

HashiCorp Nomad and Vault with .NET: ASP.NET Core in a Secure Workload
When we published our HashiCorp Nomad and Vault: Dynamic Secrets post, the demo ran exclusively as a Python Flask application. Since then, the repository has

The current debate around Claude Code and Open Code is mostly told as a pricing dispute: Anthropic locked third-party apps out of the subsidized subscription channel, the developer community is furious, and everyone is running the math on whether API pricing makes the new tool affordable at all. That's a real conflict — but it's pulling attention away from the story that actually matters.

The story is this: the industrial break in AI coding didn't come from a model upgrade. It came from a shift in form factor. And that shift has changed the developer workflow so fundamentally that the model — Opus 4.5 vs. GPT 5.2 Codex vs. open alternatives like GLM 4.7 or Minimax M2.1 (as of January 2026) — is secondary for most teams.
I'm making that claim on the basis of four years of observable trajectory, plus a growing body of research that supplies the data points and, just as usefully, shows where the picture still has gaps.
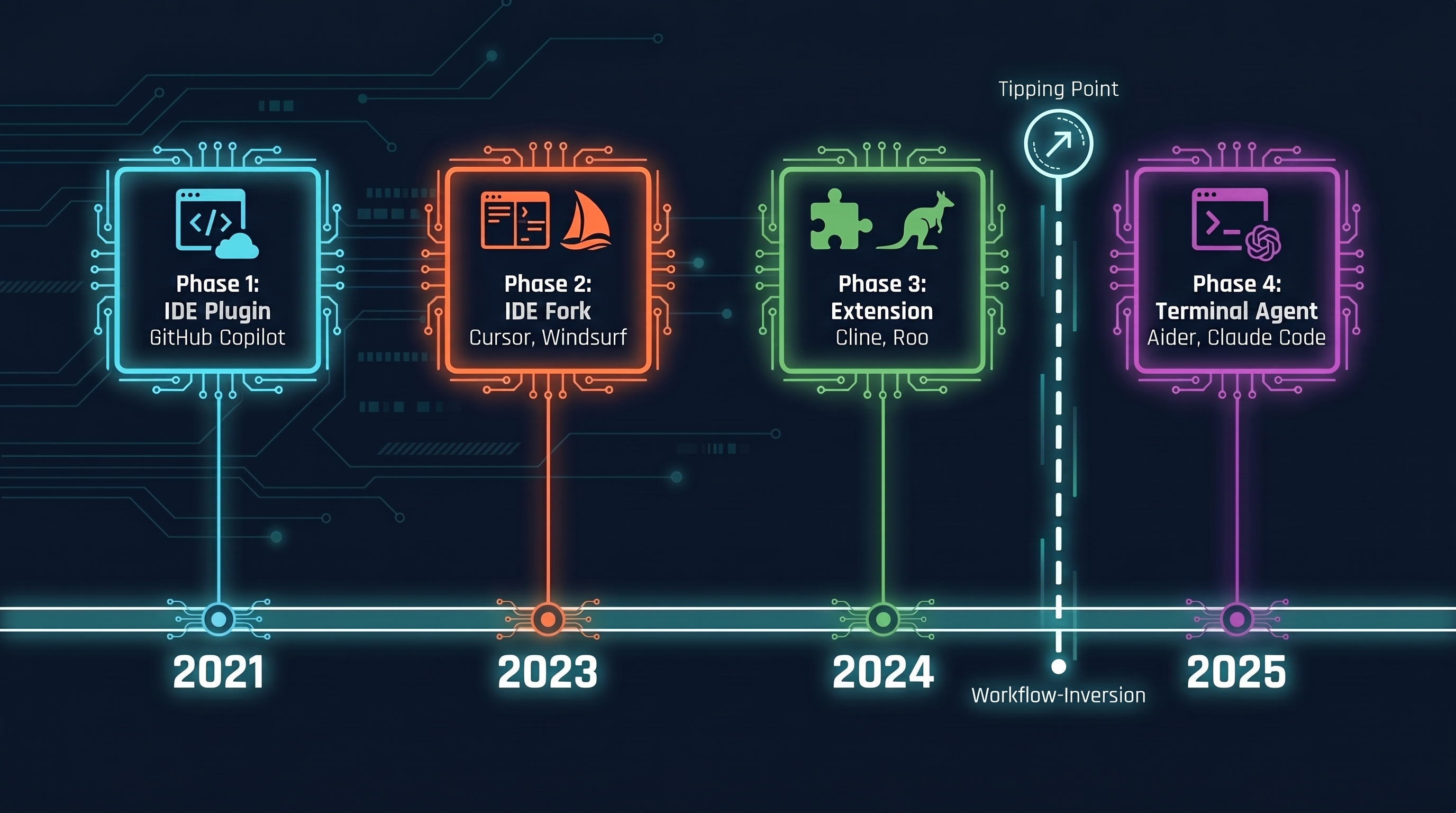
If you started using GitHub Copilot in 2021, you got a useful tool.1 Not a workflow change. Just a faster typist. The developer still did everything; Copilot helped at the last step: cursor blinks, suggestion appears, Tab or Esc. That was Phase 1 — IDE plugin, AI assists at the final input stage, human remains both conductor and performer.
