

HashiCorp Nomad and Vault with .NET: ASP.NET Core in a Secure Workload
When we published our HashiCorp Nomad and Vault: Dynamic Secrets post, the demo ran exclusively as a Python Flask application. Since then, the repository has

2,500 API endpoints. Expose every one of them as an MCP tool and you get, according to Cloudflare, 1.17 million tokens for tool definitions alone, before the agent has formulated a single request. Cloudflare calls that "Context Suicide."1
Their answer: two tools. search() and execute(). The agent searches for what it needs and runs it. Everything else arrives dynamically, just-in-time, directly from the documentation. Around 1,000 tokens instead of 1.17 million, a reduction of 99.9 percent.2
At the opposite end of the same axis is a tool coming from the other direction. Mario Zechner's pi, the minimal coding-agent harness behind a portion of the current agent wave, exposes exactly four tools: read, write, edit, bash. System prompt and tool definitions together stay under a thousand tokens. No MCP, deliberately and permanently.3 Cloudflare compresses 2,500 endpoints top-down; pi refuses the surface from the start. Two opposing starting points, a surprisingly similar result: few tools, code or shell handles composition, the model sees a narrow seam.
This sounds like an elegant optimization for a special case. Since I first saw the numbers, I think it's more than that: a design principle for the interface between agents and systems that goes deeper than raw tool count. The term "tool-surface compression" isn't mine; it circulates in the MCP community, from Atlassian's open-source compressor to a Microsoft Research paper on tool-space interference.4 What I feel is missing in the discussion isn't the term but a clean structure behind it: three axes you can actually turn. And a second question that gets asked less often: why do two tools as different as Cloudflare's Code Mode and Zechner's pi arrive at the same point, and where exactly do they meet?
Fewer tools mean fewer tokens for tool definitions, so more context budget for actual reasoning. That's the original intuition, and it holds. But compression has three axes, not one.
Cardinality is the most familiar: fewer tools, lower token tax on definitions, less selection complexity at each action step. With three tools, the choice is trivial. With fifty, it becomes its own reasoning problem. Microsoft Research measured the effect; hit rate drops as more tools are active simultaneously, and they reference OpenAI's recommendation to stay under twenty functions.4
Timing adds another dimension. Skill descriptions can sit permanently in context while full content loads on-demand when the task matches. Across dozens of skills this keeps the persistent context small, because only the short descriptions count permanently rather than the full content bodies. This approach, Progressive Disclosure for context, is explicitly named in Zechner's pi.dev documentation: only descriptions are always in context; full instructions load on-demand.5 It's the timing axis: not fewer tools, but tools that only appear when they're needed.
Structure is the sharpest new insight: not fewer tools, but tools that reply with structured answers instead of raw dumps. Rather than spilling fifty files into the context, the agent asks precisely for a function's definition or the relevant parameter types and gets a normalized, minimal response. Jarosław Wąsowski put this as "pointers over copies."6 By 2026 this is no longer a thesis; it's built from three independent directions: as an MCP server over the Language Server Protocol (Serena), as AST operations instead of text spans (CODESTRUCT), and as a pre-indexed code graph (CodeGraph, Codebase-Memory).789 All measurements point the same way: a multiple fewer tokens at equal or better hit rates. The lever isn't the number of tools but the shape of their responses, a design decision made at the MCP server itself.
That shifts the question, and it helps to cleanly separate two cost types. There's the fixed tax on tool definitions, which grows with tool count (cardinality), and the variable tax on what each call returns (structure). Across a full task, a system with many tools that all answer structured queries can end up consuming less context than a system with three tools returning raw grep dumps, because the variable tax per call eats back the fixed advantage of the smaller tool count. Which side wins depends on call frequency and result size. Compression is not only count; it's also form.
Separate from this is an entire class of tools that push the same token load from outside: output proxies and boilerplate compressors that fold tool outputs at runtime. These operate at the middleware layer, not at surface design, and they're deliberately not the subject here.

The Unix philosophy of the 1970s had an intuition that MCP is giving new relevance. cat, grep, awk, pipe. Small composable primitives instead of large specialized tools.
search() and execute() are for an API what grep and pipe are for text. Not because two tools are prettier than a thousand, but because two tools have a defined, small token price.
The difference from Unix: for agents the token price is an extra dimension. A Unix user pays no tax for the existence of programs they don't call. An agent does, at least in many current MCP clients that load all listed tool definitions into the model context whether the agent needs them or not. MCP doesn't strictly require this; a client can filter tools or surface them progressively, but full loading is today's default. That's why the Unix analogy doesn't hold completely, while still supplying the right mental model.
