

Local Hybrid Search: Retrieval Without a RAG Pipeline
Two weeks ago I wrote about what changes when you keep the model fixed and swap the harness. The short version: the wrapper matters more than people assume.

Update June 2026. I wrote this in March. Three months and several studies later, the thesis has held up but sharpened. Rather than writing a second article, I revised this one: "less context" was the right direction but the wrong word. The more precise framing is compiled, not dumped together. Where that distinction makes a difference, it's now in the text.
A few weeks back I started pruning our CLAUDE.md files. The reason: an agent kept making the same mistake, against a rule that was explicitly in the configuration. When a clear instruction fails to prevent the error, something is wrong with the approach. So I read through them. Three hundred lines. What struck me was how much of it described wishes rather than decisions. Wish-rules that no human reviewer would enforce if they did the code review themselves.
This pattern shows up constantly among people working with coding agents: the model makes a mistake, someone writes a rule against it, the next time the mistake happens anyway. The only thing that grew is the file. What held my attention wasn't the observation itself but the question underneath it, the one I wanted to chase systematically: why doesn't a rule take hold when it's sitting right there in plain text? Reaching for another rule feels like control. Understanding is slower but more durable. And it turns out the research has a fairly clear answer.
Two studies from this year describe the problem from different angles, and together they produce a clearer picture than either does on its own.
Gloaguen et al. from ETH Zurich examined how AGENTS.md files affect agent performance.1 Their finding is uncomfortable and can be compressed to one sentence: context files tend to lower success rates compared to giving the agent no repository context at all. Specifically, LLM-generated context files reduce success rates by around 3% and increase costs by over 20% through 14 to 22% more reasoning tokens. Not dramatic, but consistent, and pointing in the wrong direction.
The important part is in the detail: it matters who writes the file. Carefully hand-curated, small context files come out slightly positive in the ETH evaluation. LLM-generated files do more harm than good. This is not an argument against AGENTS.md. It's an argument against the reflexive version of it: generate a file first and hope.
At the same time: Lulla et al. measured the effect of AGENTS.md files in real pull requests.2 There the picture looks different. AGENTS.md reduced runtime by 28.6% and output token consumption by 16.6%. Same technology, opposite effect.
How do these fit together?
The resolution is in the purpose. Context files help with repo exploration: finding the build command, knowing the test convention, knowing which directory matters. They fail at instruction, meaning complex logic tasks that demand depth and reasoning. This is not an implementation flaw; it's structural. Repo exploration saves search effort. Instruction hits the reasoning budget.
That distinction is precisely what separates the two studies. In real PRs, the exploration component dominates. In benchmark tasks requiring deep reasoning, the instruction component dominates. Context files are a tool for repo exploration, not a substitute for reasoning.

Now it gets concrete. How many rules can a model handle before it starts degrading?
Jaroslawicz et al. measured this directly in the IFScale benchmark,3 across model generations from mid-2025 with systematically increasing rule counts. The results show three degradation patterns, by model class:
Threshold Decay (top reasoning models of the time, around o3 or Gemini 2.5 Pro): near-perfect compliance rates up to around 150 to 200 instructions, then rapid collapse. A capacity ceiling of sorts: robust performance below it, collapse above.
Linear Decay (the broad middle class, around GPT-4.1): steady performance loss with each additional instruction. No ceiling, no sudden collapse, but no stabilization either. Every new line costs something.
Exponential Decay (small models, around Haiku 3.5): fast degradation even at low rule density. What still works for large models overwhelms this class much earlier.
The specific models age quickly; the pattern does not. Each generation pushes the threshold higher, but the effect doesn't disappear. It's tied to the finite effective attention of a model, which degrades long before the context window is full.
There's a related phenomenon documented in the benchmark literature as Primacy Bias: instructions at the beginning of the system prompt get followed more reliably than those in the middle or at the end. Liu et al. documented the "Lost-in-the-Middle" pattern, a U-shaped attention curve: what sits at the beginning and end stays present (around 75% and 72% recall respectively), while what lands in the middle drops to around 55%.4
Here's the distinction I hadn't cleanly separated back in March. Lost-in-the-Middle is a spatial problem: where a token sits in the window. Alongside it sits a temporal one: Context Rot. The longer an agent works, the more its window fills with raw tool output, and the signal-to-noise ratio drops. Chroma measured this across 18 current models, and all 18 degrade well below their maximum window length.5 Two mechanisms, two different remedies: against the spatial problem, put less in the middle. Against the temporal one, start a fresh session earlier.