Phase 2 came with Cursor and Windsurf, IDE forks that moved the developer one layer up the stack for the first time. Instead of typing lines, you write prompts and the model completes them. Business requirement → prompt → AI completes. It sounds similar, but it feels different: the developer is delegating for the first time rather than just accelerating. Extensions like Cline and Roo (Phase 3) brought the same delegation idea into a lighter setup without an IDE fork — turn-by-turn, but still inside the familiar development environment.
Phase 4 is the actual tipping point. Aider was one of the first prominent tools to pull AI out of the IDE entirely and run it as a standalone terminal process. The IDE is no longer the center. It becomes an observation surface. My thesis: Claude Code didn't displace Aider primarily through a better model, but through approachability and deep MCP integration. The tool felt accessible to non-power-users from day one, and the MCP tooling opened up its own platform logic.
What exactly happens at this tipping point? The work inverts. Through Phase 3, the tool adapts to the developer's workflow: the human is the stable variable, the tool is what changes. Starting with Phase 4, the developer begins adapting their own work to the tool. Someone using Claude Code seriously no longer thinks in modules and tasks — they think in projects and handoffs. They write CLAUDE.md files to make implicit knowledge explicit. They structure their repo conventions so the agent can navigate cleanly.
That's not a minor adjustment. That's an inversion.
The productivity narrative around AI coding has real numbers behind it, but almost exclusively for the early form-factor phases.
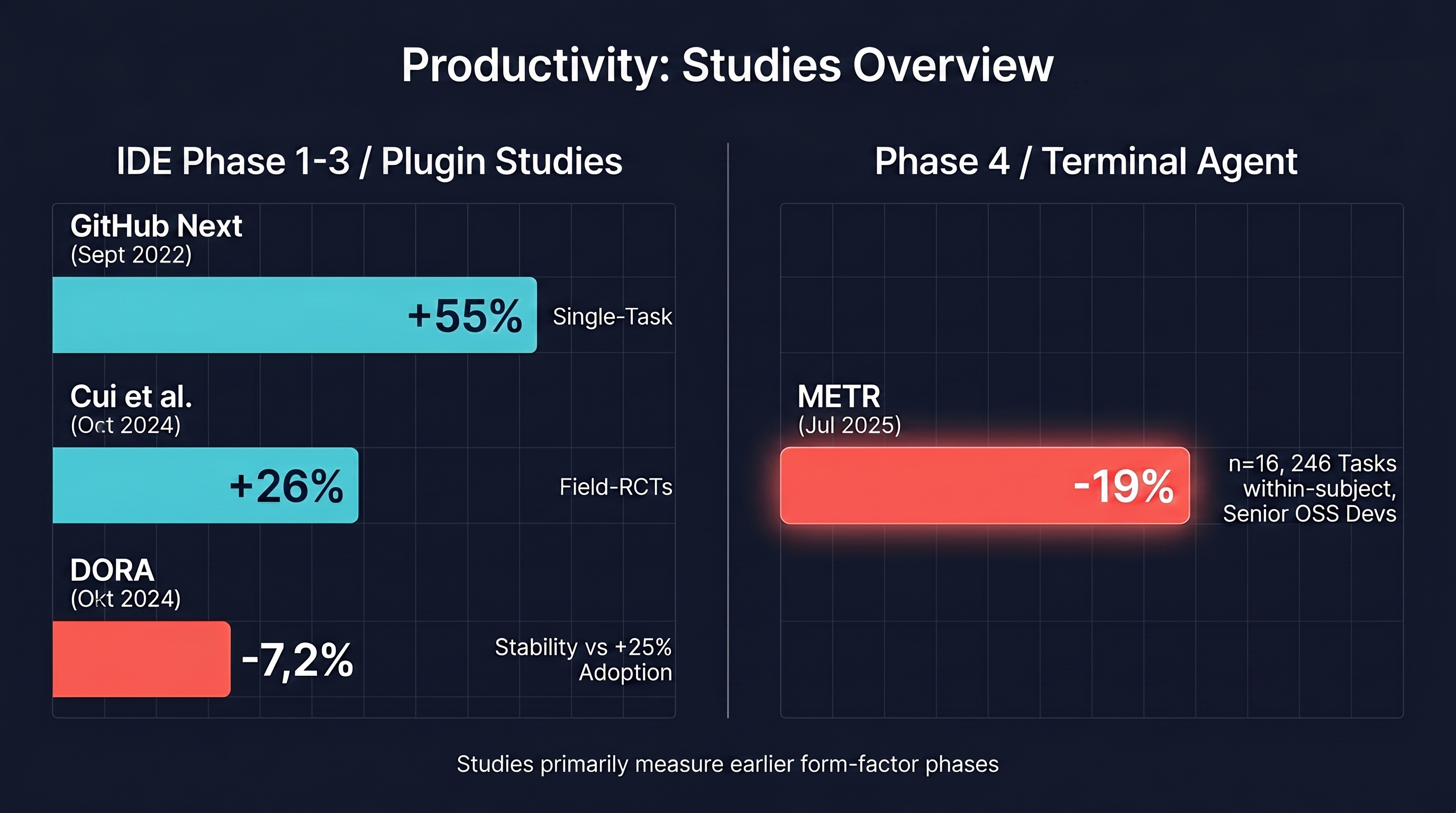
The most-cited data point comes from the GitHub Next experiment by Kalliamvakou et al. (2022): developers using Copilot completed a defined task (an HTTP server in JavaScript) 55% faster than the control group — 71 minutes versus 161 minutes.1 73% reported feeling "in the flow." That sounds impressive until you read the conditions: a single task, individual developers, high self-report component. Ecological validity is limited.