The axes are analytically separable but coupled in practice. Timing changes effective cardinality, and structured responses often require different tool granularity. Cloudflare's Code Mode deliberately couples cardinality and timing by making discovery part of the interface. The separation still helps with thinking: a system with high cardinality but consistent Progressive Disclosure can outperform a few tools that all sit permanently in context.
The strongest effect emerges when all three axes are addressed together.
Cloudflare wasn't alone in 2026. Within a few months, two of the largest cloud vendors delivered the same pattern as an official product, distributing their weight differently across the three axes.
AWS made the AWS MCP Server generally available in May 2026.10 Instead of exposing every AWS API as its own tool, there's a call_aws that executes all 15,000-plus AWS API operations through existing IAM credentials. Add search_documentation and read_documentation, which fetch relevant docs at request time rather than loading them into the context window, and a run_script that lets the agent write short Python code chaining multiple API calls in one pass. That's Cloudflare's Code Mode, built by AWS: few tools, code instead of tool calls, docs on demand. Available in Frankfurt, among other regions.
Microsoft addressed the same trend a few weeks earlier, but at a different axis.11 The Azure Skills Plugin bundles the Azure MCP Server, which offers 200-plus structured tools across more than 40 Azure services, with several Azure skills (azure-prepare, azure-validate, azure-deploy, azure-diagnostics, azure-cost) that load on demand instead of sitting permanently in context. Microsoft doesn't compress radically through cardinality the way Cloudflare and AWS do; they compress through timing and structure: many tools, but structured, plus skills that only surface when the task needs them.
Three of the biggest players, three different emphases on the same three axes. The pattern is no longer an elegant outlier; it's the direction. And Microsoft delivered both sides: the same research division that measured tool-space interference as a problem built the answer with the Azure Skills Plugin.
These three are all the same pole, though: large, accumulated surfaces pressed down from above. AWS has fifteen thousand API operations, Cloudflare twenty-five hundred API endpoints, Microsoft two hundred tools across forty services. They compress because their surface is too large to expose. The other pole makes the same movement from the opposite side.

Pi comes from below. Rather than pressing a large surface down, Zechner never builds one: four tools, no MCP. The justification isn't aesthetics; it's an observation about the models. The current generation is trained so strongly to work with bash and the read/write/edit schema that everything beyond it creates more confusion than help.3 "Bash is all you need," Zechner says in the Syntax podcast, and he means it literally.12 When the agent needs another tool, it sits as a CLI tool with a README on disk and gets read only when needed. That's Progressive Disclosure, but at the level of whole tools rather than individual skills.
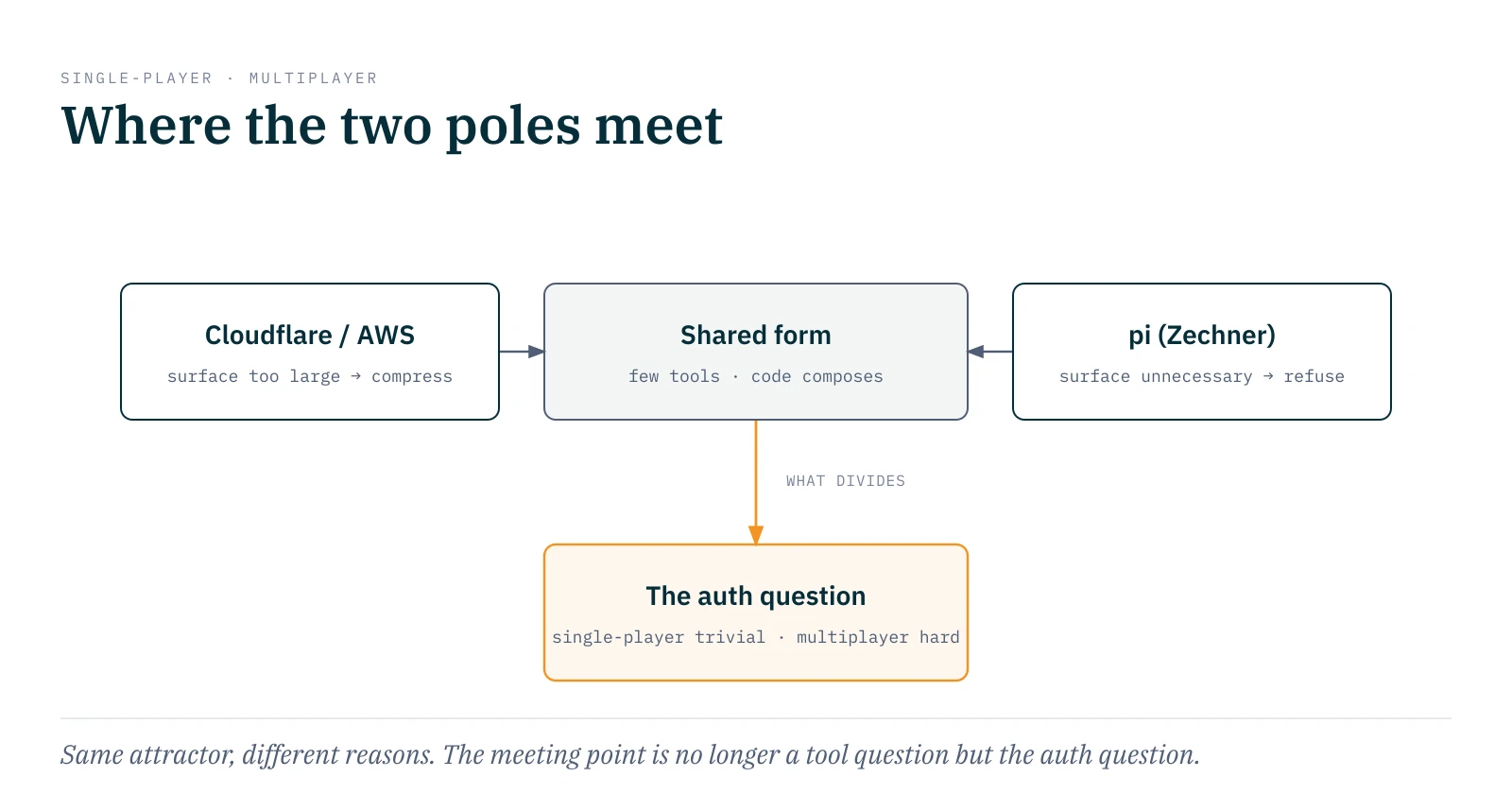