The practical consequence: every redundant rule displaces budget that a model needs for project-specific, genuinely critical instructions. A file with three hundred lines of generic best practices is not a safety net. It's noise drowning out signal.
Before going further: the most obvious objection to this argument goes like this. Better tooling solves the problem, not less context. Linters, formatters, CI gates, type checkers. Most of the "rules" in AGENTS.md files are things that could be automated. If the build command is make test, no language model needs that in a text file. It's in the Makefile.
This is a legitimate argument, and it's largely correct. If a rule can be tool-enforced, it belongs in tooling, not in context. That's not just more effective; it's more robust, because it doesn't depend on the attention capacity of a language model.
But tooling doesn't solve the problem completely. Architecture decisions, domain-specific conventions, the rationale behind deviations from defaults: these are things no linter carries. Context Engineering stays relevant precisely for those. The point is not "no context." The point is the right context, precisely formulated.
There's one benchmark finding that surprised me. Vercel engineer Gao ran an engineering eval comparing AGENTS.md files against dynamically loaded skills.6 A compressed 8KB index in AGENTS.md achieved a 100% success rate for Next.js 16 APIs. Dynamically loaded skills managed 79%. The implication: a precise, dedicated index beats generic capabilities, provided the index contains exactly the right thing and nothing else.
In March I derived three principles from this. Since then a fourth has emerged, and it's the most important.
Pointers, not copies. Context files should reference code via file:line, not embed it. "Look at this function, that's our pattern" is more precise than a thirty-line explanation of what the function should do. The agent can read the function. What it can't do is infer exact implementation expectations from a vague description. The same principle scales across skills: with Progressive Disclosure mechanics, only a short skill description stays permanently in the system prompt; the full content loads on demand. Across dozens of skills, that keeps permanent context lean instead of carrying every skill's full body, without losing any capability.7
Convention over Configuration. What the model already knows doesn't need to be explained. Ralf D. Müller coined the concept of "Semantic Anchors for LLMs," building on Peter Naur's "Programming as Theory Building" (1985): technical terms act as bridges between mental models and code generation.8 Chang et al. provided empirical support: precise technical terms activate specific weight patterns in the trained model.9 Writing "Terraform Module" activates a cluster complete with conventions, file paths, HCL syntax. Writing out those same conventions in an AGENTS.md file wastes instruction budget on something a single term already triggers.
Progressive Disclosure. Don't load everything upfront. What does the agent need for this task, right now? Deployment configuration is irrelevant when writing a unit test. Treat context as a resource, not a safety net. Patrick Debois formulated this as the CDLC, a Context Development Life Cycle of Generate, Evaluate, Distribute, Observe.10 Context as an evolving artifact, not a static config file. Tessl.io goes a step further and treats agent skills like software packages: versioned, evaluated, deliberately loaded. A Terraform Stacks skill went from 47% to 96% success rate that way according to Tessl's eval.11 Not more context; more precise, evaluated context.
Phase-Aware Compilation. This is the fourth, new principle, and it ties the other three together. Boden Fuller distinguishes a Prompt-Builder from a Context-Compiler: a Prompt-Builder strings text together. A Context-Compiler selects the right pieces, ranks them by utility and freshness, trims to the token budget, and delivers the minimally sufficient context for the current phase.12 The agent that's researching needs different context than the one implementing. Fuller's sharpest observation: exactly here lives 99% of the difference between teams that use AI coding agents and teams that get reliable results from them. This also flips my own March vocabulary. The lever is not less versus more. It's compiled versus dumped together. A randomly assembled context causes harm whether it's large or small.

Why does precise context actually work? There's an information-theoretic reading, and it's tempting enough that I don't want to overstretch it.
At the token level, the case is solid. Sorensen et al. select from a set of prompt templates the one that maximizes Mutual Information (the statistical relationship between input and output), without labeled examples and without access to the weights. High Mutual Information correlates with high accuracy, and the method reaches "90% of the way from average to best prompt accuracy."13 Add the theorem from Delétang et al.: language modeling is compression; prediction and compression are the same thing.14 Both support the intuition that choosing the right context is a form of entropy reduction.