Cui, Demirer et al. (2024) supplied field data from three real enterprise settings — Microsoft, Accenture, and a Fortune 100 company — with 4,867 developers.2 Result: roughly 26% more completed tasks per week, measured against actual Git PR throughput, not self-reports. Stronger for junior developers (27–39%), weak or insignificant for seniors. That's robust, but again: most participants were working with IDE assistance, meaning Phases 1 through 3.
DORA 2024 then brings the nuance that never appears in vendor announcements: 75% of surveyed developers use AI for at least one task. And every 25% increase in AI adoption correlates with roughly 1.5% less delivery throughput and around 7.2% less delivery stability, at least across the full breadth of teams.3 39% of respondents trust AI output only moderately. DORA 2025 confirms the trend: more than 90% of developers use AI in their workflow, a median of roughly two hours per day.4 The stability trade-off remains visible, but seven team practices within an "AI Capability Model" can partially offset it.
And then there's the METR study from early 2025, which I treat as an anti-hype anchor for serious conversations: sixteen experienced open-source maintainers, AI-assisted with Cursor plus Claude 3.5/3.7 (the models available at study time, early 2025), measured across 246 real repository tasks, within-subject — each developer served as their own control.5 Result: 19% slower than without AI. Subjective estimate: 20% faster. Experienced developers believed they were faster; they measurably weren't. Important context: n=16 is a small sample, and the authors themselves describe their statistical power as "barely adequate." This is a data point with caveats, not a final verdict — but the caveat is too clear to ignore when making the internal case for AI coding adoption.