Cloudflare and pi converge in form: few tools, code or shell handles composition, the model sees a narrow seam. But they don't converge in motivation. Cloudflare compresses because the surface is too large to expose. Pi refuses because the surface is unnecessary. Same attractor, different reasons. And the attractor itself is remarkably stable: Cloudflare's search/execute, AWS's call_aws/run_script, pi's four tools plus bash. There seems to be a natural floor of two to four primitives per ecosystem where the surface stabilizes.
The question is what distinguishes the two poles when their form is already the same. The answer is identity and authentication. Pi runs single-player: one person, one machine, auth is trivial because the user already holds all permissions. In that world a CLI with one skill is enough and composition runs through shell pipes, no protocol needed. The hyperscalers run multiplayer: many users, foreign systems, delegated rights. Here auth isn't trivial; it's the hard problem, and that's precisely what a protocol like MCP earns its weight for. The meeting point of the two poles isn't a tool question anymore; it's an auth question.
Right there sits Zechner's sharpest argument against MCP, and it's more precise than the usual token critique. MCP isn't composable: the information one tool delivers must pass through the model's context to be combined with another tool's information. With a shell pipe it flows directly onward; the model only sees the result.12 For the single-player case that's a clear win. For the multiplayer case there remains an open gap: a facade that chains several foreign backends with their own auth into a domain operation, deterministically in code rather than through model context. I haven't seen that semantic composition across auth boundaries as a finished product as of early 2026. It's the point where the two poles haven't found each other for the enterprise case yet.
One clarification so this doesn't sound too tidy: Zechner's "no MCP" targets MCP as context exposition, meaning the tool schemas that flow into the model. It doesn't necessarily target MCP as a pure wire and auth protocol that can live in the code path without burdening the context. The two layers deserve separate evaluation. The single-player pole can do without both. The multiplayer pole needs the second and wants to avoid the first just as much.
We run an MCP server for Pipedrive. Fifty-five tools. Search contacts, create deals, track activities, enrich organizations, query filters, resolve fields.
That's not twenty-five hundred. But it's enough to feel the effect on the cardinality axis. And it surfaces a more specific problem that goes beyond raw count: get_person, search_persons, get_persons_by_filter, find_persons_by_name look like four tools for a single semantic operation, "find a person in the CRM." I should be careful here, because the four names may encode different constraints: exact ID, fuzzy search, saved filter, name search. Whether they can actually collapse into fewer primitives is a design hypothesis, not a measured result.
The compressed version would probably be: search, read, write. Everything else, which entity, which fields, which filters, would be a parameter, not a tool selection.
Whether we rebuild is open. The fifty-five tools have precise descriptions and agents find the right one. But the question "could three tools do the same, and could they return more structured responses?" is in the room. And it gets more relevant as more agents access it simultaneously.