The compression theorem says how long the encoding is given a context. It does not say which context is optimal or minimal. The leap from "modeling is compression" to "context selection is compression" is an interpretation, not a proof. And there's a concrete counterforce: low entropy is not the same as correctness. A sharp, confident distribution can collapse onto the wrong answer, whether through miscalibration from training on human feedback or through sycophancy (the model's tendency to tell users what they want to hear). At the level of agent actions, where the question is whether better context actually lowers error rates at runtime, a clean controlled test is still missing. My current position: at the token and template level, the thesis is supported; at the agent level, it's an open question. I use it as a compass, not a law of nature.
Wortmann proposed a simple heuristic for evaluating rules.15 Four questions per rule:
Rules that answer none of these with yes are aspirations. They belong in the team wiki, not in the AGENTS.md.
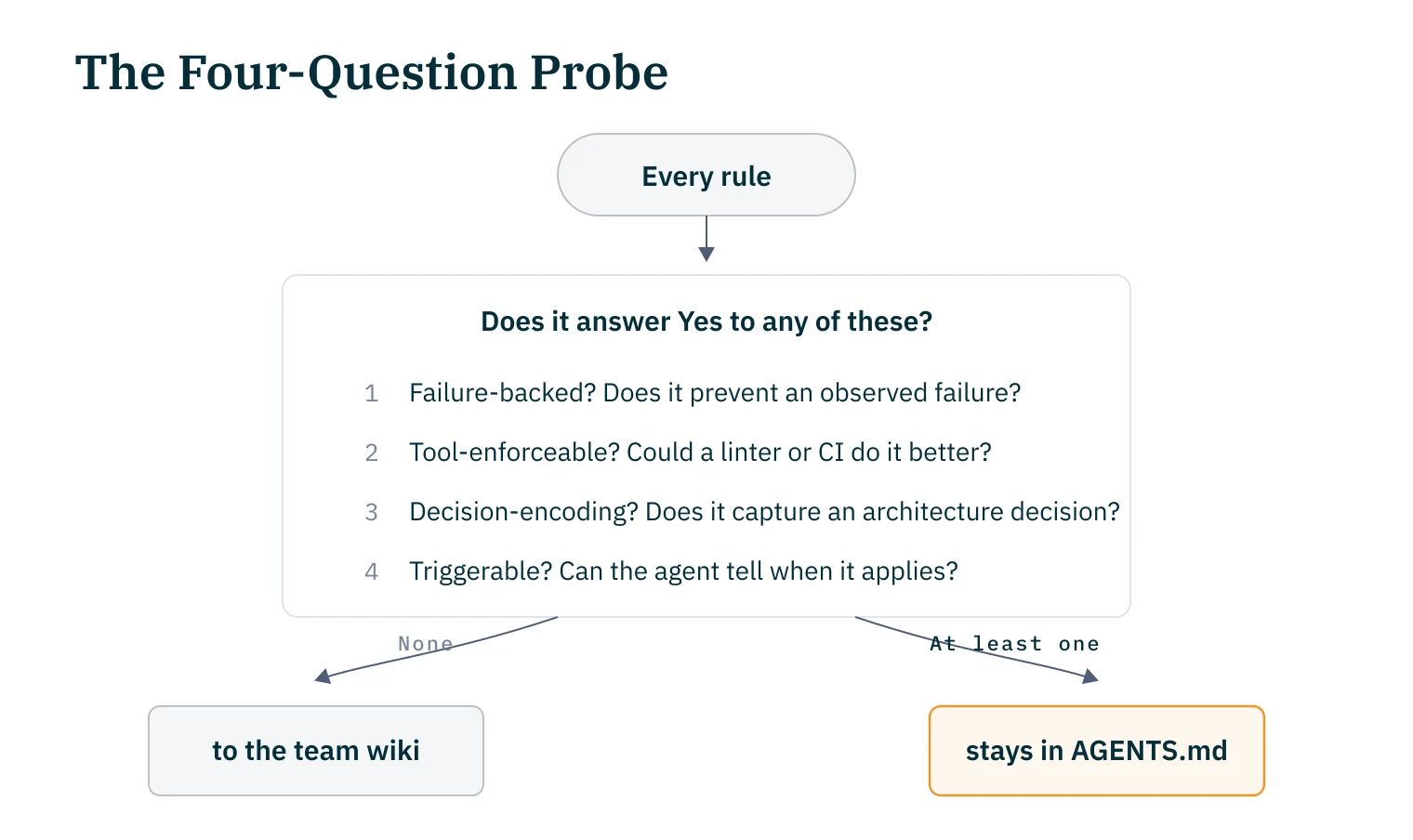
Whether this heuristic scales to all projects is an open question, and the Information Bottleneck model provides the formal language for "minimally sufficient context" but no practical criterion yet. What I observe: the questions create useful friction. Running through them as a team surfaces at least thirty percent of rules that don't prevent anything concrete.