None of this is an argument against AI coding. It's an argument for taking the form-factor phase seriously. IDE plugin studies measure code completion acceptance in a workflow the developer controls. Terminal agents change the fundamental structure of the workflow. That senior devs slow down with Phase 1–3 tools isn't surprising: the cognitive overhead of "AI babysitting" eats the speed gain. Phase 4 tools with a clean plan step, diff review, and clear task separation bring structurally different conditions. But that's not yet measured robustly, and that's the honest gap.
The point that gets too little attention in the public debate is this: Claude Code enforces a documentation discipline that was previously voluntary — and therefore often absent.
CLAUDE.md files and skills (each with a SKILL.md in the skill directory) are not nice-to-haves. They are the mechanism through which implicit team knowledge — "our Terraform state has this structure," "API keys come from Vault, never from .env," "the build system has this specific workaround because of a 2023 Go bug" — gets converted into explicit, agent-readable form. Context engineering in the direct sense: giving the system the right context at runtime, not as an afterthought, but as infrastructure.6
What I observe in teams that take this seriously: the first pain is writing the files. That's tedious, because no one enjoys documenting what they consider obvious. The second pain is discovering how much knowledge was never written down anywhere. The third pain — the surprising one — is that this now has consequences, because the agent does exactly what the documentation says, not what the developers silently knew.
This forced externalization isn't a bug. It's the actual industrial lever, one that goes well beyond AI productivity: teams that treat CLAUDE.md seriously incidentally make onboarding faster, handoffs safer, and bus factor smaller. AI is the catalyst for something that would have been worth doing all along.
Now to the debate that prompted this post.
Anthropic restricted use of the subsidized Claude subscription through third-party tools — most extensively documented for OpenClaw and general third-party CLI wrappers, and discussed in the industry context of Open Code as well. Anyone wanting to use the same Anthropic model through such tools falls back on API pricing, which is substantially more expensive. From the discourse in forums, YouTube videos, and blog posts, I read two interpretations: legitimate platform strategy within Anthropic's rights, or a sign that Anthropic is actively protecting the application layer against third parties.
That's a fair description of the tension. Steelmanning the opposing view: Anthropic subsidizes Claude.ai subscriptions because a direct customer relationship matters more to a frontier AI lab long-term than platform openness. That's not malice, it's platform strategy. Anyone who watched AWS, Apple, and Google over the last decade knows the pattern.
The more interesting question underneath it: what is the actual edge in the application layer, when model quality is becoming increasingly comparable? Open Code is positioned in the community as an equivalent alternative — comparable depth, MCP tools, free models out of the box. I'm genuinely uncertain what the direct feature comparison looks like in practice, because no reliable independent benchmarks exist yet. What I can say with confidence: competitive pressure in the application layer is real and intense. When model quality becomes a commodity, what decides is approachability, tooling integration, and yes — the pricing channel.
2026 could be the consolidation year. A recurring thesis in industry discourse: many LLM wrappers won't survive because the differentiation space is too narrow. That strikes me as plausible, but I wouldn't state it as certainty — too many variables, too fast a pace of model development.
I've been using Claude Code as my primary tool for several months, for anything beyond single-file changes. My honest assessment: the Phase 4 shift costs more than it gives at the start. The first two weeks are slower — not because the tool is bad, but because you're learning how to structure tasks so the agent can handle them cleanly. That's the J-curve effect in practice: getting worse before getting better.
What convinces me it's worth it is not speed on individual tasks. For that, Phase 2 or 3 was often sufficient. It's the ability to scale across a full project: tasks that previously fell apart because no single person could hold the complete context in their head become manageable when the context lives in files and the agent can retrieve it at any point.
Whether this is immediately the right move for every mid-market CTO or DevOps lead — I'd be careful with a blanket recommendation. Teams with a strong documentation culture have a clear head start. Teams that still run on oral tradition have to manage two changes at once: the tool and the culture.
That's not a warning against the tool. It's a warning against the myth that Phase 4 is automatically faster and better. The METR finding for experienced senior developers should give pause to anyone making the internal case for adoption.