A second observation comes from the development side. Restarting an MCP server mid-dev-roundtrip is expensive, and the more I built the more I tripped over it. Looking for a cheaper loop, I ran into a bridge: small tools that wrap an MCP endpoint and its tools via a single CLI call. That puts the MCP server on the command line: it stays the standardized access layer to the foreign API I only wire up once, but composition moves out of the model context and into the code path. That's exactly where Zechner's shell argument becomes concrete. His point was that MCP isn't composable because information has to go through the model's context; an MCP endpoint that's callable as a CLI flows through a pipe instead, and the model only sees the result.12
We use this pattern in several places now. For our website analytics we connect Plausible, Google Search Console, and LinkedIn each via MCP, but address them in the code path through the CLI: facts are gathered deterministically and stored, and only the shaping of the report costs tokens. The same pattern carries our monthly reports in professional services, where time tracking and invoicing run together in code and the agent handles only the customer-specific report form, and our lead research, where structured shop and technology data is assembled in the code path and fed into categorization through the Pipedrive MCP. Composition stays in code, deterministic and cheap; probabilistic is only the decision at the end.
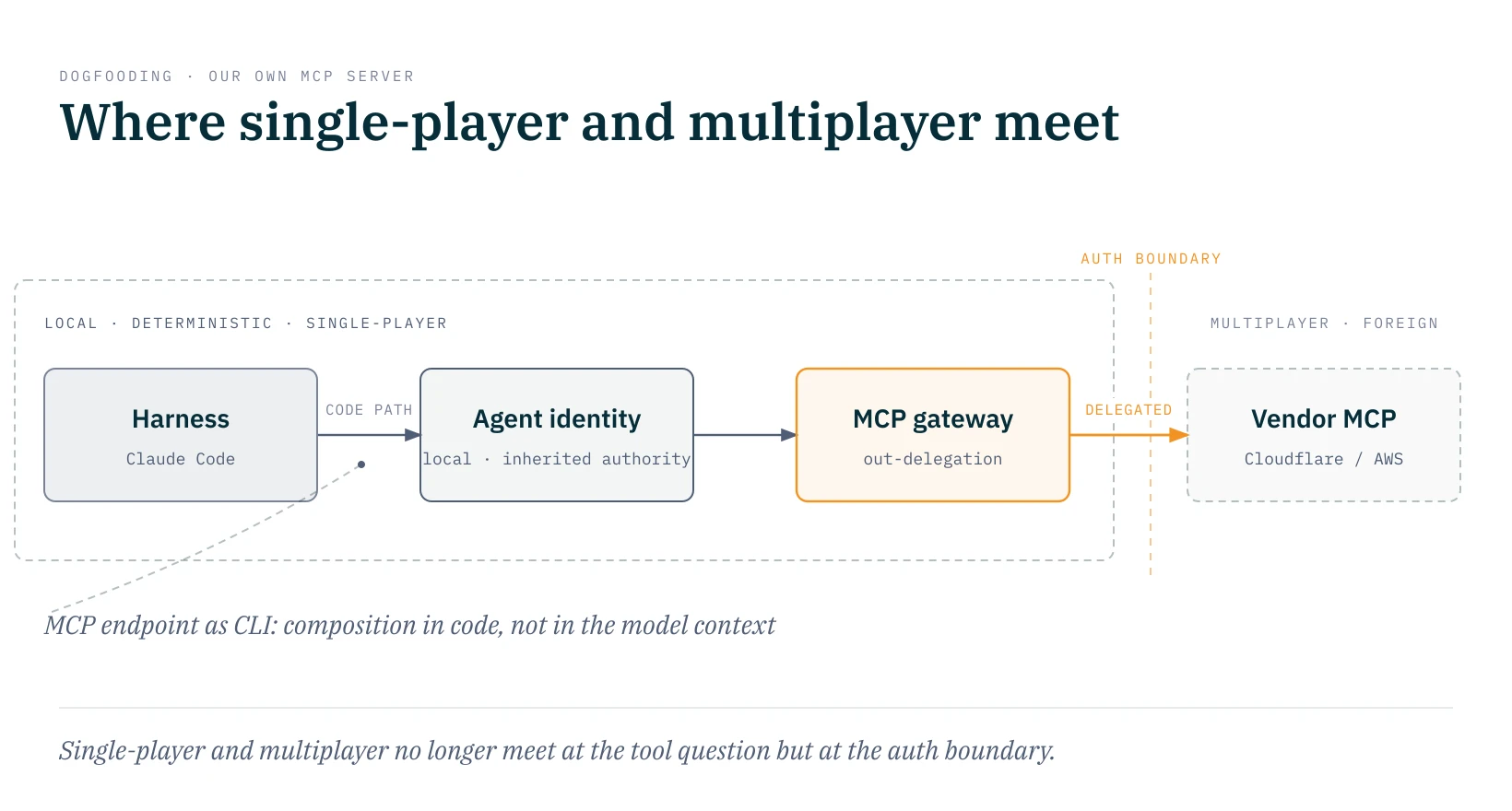
Out of this has grown an idea I'm currently following as an emergent design, without yet knowing where it leads. This is where the single-player and multiplayer sides could come together. The outbound leg from a vendor MCP like Cloudflare or AWS is already covered by their own server. What's missing is the leg before that: from my harness, say Claude Code, through a local workflow or agent identity, to those foreign backends. That leg could run through an MCP gateway that handles delegation outward and migrate step by step behind an MCP facade. That's exactly the semantic composition across auth boundaries I named as an open gap above, except I'm trying it on myself rather than waiting for a product. How an agent identifies itself to foreign backends and what authority it inherits from the user is its own rabbit hole. I'm deliberately not opening it here; I'm gathering material for a post with exactly that focus.