There's a term that's been stuck in my head since spring, and it comes from Jarosław Wąsowski: Context Debt. Technical debt accumulates when a developer cuts corners. Context Debt accumulates while the developer sleeps, because the agent keeps working.5
Wąsowski's example lands. Friday, 5:23 PM. An agent works for 35 minutes on a refactoring. A grep returns eight hits; the agent edits the fourth; the diff looks good; review takes seven minutes; deployment is clean. At 2:14 AM the production alert fires: invoices aren't being generated for new customers. The right file wasn't the fourth one, it was the second. Hit four sat in the dead zone in the middle of a long list, and after 35 minutes the window was 60% filled with raw tool output. No model bug. Context Debt that materialized as broken code.
That's the distinction that first made the urgency of this whole thing clear to me: with code, debt is visible, in the build, in the test, in the review. With context, it's silent. No compiler, no linter, no reviewer fires. The code passes review precisely because it looks plausible. That's why cleaning up the AGENTS.md once is not enough. It keeps aging without warning signals.
Context Engineering will become the new DevOps discipline, with the same maturity curve that Infrastructure as Code once needed. Configuration files eventually got versioned, tested, reviewed. AGENTS.md files today: mostly a single commit that grows whenever something breaks.
That will change because teams that treat context files like code are getting measurably better results. Patrick Debois describes the dynamic as a Flywheel: better context produces better agent outputs; better outputs produce better signals; better signals produce better context.10 The loop reinforces itself. His unglamorous addition: if nobody owns the context, it rots. Ownership is the precondition for the flywheel to spin at all.
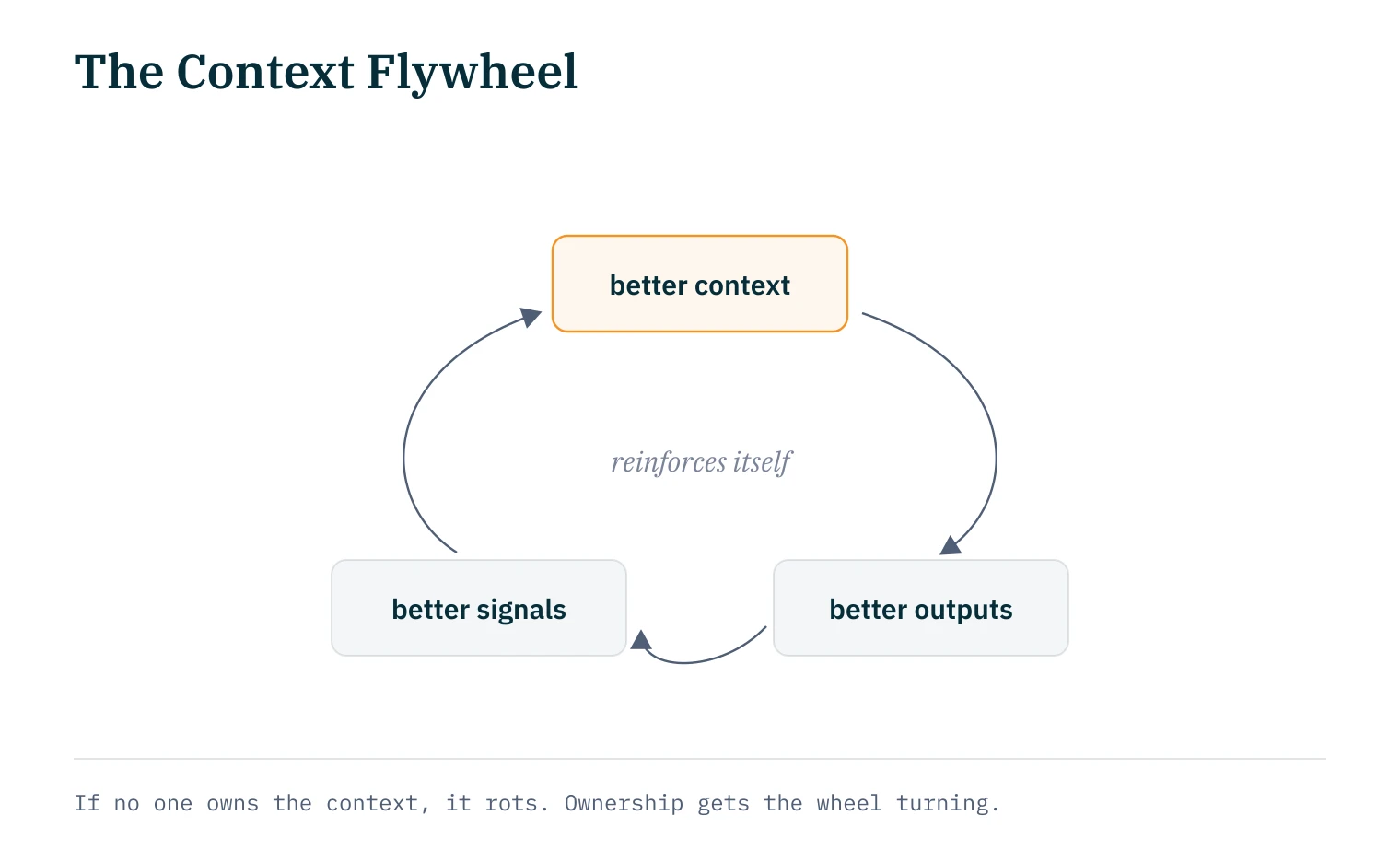