If you're starting now or planning the next step, keep the tool choice and the team-readiness question separate:
For teams in Phase 1–2 (Copilot, Cursor): The productivity baseline is there, and the studies support the gains. Before Phase 4 makes sense, an honest inventory is worthwhile: how much project knowledge lives in documents, how much in people's heads? If the answer is "mostly heads," CLAUDE.md discipline is a more valuable next step than the next tool.
For teams evaluating Phase 4: Run a pilot on a clearly scoped project that meets three conditions: solid existing documentation, tolerable cost of failure, active review culture. Diff review in Phase 4 is not optional. The agent writes code at a pace where accepting output blindly is a security risk.
On the Open Code vs. Claude Code question: if the primary model is Anthropic and cost is a real factor, the feature comparison between Claude Code and Open Code is worth a serious look. I wouldn't make that call right now without independent benchmarks providing more clarity. What I wouldn't recommend: making a tool switch primarily on the basis of the pricing debate without first settling the workflow question — phase and readiness.
The model question — Opus 4.5 vs. GPT 5.2 Codex vs. open alternatives, as of January 2026 — is secondary for the vast majority of teams. The OpenAI-Cerebras partnership could push inference speed into four-digit tokens per second, and there's speculation that three fast iterations might then outperform a single slower one. Interesting. Whether tokens per second is the decisive lever — versus harness quality and context engineering — remains open.
My assessment: the edge, medium-term, is not in the model, not in the tool name, but in how well a team learns to work with the terminal agent. And that requires getting implicit knowledge explicit first.
Starting points were the discussions around Claude Code, Open Code, and the form-factor shift in AI coding — spread across YouTube videos, blog posts, and forum threads in January 2026. I cross-checked the structural observations (four-phase model, workflow inversion, wrapper consolidation thesis) against the research I know well: GitHub Next and METR from primary sources, DORA from the official Google reports, Cui/Demirer from the SSRN preprint.
Writing process: a first draft with Claude Sonnet 4.5, from a structured outline. Where I hedge carefully, where I take a clear position, how the argument builds, where I work through the counterargument seriously — those decisions went through manual revision. Not because the draft was wrong, but because these choices have to develop in my head, not be prefabricated by a model.
The English adaptation was written as a rewrite, not a translation — same argument and evidence, reframed for an international audience. The full workflow behind this approach (and the German original) is described in AI-Assisted Knowledge Work.
Kalliamvakou, E. et al. (2022). Research: quantifying GitHub Copilot's impact on developer productivity and happiness. GitHub Next. GitHub Blog ↩︎ ↩︎
Cui, Z., Demirer, M., Jaffe, S., Musolff, L., Peng, S., Salz, T. (2024/2025). The Effects of Generative AI on High-Skilled Work: Evidence from Three Field Experiments with Software Developers. SSRN Preprint (revised 2025), later journal version in Management Science (2026). SSRN / Management Science ↩︎
Google Cloud (2024). Accelerate State of DevOps Report 2024. DORA. Google Cloud ↩︎
Google Cloud (2025). State of AI-assisted Software Development 2025. DORA. Google Cloud ↩︎
METR (2025). Early 2025 AI Experienced OS Dev Study. METR Blog / arXiv:2507.09089 ↩︎
Lütke, T. (June 2025). X/Twitter — Shopify CEO Tobi Lütke introduced the term "Context Engineering" on June 19, 2025 as an alternative to "Prompt Engineering." Six days later, on June 25, 2025, Karpathy endorsed it and popularized it with the definition "the delicate art and science of filling the context window": Karpathy on X. ↩︎
When we published our HashiCorp Nomad and Vault: Dynamic Secrets post, the demo ran exclusively as a Python Flask application. Since then, the repository has
2,500 API endpoints. Expose every one of them as an MCP tool and you get, according to Cloudflare, 1.17 million tokens for tool definitions alone, before the
Every Nomad tutorial you will find online uses the docker driver. That makes sense — containers are portable, images bundle everything, and Docker is
In our previous post about HashiCorp Nomad and Vault: Dynamic Secrets we walked through the full lifecycle of secrets management for a Python Flask application
Over the last two weeks we introduced three mesh VPN solutions one at a time: NetBird, Tailscale, and Headscale. Three posts, three products, one open question:
You are interested in our courses or you simply have a question that needs answering? You can contact us at anytime! We will do our best to answer all your questions.
Contact us