That was a concrete setup from practice. Back to the principle, because one dimension is still missing: time. Tool-surface compression is a design-time decision: which tools do I build? How many, when visible, in what form?
But compression alone isn't enough. There's a complementary runtime mechanism. Boden Fuller describes it as one phase of his "Context Development Life Cycle" that he calls Compile:13 a context compiler selects the right pieces for the current phase, ranks them by relevance and freshness, trims to the token budget, and delivers the minimally sufficient context. The research phase needs different tools than the writing phase. A compiler that decides this per phase is the runtime counterpart to what I plan at design time.
Fuller's pointed thesis, stated explicitly by him as an estimate and not a measurement: this is where, at runtime selection, roughly 99 percent of the gap lies between teams that use coding agents and teams that get reliable results from coding agents.13
Design time and runtime are complementary, not competing. I compress the surface; the compiler selects per phase what gets loaded from it.
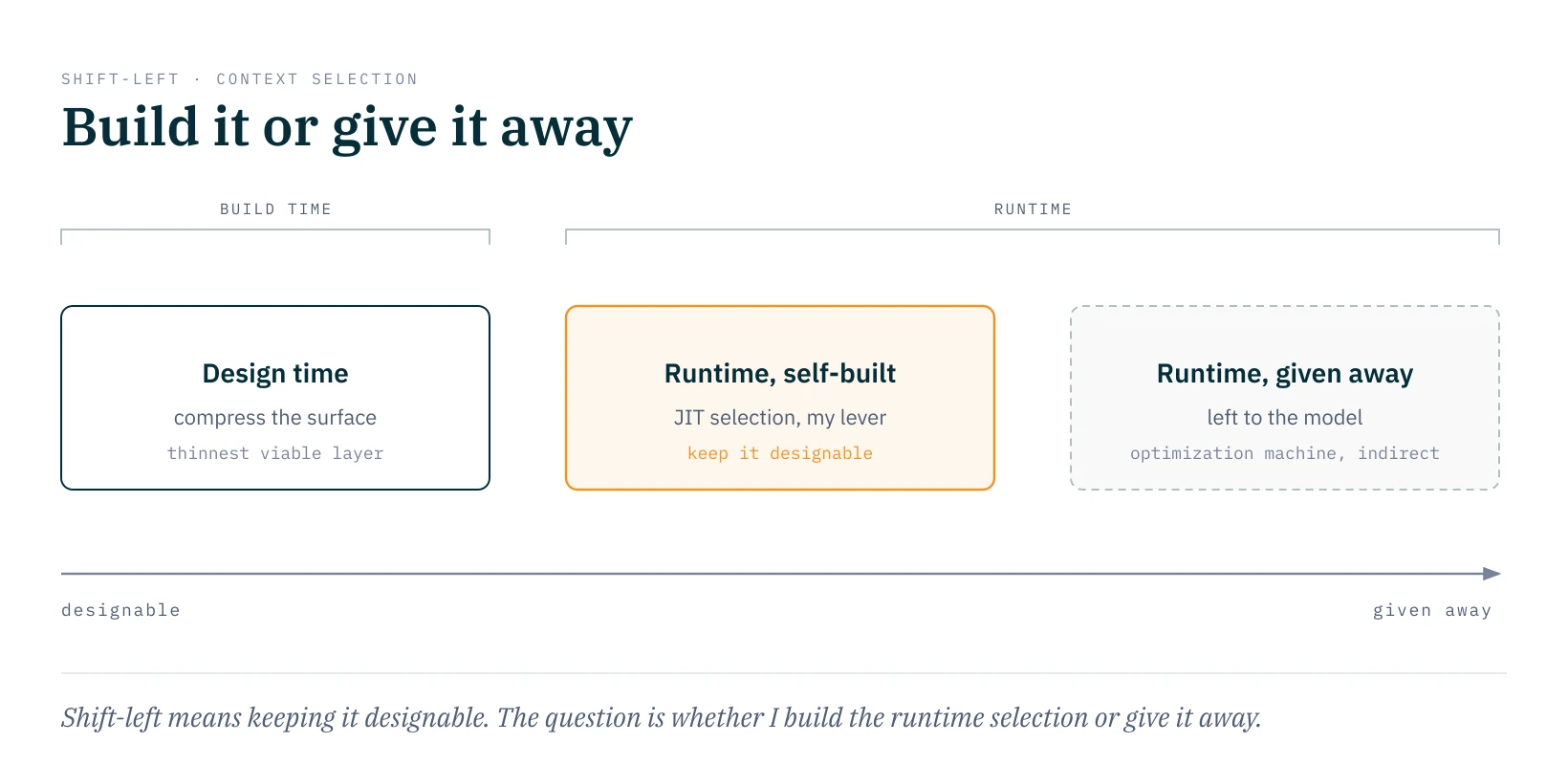
At its core this is the shift-left pattern from software development, applied to context: the more I resolve at build time, the less needs to be negotiated at runtime. A model that has to grab the right one from fifty tools at runtime can get tangled up and lose track of priorities. Into design time, by contrast, I can invest as much effort as needed to work out the thinnest viable layer before anything runs.
