather than just competes, and whose core premise, that compression holds accuracy, is getting its first vendor-independent support. The individual tools do not have that yet.
The question I carry forward is the static-versus-learned axis. Today's tools sit almost entirely on the static side, because that is cheap and immediately deliverable. ACON shows that the learned end works. My guess is that the class moves there over the next few quarters, and I would rather test that against real per-tool benchmarks than take it on faith.
That benchmark is not an exotic undertaking: the same task once without and once with a compressor, measuring not the token savings but whether the answer stayed the same, so fidelity, completeness, no new hallucinations. The tools are ready to go, offline against a fixed task set like RAGAS, DeepEval, or promptfoo, or against real production traces like Dynatrace's dt-evals. The number that counts is not 60 to 95 percent saved; it is whether the task came out just as well.
If you are building an agent stack today: first figure out which part of your token load comes from tools you own and which comes from third-party tools. The first end you fix in the design. For the second, you put a compressor in front, and you choose it by Scope, Locality, and Reversibility, not by the README percentages.
One final boundary, to keep the frame clean. The entire tax here sits on what the agent reads: tool output, logs, third-party context. Alongside that there is a separate tax on what the model itself writes, the length of its own responses. This is not only a cost question: a paper from March 2026 shows that enforced brevity on the response side can actually raise the accuracy of large models, because it curbs their tendency to over-reason, on some tasks enough to flip the ranking between small and large models.9 That is a separate axis with its own evidence and deserves its own piece, not a footnote here.
This post is part of a series on AI and software architecture. The direct predecessor is Tool-Surface Compression; earlier pieces include Harness Engineering and Context Engineering.
The thesis that the variable token tax has two ends came from the previous article, which deliberately left the Runtime class out of scope. The substance for this follow-up I built beforehand in a systematic pass: a framework for the Context-Compression-Layer class plus individual profiles for the five tools (RTK, ctx-wire, ctx-zip, LeanCTX, Headroom) and for the learned compression guideline from the ACON paper. Added at the edges afterward: Graphify as a tool of a different type that does not compress the Read/Grep gap but sidesteps it, and the Brevity-Constraints paper for the response side, which this piece explicitly carves out. Tool numbers are taken from READMEs and flagged as project-claimed; ACON numbers were checked against the full paper text and marked as independent evidence; the Brevity paper is a single-author preprint and treated accordingly. Star counts are as of June 2026 and will age.
Claude Opus 4.8 drafted this in a voice and to standards I taught it step by step; the idea, the weighting, and the limits deliberately left open are mine. I describe the full workflow in AI-Assisted Knowledge Work: How I Am Rebuilding My Research and Writing Process.
RTK (Rust Token Killer), github.com/rtk-ai/rtk. CLI proxy, Apache-2.0, four compression strategies, shell hook fires on Bash calls only; star count as of June 2026. Checked against the README. ↩︎
ctx-wire, github.com/pivanov/ctx-wire. MIT, declarative TOML filters, secret scrubbing, full-log-on-disk, mcp-wrap for MCP output. Checked against the README. ↩︎
ctx-zip, github.com/karthikscale3/ctx-zip. TypeScript, MIT, Tool Discovery plus Output Compaction, Vercel AI SDK. Checked against the README. ↩︎
LeanCTX (lean-ctx), github.com/yvgude/lean-ctx. Local context-intelligence layer in Rust, Apache-2.0; star count as of June 2026. Checked against the README. ↩︎
Headroom, github.com/chopratejas/headroom. Compresses tool outputs, logs, files, RAG chunks; available as library, proxy, or MCP-Server; reversibility / recoverability via cached originals as product promise. Checked against the README. ↩︎
Graphify, github.com/safishamsi/graphify. MIT, AI-coding-assistant skill; builds code, docs, and schemas into a queryable knowledge graph (local tree-sitter extraction) that the agent queries via hook instead of Read/Grep; every inferred edge tagged as EXTRACTED, INFERRED, or AMBIGUOUS. Factor-70 savings and star count (as of June 2026) are README/benchmark-claimed. Checked against the README. ↩︎
Field reports from a LinkedIn thread by Mitko Vasilev (CTO, on-device AI), 17 June 2026. Headroom delivered 4.8 instead of the expected 90 percent on an already aggressively optimized stack, with a layer overhead of around three percent. In the comments: Sean Burke (~4 percent on vanilla Claude Code/Codex, plus additional harness calls from overly aggressive clipping), Rick Raddue (~5 percent), Varun R. (mostly 8 to 10 percent); alongside that, Vasilev and Adam Pippert (Red Hat) noting that an unoptimized path like a proxied GitHub Copilot subscription does yield high percentages. Anecdotal, not a controlled benchmark. Permalink. ↩︎
Kang, M. et al. (2025). ACON: Optimizing Context Compression for Long-horizon LLM Agents. arXiv:2510.00615. arxiv.org/abs/2510.00615. Learned compression guideline via contrastive failure analysis; 26 to 54 percent fewer peak tokens at maintained or improved accuracy; checked against the full paper text. ↩︎
Hakim, M. A. (2026). Brevity Constraints Reverse Performance Hierarchies in Language Models. arXiv:2604.00025. arxiv.org/abs/2604.00025. 31 models, 1,485 problems: enforced response brevity raises large-model accuracy in a causal intervention by around 26 points and reverses size rankings on math and knowledge benchmarks; mechanism is large models' tendency to over-reason. Single-author preprint, checked against the full paper text, treat with appropriate caution. ↩︎
Leverage AI tools to enhance coding efficiency, automate repetitive tasks, and unlock innovative development workflows.
When we published our HashiCorp Nomad and Vault: Dynamic Secrets post, the demo ran exclusively as a Python Flask application. Since then, the repository has
The previous article, Tool-Surface Compression, was about getting external functionality, entire APIs and systems, into the agent as token-efficiently as
2,500 API endpoints. Expose every one of them as an MCP tool and you get, according to Cloudflare, 1.17 million tokens for tool definitions alone, before the
Every Nomad tutorial you will find online uses the docker driver. That makes sense — containers are portable, images bundle everything, and Docker is
In our previous post about HashiCorp Nomad and Vault: Dynamic Secrets we walked through the full lifecycle of secrets management for a Python Flask application
You are interested in our courses or you simply have a question that needs answering? You can contact us at anytime! We will do our best to answer all your questions.
Contact us