That's where the actual competitive advantage sits. Models are becoming a commodity; everyone has access to the same foundation models. Tools are converging; the skill format gets adopted across the ecosystem within weeks. What remains is the context accumulated and maintained over years. Two companies with identical tooling: one that has run disciplined context files with eval pipelines for two years, another starting today. That lead isn't something you can buy your way into.
Three concrete steps, actionable right now:
Context Audit. Run every rule in the AGENTS.md through the Four-Question Probe. Not as a critique, as hygiene. The goal isn't brevity for its own sake; it's precision.
Tooling Transfer. Everything that can be tool-enforced comes out of context and into tooling. Linting, formatting, build commands, test conventions. That frees up the reasoning budget for what only context can do.
Failure Log. Keep a table: when did the agent break a rule? What was the actual consequence? Rules with no entries in that table are deletion candidates.
Patrick Debois has a question that exposes maturity in a single sentence: you've invested in agents, models, tools, and infrastructure. What have you invested in the context that makes all of it actually work? If you don't have an answer, now you know where to start.
This post is part of a series on AI and software architecture. Earlier pieces cover the Five Stages of AI Development, Dark Factory Architecture, the Dark Factory Gap, Conway's AI Inverse, and Harness Engineering.
The core thesis, Context Engineering as minimal, precise injection, grew out of direct work with our own CLAUDE.md files. The research on AGENTS.md was new enough at the start of 2026 that I needed to work through the sources and cross-check the findings: Gloaguen et al. (ETH Zurich) and Lulla et al. produce apparently contradictory results that only resolve through the distinction between repo exploration and instruction. That wasn't a preset thesis; it came from the comparison. The IFScale study (Jaroslawicz et al.) was verified against the arXiv abstract. The Vercel benchmark (Gao) is an engineering blog post, not a peer-reviewed paper, and appears here as an attributed claim, not a verified experiment.