Shift-left here doesn't only mean earlier, though. It means staying in control. Fuller's runtime selection is reminiscent of a just-in-time compiler: it optimizes per phase based on what only becomes visible at runtime. And as with a JIT, everything depends on who owns the machine. If I build this selection myself, it's my lever. If I hand it to the model, which decides in autonomous mode what's currently important, I've surrendered it to an optimization machine I can only influence indirectly. What build time can't catch are the unknown unknowns anyway: what becomes relevant in a specific phase can't be fully predicted, and that's exactly what runtime selection is for. The only question is whether I build it or give it away.
It helps to place all this inside a larger discipline. Andrej Karpathy made the term "Context Engineering" prominent in 2025 as a counterweight to "Prompt Engineering":14 not optimizing individual prompts, but actively shaping the entire context available to an agent at a given moment.
MCP is infrastructure-tier now. The handoff to the Linux Foundation in late 2025 and broad adoption across major toolchains make that clear. This is no longer a startup feature.
Tool-surface compression is the design-time component of the compression dimension within Context Engineering. Progressive Disclosure (timing axis) is the on-load component. The context compiler (runtime) is the per-phase selection component. Three distinct levers at the same challenge: how much useful information fits into the limited context window.
Here's the limit of static design, and it needs naming.
Even a perfectly compressed three-tool system degrades over a long session. Raw tool outputs accumulate in the context: grep dumps, stack traces, JSON fragments. Signal-to-noise falls. Wąsowski calls this "context rot"6, and it's temporal, not spatial. It isn't the "lost in the middle" problem (the context is too large); it's the degradation problem (the context was good and now it isn't).
A Chroma study from 2025 tested 18 frontier models and found that all of them get worse as input length grows, with the steepest drop between 100,000 and 500,000 tokens, well before the declared end of their context window.15
Mitigation is structural: atomic tasks, sub-agents with fresh context windows. A research sub-agent explores, hands back a compact summary, and isolates the token burn. Compressing the tool surface is necessary but not sufficient. Context rot requires an architecture decision at a different level.
There's one more consequence that goes beyond token budgets.
A 2026 Google Research blog post on agent system scaling describes a tool-coordination tax that grows super-linearly with tool density, citing as an example a coding agent with sixteen or more tools where coordinating multiple agents becomes more expensive than the parallelization gain.16 That aligns with Mark Burgess' Promise Theory arguments predicting O(N²) growth for coordination overhead in densely interconnected systems.
This means tool sprawl doesn't just cost more tokens; under a fixed compute budget it can push you into worse multi-agent architectures. Six tools still coordinate relatively cleanly. Thirty tools tend to demand orchestration layers that themselves consume context.
The sixteen is an illustrative example, not a measured threshold, and it's coding-domain-specific. I wouldn't generalize it to other domains. But the direction is right.
I don't want to paint too rosy a picture. A study by Galster, Treude, Baltes et al. across 2,853 GitHub repositories found, in an attributed statement, that most repositories stay with static AGENTS.md files and never progress to skills, sub-agents, or compression.17
That doesn't mean the approach is wrong. It means whoever builds this now has a lead that most people don't yet have. That's not a scorecard; it's an assessment of where the field currently stands.
Tool-surface compression isn't an MCP-specific detail. It's the same intuition as Harness Engineering, just at a different abstraction level. Harness Engineering constrains organizational structure: how does the agent decompose work, how does it verify results? Tool-surface compression constrains the tool interface: what does the agent see at all? Both follow the same underlying principle: agents need tighter constraints, not more capacity.
What convinced me most in writing this was the convergence itself. A minimal single-player harness like pi and a multiplayer enterprise product like the AWS MCP Server have almost nothing in common except the result: few primitives, code handles composition, the model sees a narrow seam. They come from opposite ends and meet in the middle. The actual difference at the meeting point is no longer the tool question, which is solved on both sides; it's the auth question: single-player works without a protocol, multiplayer needs one. Everything else, the three axes of cardinality, timing, and structure, is the mechanics of this movement, not its destination. The surface moves, and it moves from both sides toward the same point.
The structure axis surprised me most. I had assumed the question "how many tools?" was the decisive one. Delivering LSP-style structured queries instead of raw file dumps is an answer to a different question: not how many, but in what form. For me, that's the new design decision in every MCP server.
If you're planning an MCP server today, I'd start with three questions:
What are the three most primitive operations in this domain? For a CRM: search, read, write. For a monitoring system: query, filter, aggregate. For a deployment system: plan, execute, observe.
Could the tools return structured responses instead of raw dumps? Rather than "give me all lines containing foo," something like "give me the signature of foo and the three places that call it."
When should which tools be visible? Does every task need every tool, or is there a sensible Progressive Disclosure logic?
Many existing MCP servers feel like they have too many tools because every endpoint became a tool without anyone asking whether that's the right granularity. The designs were built for humans browsing menus, not for agents managing token budgets.
For new MCP servers: start with primitives, not endpoints. Design the shape of responses, not just the count of tools. Plan for a context compiler as the runtime counterpart.
This post is part of a series on AI and software architecture. Previous parts cover the Five Stages of AI Development, Dark Factory Architecture, the Dark Factory Gap, Conway's AI Inverse, and Harness Engineering.
The core thesis, tool-surface compression as a design principle, grew out of the Cloudflare pattern and direct experience with a 55-tool MCP server for Pipedrive. The two Cloudflare sources (2, 1) were verified directly against the official blog posts on blog.cloudflare.com.
The more recent findings (three axes, context rot, LSP queries, context compiler, tool-coordination tax, adoption gap) come from our content wiki. Source URLs are included and the central ones checked against primary texts: the CDLC 99% claim (Fuller, 13), the 2,853-repositories study (Galster et al., 17), the Google scaling post (16, whose sixteen-tool example I deliberately reproduce as illustrative rather than a measured threshold), the pi.dev Progressive Disclosure quote (5), and context rot and the LSP mechanics against Wąsowski's full text (6). The Chroma study (15) is now verified against the source. Attributed and deliberately worded with care remains Karpathy's role with the term (14): popularized, not necessarily first coined. Multipliers that an earlier version carried (Progressive Disclosure, LSP) I walked back to qualitative claims, because the sources support the mechanism, not specific factors.
The two-poles thesis (pi as single-player minimal against the hyperscalers as multiplayer enterprise, meeting point at the auth question) was added in June 2026, after I'd reviewed Zechner's blog post (3) and the Syntax Podcast conversation (12) and incorporated them into the wiki. Both sources are checked against their primary texts; the "not composable" point verified word-for-word against the transcript. The gap of semantic composition across auth boundaries is my own assessment from the wiki work, not a cited product finding.
The first draft was built by a blog-writer agent on Claude Sonnet 4.6; the current version I worked out over many rounds with Claude Opus 4.8. That the text sounds like me is something that was built: the model drafts in a voice and to standards I taught it piece by piece. The ideas, the argumentation, and the weighting are mine; the model is the tool that helps me execute them.
I describe the full workflow in AI-Assisted Knowledge Work: How I Am Rebuilding My Research and Writing Process.