The June revision adds material that only existed since spring. The Context-Compiler framing (Boden Fuller) and Context Debt (Jarosław Wąsowski) are treated as attributed claims from engineering blogs. The information-theoretic grounding rests on two primary sources, Sorensen et al. (Mutual-Information prompt selection) and Delétang et al. (Language Modeling Is Compression); those claims were checked against the sources. The leap from the token level to the agent level is deliberately left open: no clean controlled test exists for that, and the text says so. Claude was used for structuring and phrasing suggestions. All numbers, source attributions, and the core argument were manually verified. I describe the full workflow in AI-Assisted Knowledge Work: How I Am Rebuilding My Research and Writing Process.
Gloaguen, R. et al. (ETH Zürich) (2026). Evaluating AGENTS.md: How Context Files Affect LLM Agent Performance. arXiv:2602.11988. arXiv ↩︎
Lulla, A. et al. (2026). On the Impact of AGENTS.md Files on AI-Assisted Software Development. arXiv:2601.20404. arXiv ↩︎
Jaroslawicz, D. et al. (2025). How Many Instructions Can LLMs Follow at Once? The IFScale Benchmark. arXiv:2507.11538. arXiv ↩︎
Liu, N. F. et al. (2023). Lost in the Middle: How Language Models Use Long Contexts. arXiv:2307.03172. arXiv ↩︎
Wąsowski, J. (2026). Managing Agent Context at Every Stage of the SDLC. Medium, attributed statement: originator of the term "Context Debt"; the Friday-5:23-PM example and the Lost-in-the-Middle vs. Context Rot distinction come from there. Context Rot figures across 18 models: Chroma (2025), Context Rot Report. ↩︎ ↩︎
Gao, J. (Vercel) (2026). AGENTS.md outperforms skills in our agent evals. Vercel Engineering Blog. vercel.com ↩︎
Progressive Disclosure is a mechanic of the Agent Skills standard (Anthropic, 2025); pi implements it and phrases it crisply: pi.dev: "only descriptions are always in context, full instructions load on-demand." Related: Pocock, M., How To Make Codebases AI Agents Love (progressive disclosure of complexity on Deep-Module interfaces). ↩︎
Müller, R. D. (2025). Semantic Anchors for LLMs. Project site and talks. Building on Naur, P. (1985). Programming as Theory Building. ↩︎
Chang, E. Y. et al. (2025). Semantic Anchoring in LLMs: Thresholds, Transfer, and Geometric Correlates. arXiv:2506.02139. ICLR 2026 submission. arXiv ↩︎
Debois, P. (2026). The Context Flywheel. jedi.be. jedi.be ↩︎ ↩︎
Zhang, Q. et al. (2026). Agentic Context Engineering (ACE). arXiv:2510.04618. ICLR 2026. arXiv as conceptual framework. The 47%→96% figure (factor 2.04) for the Terraform Stacks skill is a Tessl.io eval claim, an attributed statement not from the ACE paper. ↩︎
Fuller, B. (2026). The Context Development Life Cycle. Engineering blog, attributed statement: "a context compiler selects the right pieces, ranks them by utility and freshness, trims to the token budget". ↩︎
Sorensen, T. et al. (2022). An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels. arXiv:2203.11364. arXiv ↩︎
Delétang, G. et al. (2024). Language Modeling Is Compression. arXiv:2309.10668. arXiv ↩︎
Wortmann, J.-N. (2026). Agent Instructions: The Failure-Backed Rubric. wordman.dev. wordman.dev ↩︎
Leverage AI tools to enhance coding efficiency, automate repetitive tasks, and unlock innovative development workflows.
Transform your engineering workflows with hands-on AI: Deploy LLMs, automate infrastructure, and master the latest tools and protocols.
Two weeks ago I wrote about what changes when you keep the model fixed and swap the harness. The short version: the wrapper matters more than people assume.
I ran the same coding task through four AI coding tools this week - opencode, Pi, GitHub Copilot in VS Code, and Claude Code - all driven by the same local
If you already run Nomad + Vault patterns in production, the first question about OpenBao is simple: will our existing workloads still run without a rewrite? In
When we published our HashiCorp Nomad and Vault: Dynamic Secrets post, the demo ran exclusively as a Python Flask application. Since then, the repository has
The previous article, Tool-Surface Compression, was about getting external functionality, entire APIs and systems, into the agent as token-efficiently as
You are interested in our courses or you simply have a question that needs answering? You can contact us at anytime! We will do our best to answer all your questions.
Contact us