Cloudflare (2026). Code Mode: the better way to use MCP. Cloudflare Blog. blog.cloudflare.com/code-mode ↩︎ ↩︎
Cloudflare (2026). Code Mode: give agents an entire API in 1000 tokens. Cloudflare Blog. blog.cloudflare.com/code-mode-mcp ↩︎ ↩︎
Zechner, M. (2025). What I learned building an opinionated and minimal coding agent. mariozechner.at, November 30, 2025. Four tools (read/write/edit/bash), system prompt plus tool definitions under a thousand tokens, "pi does not and will not support MCP," the CLI-with-README Progressive Disclosure alternative; verified against the full text. ↩︎ ↩︎ ↩︎
The term is established in the MCP community. Atlassian, MCP Compression: Preventing Tool Bloat in AI Agents atlassian.com, with the open-source tool atlassian-labs/mcp-compressor (70 to 97 percent fewer tool-definition tokens). Microsoft Research (2025), Tool-space Interference in the MCP Era microsoft.com: hit rate drops as tool count rises; OpenAI recommends staying under twenty functions. Both verified against the source. ↩︎ ↩︎
Zechner, M. (2026). Pi Documentation: Skills (Progressive Disclosure). pi.dev/docs/latest/skills. Quote "only descriptions are always in context, full instructions load on-demand," verified against the source. ↩︎ ↩︎
Wąsowski, J. (2026). Managing Agent Context at Every Stage of the SDLC. Medium, April 2026. medium.com. Origin of context rot and the LSP pointers-over-copies mechanism; verified against the full text. ↩︎ ↩︎ ↩︎
Tool evidence. Serena (oraios), github.com/oraios/serena, exposes LSP operations (go-to-definition, find-references, rename) as symbol tools across 40+ languages. CodeGraph (colbymchenry), github.com/colbymchenry/codegraph, pre-indexed code knowledge graph via MCP (approximately 16% cheaper, approximately 58% fewer tool calls). Both READMEs and agent evals reviewed. ↩︎
Kim, M. et al. (2026). CODESTRUCT: Code Agents over Structured Action Spaces. arXiv:2604.05407. Named AST entities instead of text spans, 12 to 38 percent fewer tokens on SWE-Bench Verified; verified against the paper. ↩︎
Vogel, M. et al. (2026). Codebase-Memory: Tree-Sitter-Based Knowledge Graphs for LLM Code Exploration via MCP. arXiv:2603.27277. Tree-Sitter knowledge graph via MCP, tenfold fewer tokens across 31 repositories; verified against the paper. ↩︎
AWS (2026). The AWS MCP Server is now generally available. AWS News Blog, May 6, 2026. aws.amazon.com. Tool names (call_aws, search_documentation, read_documentation, run_script), the 15,000-API-operations count, and the Frankfurt region verified against the full text. ↩︎
Microsoft Azure Skills Plugin (March 2026). Primary source github.com/microsoft/azure-skills, verified against the README: 200+ structured tools, 40+ Azure services, and the named skills (azure-prepare, azure-validate, azure-deploy, azure-diagnostics, azure-cost). The press-cited figure "more than 19 skills" is from Ramel, D., Microsoft Launches Azure Skills Plugin, Visual Studio Magazine, March 13, 2026 visualstudiomagazine.com; the README gives no total count. ↩︎
Bos, W. & Tolinski, S. (2026). Pi: The AI Harness That Powers OpenClaw, with Armin Ronacher & Mario Zechner. Syntax Podcast #976, February 4, 2026. syntax.fm. Quotes "bash is all you need" and "it's not composable, everything has to go through the context of the LLM ... shell scripts ... are far superior to MCP" (Zechner); verified against the transcript. ↩︎ ↩︎ ↩︎ ↩︎
Fuller, B. (2026). CDLC: Context Development Life Cycle. bodenfuller.com. The 99% claim and the Select/Rank/Trim/Deliver phases verified against the source. ↩︎ ↩︎ ↩︎
Karpathy, A. (2025). Context Engineering. Attributed claim; Karpathy made the term prominent in 2025; first coinage is not unambiguously his. ↩︎ ↩︎
Chroma (2025). Context Rot: How Increasing Input Tokens Impacts LLM Performance. trychroma.com. 18 models, monotonically declining performance with input length; verified against the Chroma page. ↩︎ ↩︎
Google Research (2026). Towards a Science of Scaling Agent Systems: When and Why Agent Systems Work. research.google. The sixteen-tools mark appears there as an illustrative example of the coordination tax, not a measured threshold (verified against the source). ↩︎ ↩︎
Galster, M. et al. (2026). Configuring Agentic AI Coding Tools: An Exploratory Study. arXiv:2602.14690. arXiv. 2,853 GitHub repositories, eight configuration mechanisms; title, authors, and repository count verified against the abstract. ↩︎ ↩︎
Leverage AI tools to enhance coding efficiency, automate repetitive tasks, and unlock innovative development workflows.
When we published our HashiCorp Nomad and Vault: Dynamic Secrets post, the demo ran exclusively as a Python Flask application. Since then, the repository has
2,500 API endpoints. Expose every one of them as an MCP tool and you get, according to Cloudflare, 1.17 million tokens for tool definitions alone, before the
Every Nomad tutorial you will find online uses the docker driver. That makes sense — containers are portable, images bundle everything, and Docker is
In our previous post about HashiCorp Nomad and Vault: Dynamic Secrets we walked through the full lifecycle of secrets management for a Python Flask application
Over the last two weeks we introduced three mesh VPN solutions one at a time: NetBird, Tailscale, and Headscale. Three posts, three products, one open question:
You are interested in our courses or you simply have a question that needs answering? You can contact us at anytime! We will do our best to answer all your questions.
Contact us